Linux命令之查找字符串grep
Posted 二木成林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux命令之查找字符串grep相关的知识,希望对你有一定的参考价值。
概述
grep 命令可以用于在指定文件中通过指定查找模式查找指定字符串。
注:与该命令有关的还有
egrep和fgrep可以关注一下。
语法
该命令的语法如下:
grep [选项] [查找模式] [文件名1, 文件名2, ...]
该命令支持的选项有:
| 选项 | 说明 |
|---|---|
| -a, --text | 不要忽略二进制的数据 |
-A <显示行数>, --after-context=<显示行数> | 除了显示符合范本样式的那一列之外,并显示该行之后的内容 |
| -b, --byte-offset | 在输出的每一行前显示包含匹配字符串的行在文件中的字节偏移量 |
-B <显示行数>, --before-context=<显示行数> | 除了显示符合样式的那一行之外,并显示该行之前的内容 |
| -c, --count | 只显示匹配行的数量 |
-C <显示行数>, --context=<显示行数>, -<显示行数> | 除了显示符合样式的那一行之外,并显示该行之前后的内容 |
-d <动作>, --directories=<动作> | 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作 |
-e <范本样式>, --regexp=<范本样式> | 指定检索使用的模式 |
| -E, --extended-regexp | 每个模式作为一个扩展的正则表达式对待 |
-f <规则文件>, --file=<规则文件> | 从expfile文件中获取要搜索的模式,一个模式占一行 |
| -F, --fixed-regexp | 每个模式作为一组固定字符串对待(以新行分隔),而不作为正则表达式 |
| -G, --basic-regexp | 将样式视为普通的表示法来使用 |
| -h, --no-filename | 在在查找多个文件时,指示grep不要将文件名加入到输出之前 |
| -H, --with-filename | 在显示符合样式的那一行之前,表示该行所属的文件名称 |
| -i, --ignore-case | 比较时不区分大小写 |
| -l, --file-with-matches | 列出文件内容符合指定的样式的文件名称 |
| -L, --files-without-match | 列出文件内容不符合指定的样式的文件名称 |
| -n, --line-number | 在输出前加上匹配串所在行的行号(文件首行行号为1) |
| -o, --only-matching | 只显示匹配PATTERN 部分 |
| -q, --quiet或–silent | 不显示任何信息 |
| -r, --recursive | 此参数的效果和指定"-d recurse"参数相同 |
| -s, --no-messages | 不显示错误信息 |
| -v, --invert-match | 显示不包含匹配文本的所有行 |
| -V, --version | 显示版本信息 |
| -w, --word-regexp | 只显示全字符合的列 |
| -x, --line-regexp | 只显示整行严格匹配的行 |
| -y | 此参数的效果和指定"-i"参数相同 |
注:虽然选项很多,但不需要记住大部分选项,只需要知道该命令的一些常用用法即可。
使用
在文件中查找指定关键字
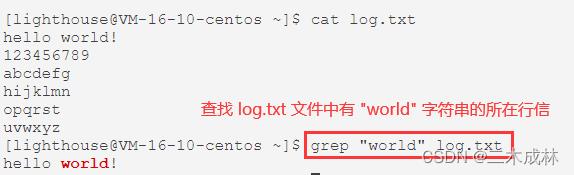
最常用的用法应该是在文件中查找指定关键字,语法格式如下:
# 语法
grep 指定关键字 指定文件
# 示例
grep "world" log.txt
注:待查找的指定关键字建议用双引号引起来,特别是在有空格的情况下。
显示除了匹配关键字之外的所有行
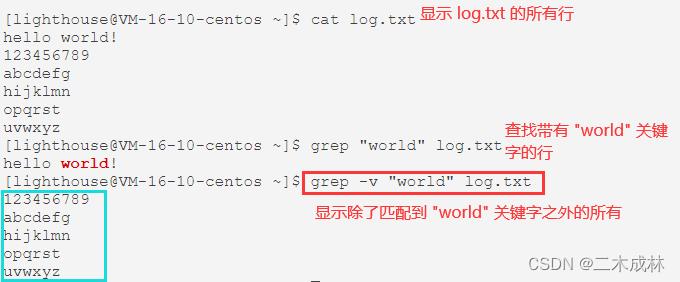
有时候我们想要显示那些除了匹配的关键字之外的所有行,可以加上 -v 选项:
# 语法
grep -v 指定关键字 指定文件
# 示例
grep -v "world" log.txt
显示行号
有时候我们希望看到匹配到的行在文件中的行号是多少,那么可以使用 -n 选项:
# 语法
grep -n 指定关键字 指定文件
# 示例
grep -n "world" log.txt

统计匹配到的总行数
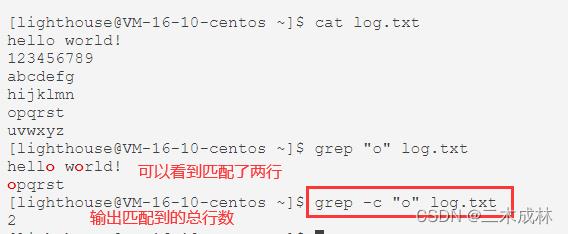
如果我们想要获取匹配到的总行数,那么可以使用 -c 选项:
# 语法
grep -c 指定关键字 指定文件
# 示例
grep -c "o" log.txt
显示匹配行之前或之后几行的内容
除了显示匹配行之外,可能我们还需要显示匹配行之前几行或者之后几行的信息。那么可以使用 -A 或 -B 或 -C 选项:
# 语法
grep -A 指定行数 指定关键字 指定文件
grep -B 指定行数 指定关键字 指定文件
grep -C 指定行数 指定关键字 指定文件
# 示例,表示显示 log.txt 文件中匹配到 "world" 的行及下面的 2 行内容
grep -A 2 "world" log.txt

