浅析C++内存布局
Posted 特立独行的猫a
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析C++内存布局相关的知识,希望对你有一定的参考价值。
C++程序在内存中的布局是怎样的?总结下C++内存布局的相关知识。
概述
简单总结下C++变量在内存中的布局和可执行文件相关的知识。暂未涉及虚函数,虚函数表,类的继承和多态等C++对象的内存模型。对象的内存模型推荐经典书籍《 深度探索C++对象模型》,豆瓣评分9.1。
开篇先回顾下Linux运行时存储器映像:
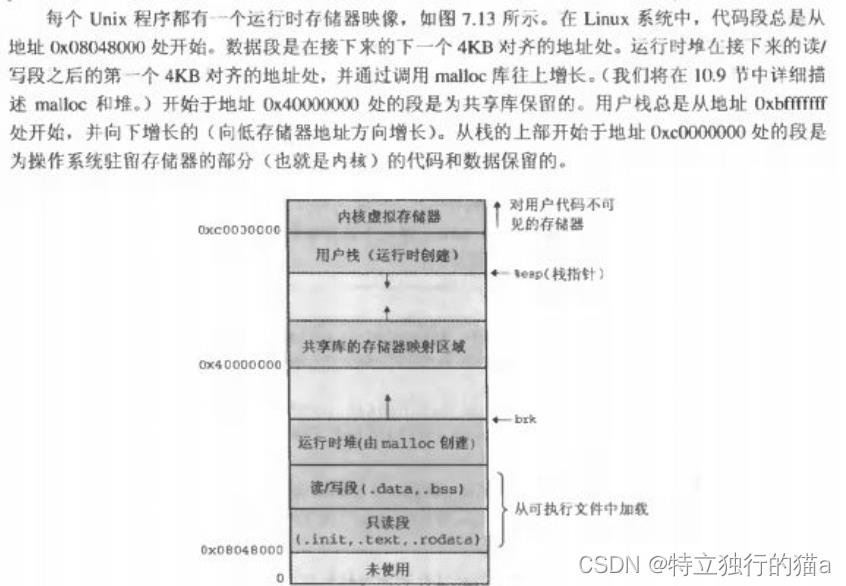
以下示例可以调试观测内存地址:
#include <iostream>
int gdata1 = 1;
int gdata2 = 0;
int gdata3;
static int gdata4 = 4;
static int gdata5 = 0;
static int gdata6;
int main()
int a = 11;
int b = 0;
int c;
static int d = 12;
static int e = 0;
static int f;
const char *p = "hello world";
return 0;
使用size命令和objdump来查看目标文件的结构和内容:
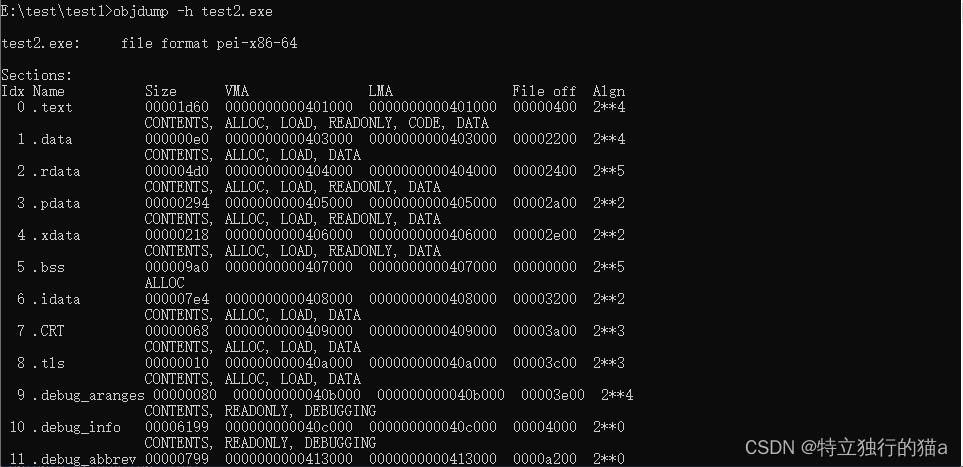
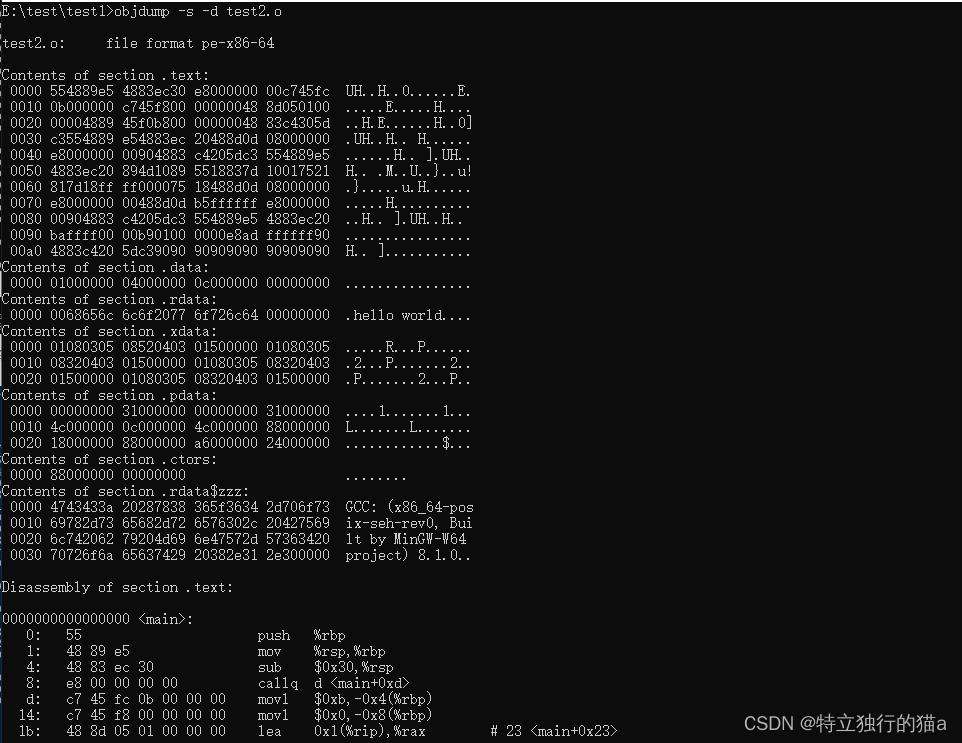
 使用 objdump -s -d 查看更详细的内容:
使用 objdump -s -d 查看更详细的内容:
