DQN笔记:高估问题 & target network & Double DQN
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DQN笔记:高估问题 & target network & Double DQN相关的知识,希望对你有一定的参考价值。
- Q 学习算法有一个缺陷:用 Q 学习训练出的 DQN 会高估真实的价值,而且高估通常是非均匀的。
- 这个缺陷导致 DQN 的表现很差。
- 高估问题并不是 DQN 本身的缺陷,而是训练 DQN 用的 Q 学习算法的缺陷。
1 自举(bootstrapping)导致的偏差传播
1.1 DQN参数更新(回顾)
Q-learning 算法每次从经验回放数组 (Replay Buffffer) 中抽取一个四元组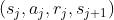 。然后执行以下步骤,对 DQN
的参数做一轮更新:
。然后执行以下步骤,对 DQN
的参数做一轮更新:
- 1,计算TD目标
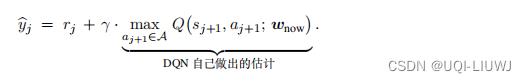
——> 的后一项基于DQN自己做出的估计
的后一项基于DQN自己做出的估计
- 2,定义损失函数
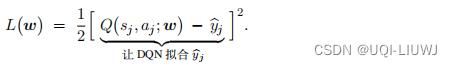
——>让DQN去拟合,也即用DQN自己做出的估计去拟合自己
- 3,进行梯度下降,更新参数

1.2 自举对DQN训练的影响
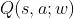 是对价值
是对价值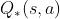 的近似
的近似- 最理想的情况下,=
- 但如果
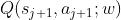 低估/高估了
低估/高估了  ,那么:
,那么:
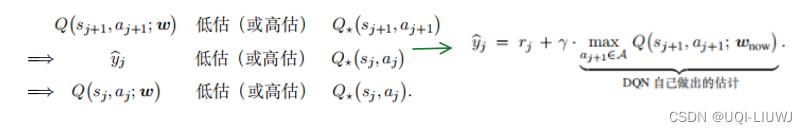
换句话说,这种低估/高估会不断地传播下去
2 最大化对DQN训练的影响
2.1 一个数学结论
设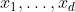 为任意d个实数,往中加入任意均值为0的随机噪声,得到随机变量
为任意d个实数,往中加入任意均值为0的随机噪声,得到随机变量 。
。

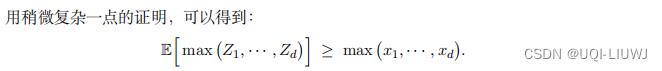
2.2 回到DQN
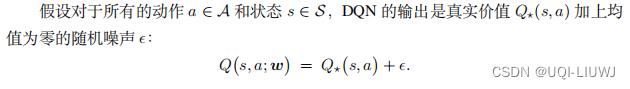
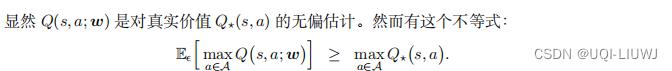
公式说明尽管 DQN 是对真实价值的无偏估计,但如果求最大化, DQN 则会高估真实价值。
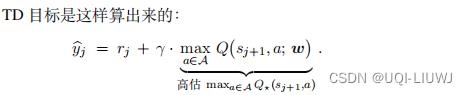
——>这说明TD目标通常是对真实价值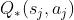 的高估(即使DQN是真实值Q*的无偏估计)
的高估(即使DQN是真实值Q*的无偏估计)
TD算法鼓励 接近TD目标
接近TD目标
——>这会导致高估真实值
3 不均匀高估的危害
- 高估本身是无害的,除非高估是非均匀的
- 举个例子,动作空间是 A = 左, 右, 上。给定当前状态 s,每个动作有一个真实价值:
- 智能体应当选择动作“上”,因为“上”的价值最高。
- 假如高估是均匀的,所有的价值都 被高估了 100:

- 那么动作“上”仍然有最大的价值,智能体会选择“上”。这个例子说明高估本身不是问题,只要所有动作价值被同等高估。
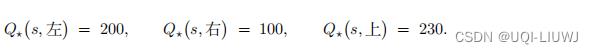
想要避免 DQN 的高估,要么切断“自 举”,要么避免最大化造成高估。 注意, 高估并不是 DQN 自身的属性;高估纯粹是算法造成的 。想要避免高估,就要用更好的算法替代原始的 Q 学习算法。但在实践中,所有的动作价值不一定会被同等高估
- 每当取出一个四元组
- 对于同一个状态s,(s,左),(s,右),(s,上)出现在经验回放数组中的频率是不同的
- ——>三种动作的价值被高估的程度是不同的
- 加入最终:
- 那么智能体agent会选择“右”,这却反而是实际价值最小的action
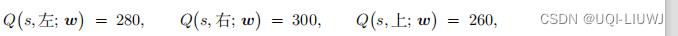
4 target network
想要避免 DQN 的高估,一种可行的方法是切断“自举”。
在Q-learning中,TD目标是这么计算的:
想要切断自举,可以用另一个神经网络来计算TD目标,而不是用DQN自己来计算TD目标。
——>另一个神经网络被称为目标网络(target network),我们记为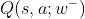
——> 他的神经网络结构和DQN完全相同,只是参数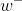 不同于w
不同于w
4.1 使用目标网络之后的Q-learning
- 每一次随机从经验回放中取出一个四元组
- 令DQN和目标网络的当前参数分别为
 和
和
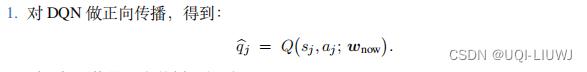
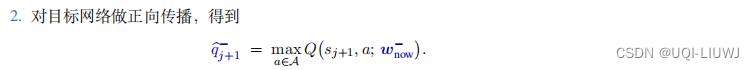

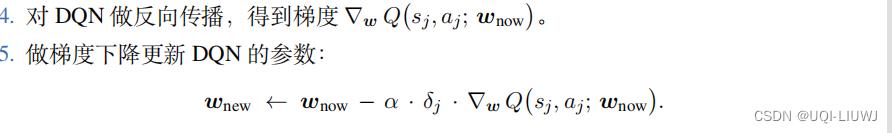
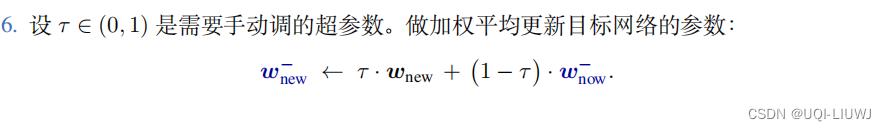
- 第6步这种方式叫做soft-replacing
而这种方法并 不可能完全避免自举 ,原因是目标网络的参数仍然与 DQN 相关。

就是因为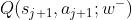 的高估/低估导致的高估/低估是还存在的,但是不会像不适用target network那样的Q-learning一样这种高估/低估传递下去
的高估/低估导致的高估/低估是还存在的,但是不会像不适用target network那样的Q-learning一样这种高估/低估传递下去
5 双Q学习方法 (double DQN)
- 在 Q 学习算法中使用目标网络,可以缓解自举造成的偏差,但是无助于缓解最大化造成的高估。
- 双 Q 学习 (Double Q Learning) 算法在目标网络的基础上做改进,缓解最大化造成的高估。
5.1 重新审视Q-learning 中的TD目标
我们可以把最大化拆分成两步

5.2 重新审视Q-learning+target network中的TD目标

5.3 double DQN
第一步的选择用 DQN ,第二步的求值用目标网络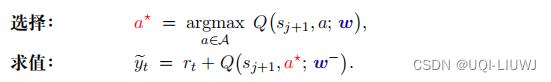
为什么双 Q 学习可以缓解最大化造成的高估呢?

(因为a*不一定是参数下的argmaxQ)
所以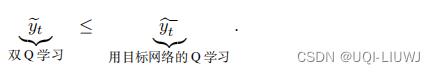
——>double DQN缓解了高估
5.4 double DQN下的Q-learning
- 每一次随机从经验回放中取出一个四元组
- 令DQN和目标网络的当前参数分别为和

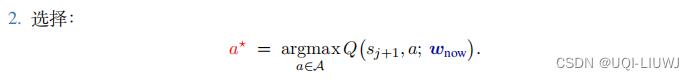
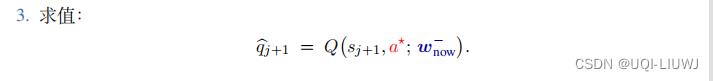
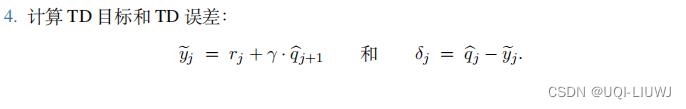

和target network+DQN不一样的也就是第二第三步
6 总结
- DQN 的高估不是 DQN 模型造成的,不是 DQN 的本质属性;高估只是因为原始 Q 学习算法不好
- Q 学习算法产生高估的原因有两个:
- 第一,自举导致偏差从一个 (s, a) 二元组传播到更多的二元组;
- 第二,最大化造成 TD 目标高估真实价值。

如果是 SARSA 算法强化学习笔记:Sarsa算法_UQI-LIUWJ的博客-CSDN博客_sarsa算法,那么自举的问题依然存在,但是在SARSA中不存在最大化造成高估的问题,所以只需要target network即可
以上是关于DQN笔记:高估问题 & target network & Double DQN的主要内容,如果未能解决你的问题,请参考以下文章