Spark Streaming实时计算框架学习01
Posted 房东地猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming实时计算框架学习01相关的知识,希望对你有一定的参考价值。
文章目录
初探Spark Streaming
从hadoop102的8888端口接受一行或者多行文本内容,并对接收到的内容以空格分隔计算每个单词出现的次数
package Spark_Streaming
import org.apache.log4j.Level,Logger
import org.apache.spark.SparkContext,SparkConf
import org.apache.spark.streaming._
object demo01
def main(args: Array[String]): Unit =
//设置日志级别
Logger.getLogger("org").setLevel(Level.ERROR)
val conf=new SparkConf().setAppName("demo01").setMaster("local[2]")
val sc=new SparkContext(conf)
//从SparkConf创建SteamingContext并指定10s的批处理大小
val ssc=new StreamingContext(sc,Seconds(10))
//启动连接到hadoop102 8888端口上,使用收到的数据创建DAtream
val lines=ssc.socketTextStream("hadoop102",8888)
val words=lines.flatMap(_.split(" "))
val wordCounts=words.map(x=>(x,1)).reduceByKey(_+_)
wordCounts.print()
//启动流计算环境StreamingContext
ssc.start()
ssc.awaitTermination()


监听hadoop102 HDFS目录/opt/datafiles,一旦有新文件加入到此目录,Spark
Streaming会计算出该时间内的单词统计数
package Spark_Streaming
import org.apache.log4j.Level,Logger
import org.apache.spark.SparkContext,SparkConf
import org.apache.spark.streaming._
object demo02
def main(args: Array[String]): Unit =
//设置日志级别
Logger.getLogger("org").setLevel(Level.ERROR)
val conf=new SparkConf().setAppName("demo02").setMaster("local[2]")
val sc=new SparkContext(conf)
//从SparkConf创建SteamingContext并指定10s的批处理大小
val ssc=new StreamingContext(sc,Seconds(10))
//启动连接到hadoop102 hdfs目录/opt/datafiles上
val lines=ssc.textFileStream("hdfs://hadoop102:8020/opt/datafiles")
val words=lines.flatMap(_.split(" "))
val wordCounts=words.map(x=>(x,1)).reduceByKey(_+_)
wordCounts.print()
//启动流计算环境StreamingContext
ssc.start()
ssc.awaitTermination()


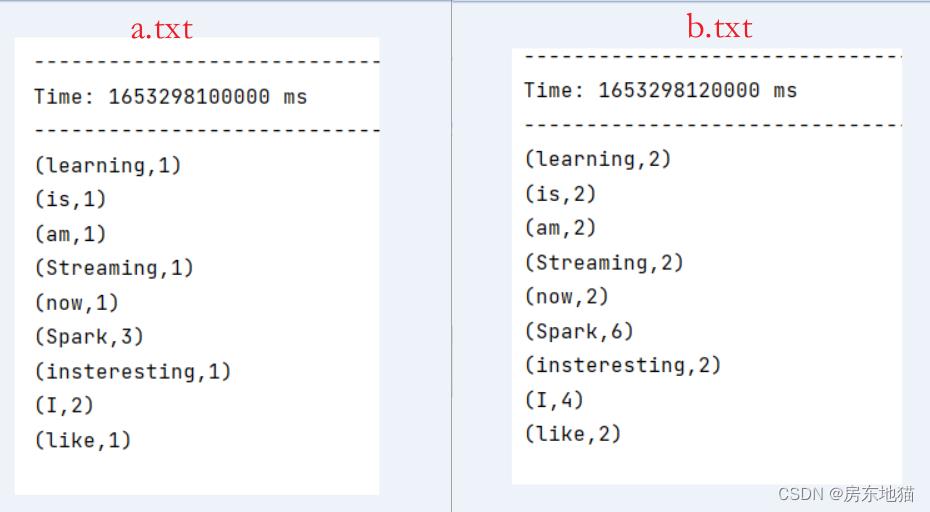
掌握DStream编程模型
DStream转换操作
使用transform将一行语句分割成单词
package Spark_Streaming
import org.apache.log4j.Level,Logger
import org.apache.spark.SparkContext,SparkConf
import org.apache.spark.streaming._
object demo03
def main(args: Array[String]): Unit =
//设置日志级别
Logger.getLogger("org").setLevel(Level.ERROR)
val conf=new SparkConf().setAppName("demo03").setMaster("local[2]")
val sc=new SparkContext(conf)
//从SparkConf创建SteamingContext并指定10s的批处理大小
val ssc=new StreamingContext(sc,Seconds(10))
//启动连接到hadoop102 8888端口上
val lines=ssc.socketTextStream("hadoop102",8888)
val words=lines.transform(rdd=>rdd.flatMap(_.split(" ")))
words.print()
//启动流计算环境StreamingContext
ssc.start()
ssc.awaitTermination()