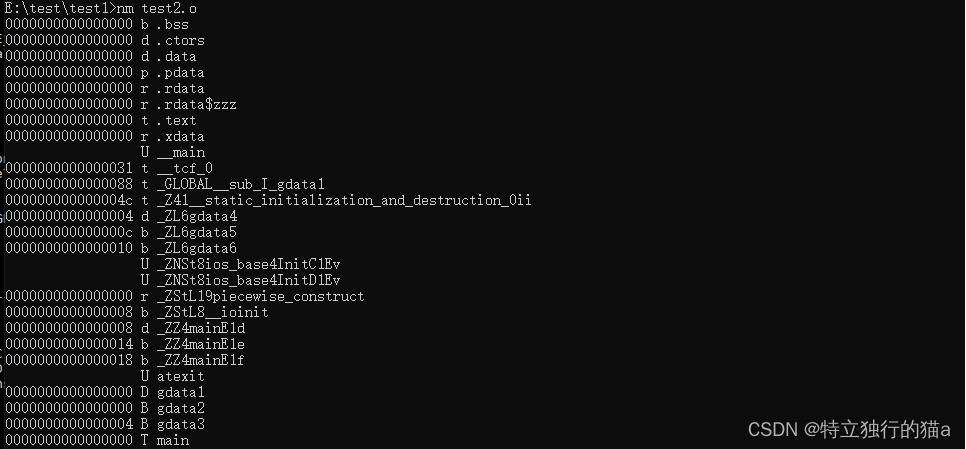
使用 nm (names)查看符号表 :
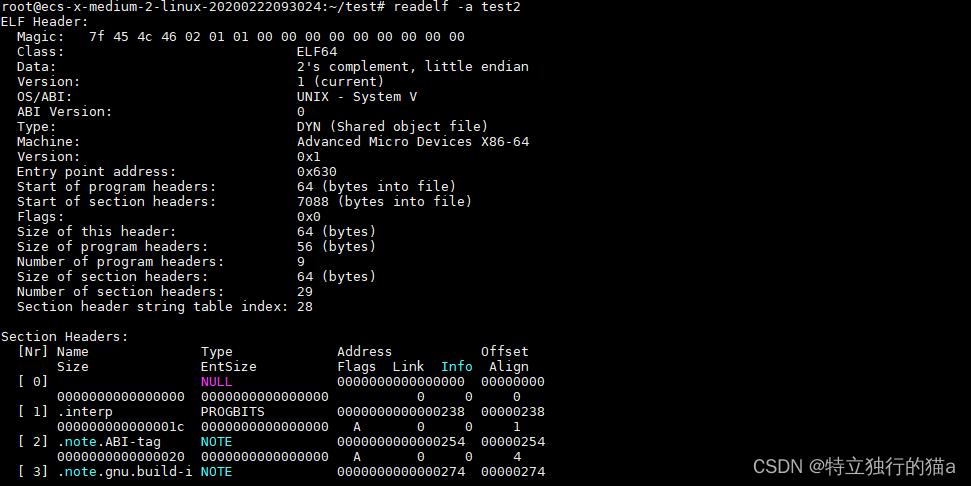
若是在linux下,上述指令都有效。还可使用readelf 可显示一个或者多个elf格式的目标文件的信息 。
readelf是Linux下的分析ELF文件的命令,这个命令在分析ELF文件格式时非常有用。常见的文件如在Linux上的可执行文件,动态库(*.so)或者静态库(*.a) 等包含ELF格式的文件。
什么是ELF文件?
ELF(Executable and Linkable Format)是Unix及类Unix系统下可执行文件、共享库等二进制文件标准格式。
系统里的目标文件是按照特定的目标文件格式来组织的,各个系统的目标文件格式都不相同。
从贝尔实验室诞生的第一个Unix系统使用的是a.out格式(直到今天,直到文件仍然称为a.out文件)。Windows使用可移植植入(PortableExecutable,PE)格式。MacOS- X使用Mach-O格式。现代x86-64Linux和Unix系统使用可调可链接格式(ELF)。
ELF格式的文件在Linux系统下有.axf,.bin,.elf,.o,.prx,.puff,.ko,.mod和.so等等。
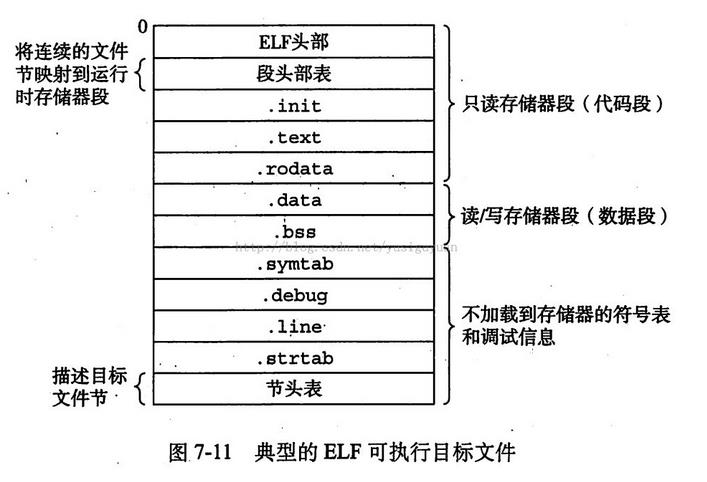
.text(代码段)
.text段存放程序代码,运行前就已经确定(编译时确定),通常为只读。
在window平台上,可执行程序为xxx.exe。它产生两种东西:指令和数据。.exe程序存放在磁盘中,执行时被加载到内存中,不是物理内存,而是虚拟内存空间,.text中存放指令。