注:
A选项,是After的缩写,表示除了展示匹配行之外,还要展示出匹配行下面的若干行。如-A 2表示还展示匹配行下面 2 行的内容。B选项,是Before的缩写,表示除了展示匹配行之外,还要展示出匹配行上面的若干行。如-B 2表示还展示匹配行上面 2 行的内容。C选项,是-A和-B选项的合体,表示除了展示匹配行之外,还要展示出匹配行上面和下面各若干行。如-C 2表示还展示匹配行上面 2 行和下面 2 行的内容。
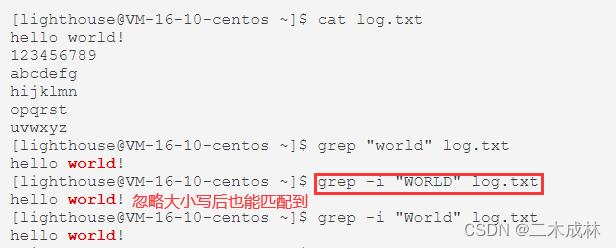
忽略大小写
有时候匹配的时候,希望忽略掉大小写,让大写和小写字母都能被匹配到,可以使用 -i 选项:
# 语法
grep -i 指定关键字 指定文件
# 示例
grep -i "WORLD" log.txt
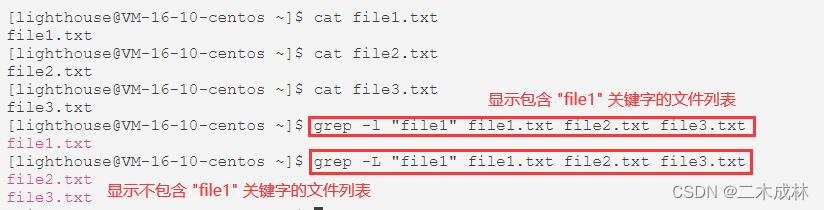
多文件查找
grep 命令是支持多文件查找的,显示结果它会输出匹配行内容和匹配行所在文件名。
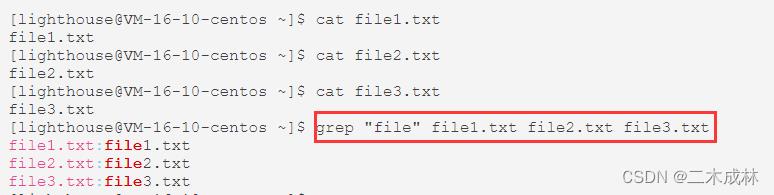
如果想要只显示匹配内容在那些文件中,可以加上 -l 选项,得到的就是一个包含有匹配内容的文件列表,而如果使用 -L 选项,则会得到一个不包含有匹配内容的文件列表。
支持基本正则表达式
grep 命令是支持正则表达式的,但是是支持基本正则表达式。即在基本正则表达式(BRE)中,只承认“^”、“$”、“.”、“[”、“]”、“*”这些是元字符,所有其他的字符(如 “(”、“)”、“”、“”、“?”、“+”、“|” 等)都被识别为普通字符。语法如下:
# 语法
grep 基本正则表达式 指定文件
# 示例,搜索 log.txt 文件中以 "h" 开头的行
grep "^h" log.txt

支持扩展正则表达式
如果要使用扩展正则表达式,即支持 “(”、“)”、“”、“”、“?”、“+”、“|” 等元字符。那么需要加上 -E 选项,或者使用 egrep 命令:
# 语法
grep -E 扩展正则表达式 指定文件
# 示例,搜索 log.txt 文件中包含至少一个 "h" 字符的行
grep -E "h+" log.txt

精确搜索某个词
如果我们想要精确搜索某个词,那么使用 -w 选项。

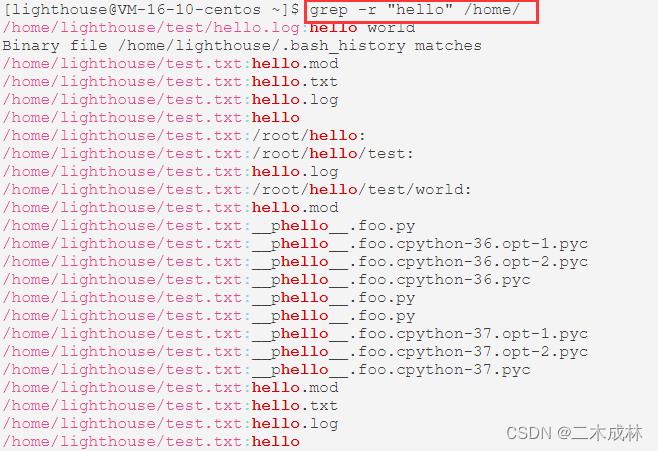
以递归方式查找符合条件的文件
如果我们要查找指定目录下所有符合条件的文件,那么可以使用 -r 选项:
# 语法
grep -r 指定关键字 指定目录名
# 示例,查找 /home/ 目录下所有包含 "hello" 字符串的文件
grep -r "hello" /home/
以上是关于Linux命令之查找字符串grep的主要内容,如果未能解决你的问题,请参考以下文章