DStream窗口操作
window操作是基于一个源DStream的窗口批次计算后得到新的DStream。
例如设置窗口长度为3s,滑动时间间隔为1s。截取源DStream中的元素形成新的DStream。
package Spark_Streaming
import org.apache.log4j.Level,Logger
import org.apache.spark.SparkContext,SparkConf
import org.apache.spark.streaming._
object demo04
def main(args: Array[String]): Unit =
//设置日志级别
Logger.getLogger("org").setLevel(Level.ERROR)
val conf=new SparkConf().setAppName("demo04").setMaster("local[2]")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(1))
val lines=ssc.socketTextStream("localhost",8888)
val words=lines.flatMap(_.split(" "))
val windowWords=words.window(Seconds(3),Seconds(1))
windowWords.print()
//启动流计算环境StreamingContext
ssc.start()
ssc.awaitTermination()
基本每秒输入一个字母,取出当前时刻3s这个长度中的所有元素,打印出来。第4s时已经看不到a了,说明a已经不在当前窗口中

DStream输出操作
package Spark_Streaming
import org.apache.log4j.Level,Logger
import org.apache.spark.streaming.Seconds,StreamingContext
import org.apache.spark.SparkContext,SparkConf
object demo06
def main(args: Array[String]): Unit =
//设置日志级别
Logger.getLogger("org").setLevel(Level.ERROR)
val conf=new SparkConf().setAppName("demo06").setMaster("local[2]")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(10))
val lines=ssc.socketTextStream("hadoop102",8888)
lines.saveAsTextFiles("hdfs://hadoop102:8020/opt/datafiles/sahf","txt")
ssc.start()
ssc.awaitTermination()
如果报错显示权限不足无法写入
执行
hdfs dfs -chmod a+w /opt/datafiles
[xwk@hadoop102 ~]$ nc -l -p 8888
this is 1th line
this is 2th line
this is 3th line
this is 4 th line

4行文本分别保存在前4个目录中
使用foreachPartition,将处理结果写到mysql数据库中
mysql> create database spark;
Query OK, 1 row affected (0.07 sec)
mysql> use spark;
Database changed
mysql> create table searchKeyWord(insert_time date,keyword varchar(30),search_count integer);
Query OK, 0 rows affected (0.66 sec)
设置窗口长度为60s,窗口滑动时间间隔10s,计算10s内每个单词出现的次数,根据出现的次数对单词进行降序排序
package Spark_Streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import java.sql.DriverManager
import org.apache.log4j.Level, Logger
object demo07
def main(args: Array[String]): Unit =
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf().setMaster("local[3]").setAppName("WriteDataToMySQL")
val ssc = new StreamingContext(conf, Seconds(5))
val ItemsStream = ssc.socketTextStream("hadoop102", 8888)
val ItemPairs = ItemsStream.map(line => (line.split(",")(0), 1))
val ItemCount = ItemPairs.reduceByKeyAndWindow((v1:Int,v2:Int)=>v1+v2,Seconds (60),Seconds(10))
val hottestWord = ItemCount.transform(itemRDD =>
val top3 = itemRDD.map(pair => (pair._2, pair._1)).sortByKey(false).map(pair => (pair._2, pair._1)).take(3)
ssc.sparkContext.makeRDD(top3)
)
hottestWord.foreachRDD(rdd =>
rdd.foreachPartition(partitionOfRecords =>
val url = "jdbc:mysql://hadoop102:3306/spark"
val user = "root"
val password = "root"
Class.forName("com.mysql.cj.jdbc.Driver")
val conn = DriverManager.getConnection(url, user, password)
conn.prepareStatement("delete from searchKeyWord where 1=1").executeUpdate()
conn.setAutoCommit(false)
val stmt = conn.createStatement()
partitionOfRecords.foreach(record =>
stmt.addBatch("insert into searchKeyWord (insert_time,keyword,search_count) values (now(),'" + record._1 + "','" + record._2 + "')")
)
stmt.executeBatch()
conn.commit()
)
)
ItemsStream.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
nc -l -p 8888
select * from searchKeyWord;
以上是关于Spark Streaming实时计算框架学习01的主要内容,如果未能解决你的问题,请参考以下文章