.rodata(只读数据段)
rodata段存储常量数据,比如程序中定义为const的全局变量,#define定义的常量,以及诸如“Hello World”的字符串常量。(注意有些立即数与指令编译在一起,是放在text段中的)。
const修饰的全局变量在常量区。const修饰的局部变量只是为了防止修改,没有放入常量区。
编译器会去掉重复的字符串常量,程序的每个字符串常量只有一份。
有些系统中rodata段是多个进程共享的,目的是为了提高空间利用率。
如在main中的 const char *p = "hello world"; 即存放在.rodata中。在vs2017中,并不能将常量字符串定义为char *p类型,否则会编译失败;
.data
data存储已经初始化的全局变量,属于静态内存分配。(注意:初始化为0的全局变量还是被保存在BSS段),static声明的变量也存储在数据段。
.bss
bss段存储没有初值的全局变量或默认为0的全局变量,属于静态内存分配。 bss段内容会被全部设为0。
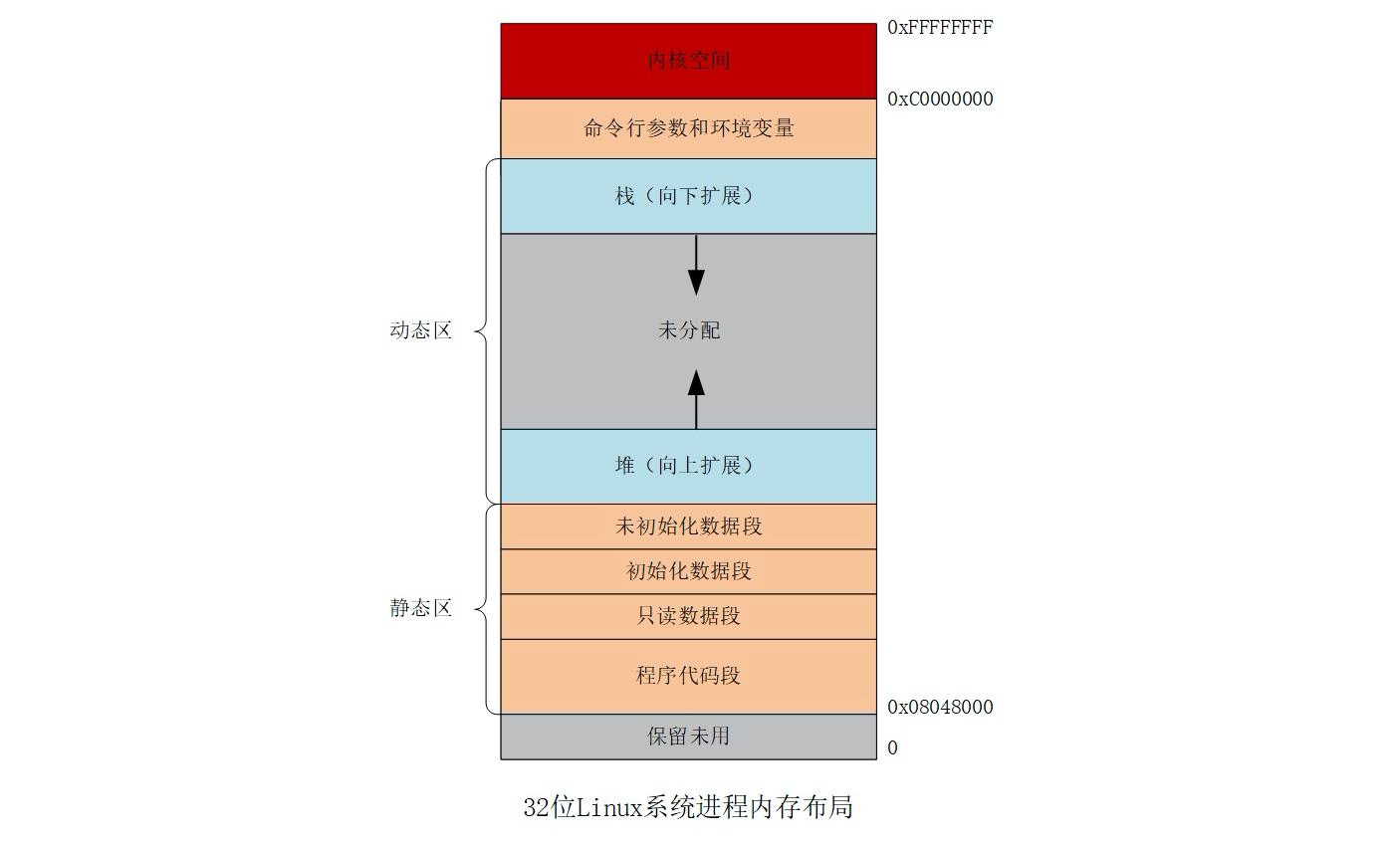
stack
stack段存储参数变量和局部变量,由系统进行申请和释放,属于静态内存分配。
stack的特点是先进先出,可用于保存/恢复调用现场。
heap
heap段是程序运行过程中被动态分配的内存段,由用户申请和释放(例如malloc和free)。
申请时至少分配虚存,当真正存储数据时才分配物理内存;释放时也不是立即释放物理内存,而是可能被重复利用。
总结
1、执行文件中包含了text、rodata、data段的内容,不包含bss段内容(一堆0放入执行文件没有意义)
2、堆和栈的内存增长方向是相反的:栈是从高地址向低地址生长,堆是从低地址向高地址生长。
3、局部变量存储在stack中,编写函数时要注意如果该函数被递归调用很多次,可能会引起stack overflow的问题。
C++程序的内存格局通常分为四大区:全局数据区(静态区,常量区),代码区(code area),栈区(stack area),堆区(heap area)(即自由存储区)。全局数据区存放全局变量,静态数据和常量。所有类和函数代码存放在代码区。为运行函数而分配的局部变量、函数参数、返回数据、返回地址等存放在栈区。余下的空间被称为堆区(在栈与堆之间有部分动态分配的姑且称之为共享区,叫法可能不一样)。

推荐书籍《程序员的自我修养》
该书主要介绍系统软件的运行机制和原理,涉及在Windows和Linux两个系统平台上,一个应用程序在编译、链接和运行时刻所发生的各种事项。
包括:代码指令是如何保存的,库文件如何与应用程序代码静态链接,应用程序如何被装载到内存中并开始运行,动态链接如何实现,C/C++运行库的工作原理,以及操作系统提供的系统服务是如何被调用的。

类对象所占的内存空间
一个类的实例化对象所占空间的大小? 注意不要说类的大小,是类的对象的大小。 首先,类的大小是什么?确切的说,类只是一个类型的定义,它是没有大小可言的,用sizeof运算符对一个类型名操作,得到的是具有该类型实体的大小:
#include <iostream>
class Test
;
int main()
Test test;
std::cout << sizeof(test) << std::endl; //1
return 0;
- 打开VS2019开发者命令行工具(每个版本都有)
- 切换到源文件所在路径
- cl /dl reportSingleClassLayout类名 "源文件名.cpp"
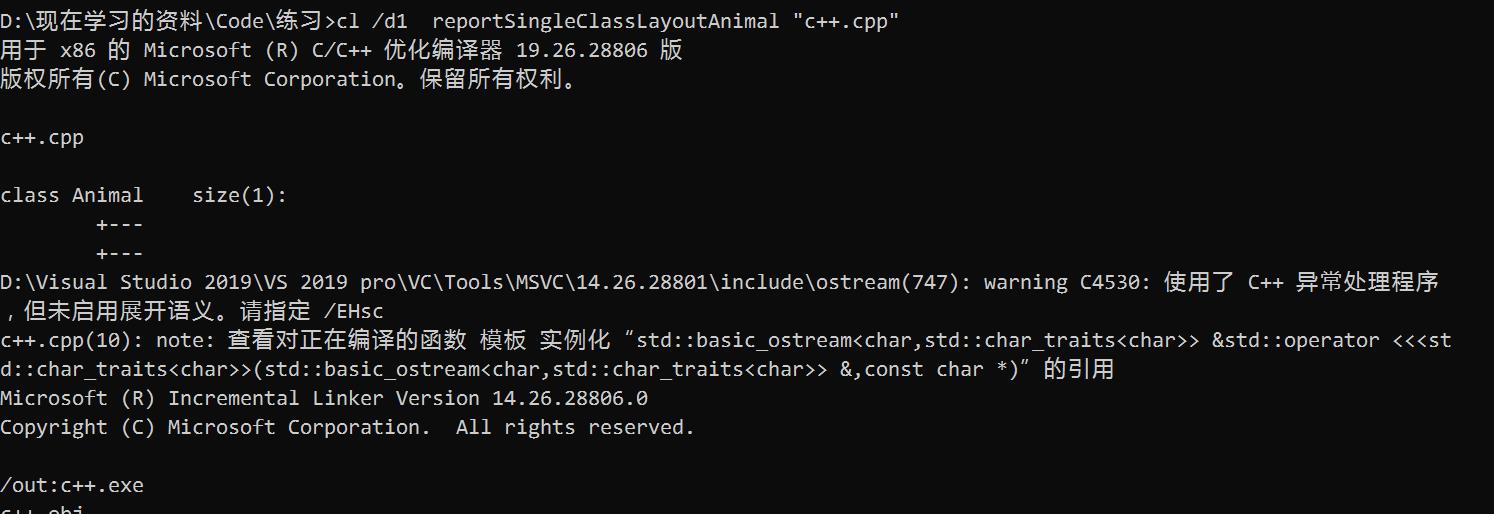
可以看到一个空类对象的大小1。
一个空类对象的大小是1,为什么不是0?
类A明明是空类,它的大小应该为0,为什么编译器输出的结果为1呢?这就是实例化的原因(空类同样被实例化),每个实例在内存中都有一个独一无二的地址,为了达到这个目的,编译器往往会给一个空类隐含的加一个字节,这样空类在实例化后在内存中得到了独一无二的地址,所以obj的大小是1。
添加虚函数之后,类的变化
当类中添加了虚函数时,类的大小变为4,同时编译器给类中添加了虚函数表指针
vfptr这个指针指向了vftable,vftable这张表里面存放的本类所有的虚函数入口地址。
结论
1.当类中添加了虚函数时,类的大小变为4,同时编译器给类中添加了虚函数表指针vfptr 这个指针指向了vftable,vftable 这张表里面存放的本类所有的虚函数入口地址。
2.当发生继承时,子类会将父类的虚函数表指针继承下来,指向父类的的虚函数表,在子类调用构造函数后,编译器会将该指针指向自己的虚函数表。
3.当子类重写了父类的虚函数时,在虚函数表中会用子类的函数地址去覆盖父类对应的虚函数地址。
4.程序运行时,通过父类指针或者引用 调用函数时,编译器会先找到该对象中的虚函数指针,根据指针找到虚函数表,在虚函数表中找到对应的函数入口 地址进行调用。
二进制可执行文件的执行流程
可执行文件生成过程
- 预处理:进行头文件和宏定义的替换
- 编译:由编译器把高级语言代码编译为汇编代码
- 汇编:由汇编器把汇编代码翻译成二进制代码,也即是.o文件
- 连接:由连接器把多个.o文件连接成可执行文件;可分为编译时链接,加载时链接(程序被加载到内存中执行时),运行时链接(由应用程序来执行时)。
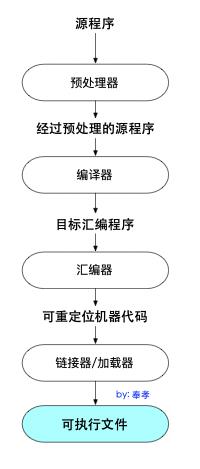

加载可执行目标文件
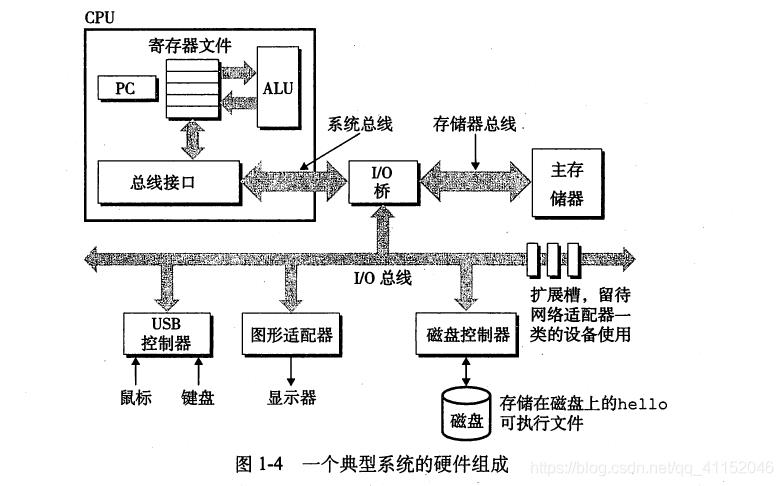
ELF头标书文件的整体格式还包含程序的入口点(程序需要运行时执行的第一条指令的地址)。可执行文件的连续片(chunk)被映射到连续的内存段。
当在shell中输入./programName时,shell解析到/判断不是内置命令(如果是内置命令时会搜索/usr /usr/lib ...)而是一个可执行文件,调用常驻内存的加载器(通过execve调用加载器)的操作系统代码来调用他。将可执行程序的代码和数据从磁盘复制到内存,在程序头部表的引导下加载器将可执行文件的片(chunk)复制到代码段和数据段,跳转到程序的第一条指令或入口点来运行。
linux的每个程序都运行在一个进程的上下文中,有自己的虚拟地址空间。当一个shell运行时,父进程shell生成一个子进程,他是父进程的一个复制。子进程通过execve系统调用调用加载器,加载器删除现有的虚拟内存段,创建新的代码段数据段堆栈,新堆栈被初始化为0,通过将虚拟地址空间的页映射到可执行文件的页面大小chunk,新的代码段和数据段被初始化为可执行文件的内容,最后跳转到_start,最终调用程序的main函数,除了头部的一些信息,加载过程没有任何数据从磁盘复制到内存,知道CPU引用的第一个虚拟页时才被复制。利用页面调度算法将他从磁盘复制到内存。
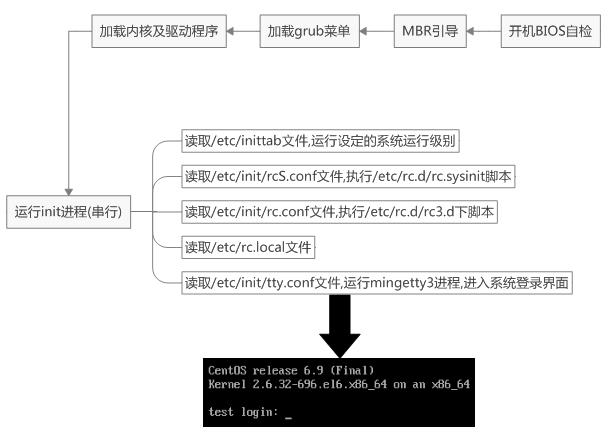
linux系统从开机到启动,执行流程从代码层面看大致经历:
设备上电后执行一段bootloader的汇编阶段。汇编第一阶段的代码主要可以分为以下部分:
设置异常向量表
设置特权管理模式
初始化PLL、DDR、MUX…
关MMU,关CACHE
判断代码在RAM还是FLASH,将FLASH代码复制至RAM中
设置堆栈、清空bss段
跳转至C语言处进入第二阶段,第二段也属于bootloader的功能,完成一些硬件资源初始化。最后才是操作系统内核的引导启动。
处理器流水线概述
1.经典的五级流水线
一条指令的流程:
- 取指
- 译码
- 执行
- 访存
- 写回
前一条指令完成了“取指”进入“译码”阶段后,下一条指令马上就可以进入“取指”阶段。
RISC-V架构
国外的指令集架构本质上是一种授权付费的,很难实现国产自主。如果国家自己定义一套指令集架构没有太大意义,因为处理器架构必须是全球范围的一个通用架构,必须获得生态支持。现在有了RISC-V可以很好的解决这一问题,“RISC-V可能真正能成为国产的自主的指令集架构。”
最近中美贸易战激战正酣,中兴被美国禁运的消息传来,一时间国内舆论大哗,说了多年的芯片“自主研发”,这么多的国产芯片上市公司,似乎到了关键时刻就被人卡脖子了。
胡振波表示,在产业界和芯片界,主流的大公司都在用RISC-V架构来做产品。西部数据和AMD都明确的说在用RISC-V做芯片,CEVA在用RISC-V做控制芯片核,谷歌也在用RISC-V做一些新的芯片项目。还有美光。除了这些大公司,还有很多业界大公司已经非常普遍的在用RISC-V来做内核。
最后,胡振波介绍了自己研发的首颗采用RISC-V架构的MCU蜂鸟E200。据介绍,这款全球最小的32位RISC-V核心可以实现超低功耗,对标的是ARM的M0 的MCU内核,安全可控,无需向国外公司支付版税。胡振波表示蜂鸟E200还有205、205FD等一系列产品线。
“这就是开放的指令集的魅力,接下来会冒出更多无法想象的指令集版本。”胡振波最后表示。
引用
【C++学习笔记】03-图说C++对象模型:对象内存布局详解_你行你上天的博客-CSDN博客
C++类对象的内存布局_一叶知秋dong的博客-CSDN博客_c++对象内存结构
https://www.jb51.net/article/225140.htm
C++类对象在内存中的布局_子木呀的博客-CSDN博客_c++对象内存布局
[RISC-V学习]《手把手教你设计CPU——RISC-V处理器》笔记(一)2021/11/10_qq_41876038的博客-CSDN博客_手把手教你设计cpu
从零开始写RISC-V处理器 | liangkangnan的博客
「OS」浅析从代码到可执行文件的过程 – better averyboy
Linux启动ELF可执行文件的过程_第二月的技术博客_51CTO博客
RISC-V架构能否让国产IC真正“自主研发”? - 芯智讯
【UBoot】uboot启动过程分析_Evan_ZGYF丶的博客-CSDN博客_uboot启动流程
【开发工具】【readelf】查看ELF格式文件工具(readelf)的使用_Evan_ZGYF丶的博客-CSDN博客_readelf 查询字符串
C++高级编程【虚函数机制】_Wy_编程的博客-CSDN博客
《Effective C++》 读书笔记(详细总结55条款)下篇_程序猿的温柔香的博客-CSDN博客
以上是关于浅析C++内存布局的主要内容,如果未能解决你的问题,请参考以下文章