Sqoop运行import导入数据至HDFS卡在MapReduce(问题记录)
Posted 不爱喝可乐QAQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sqoop运行import导入数据至HDFS卡在MapReduce(问题记录)相关的知识,希望对你有一定的参考价值。
一、问题详情
- 今天在对sqoop上运行import到HDFS时,一直卡住在map阶段,map与reduce都是显示0%,但是导入的数据量非常小,虚拟机内存也足够。后面寻找原因,应该是yarn的内存设置不够问题。
#执行的语句
bin/sqoop import \\
--connect jdbc:mysql://oracle12c:3306/gmall \\
--username root \\
--password root \\
--query 'select id,login_name from user_info where id>=1 and id<=20 and $CONDITIONS' \\
--target-dir /user_info \\
--delete-target-dir \\
--fields-terminated-by '\\t' \\
--num-mappers 2 \\
--split-by id
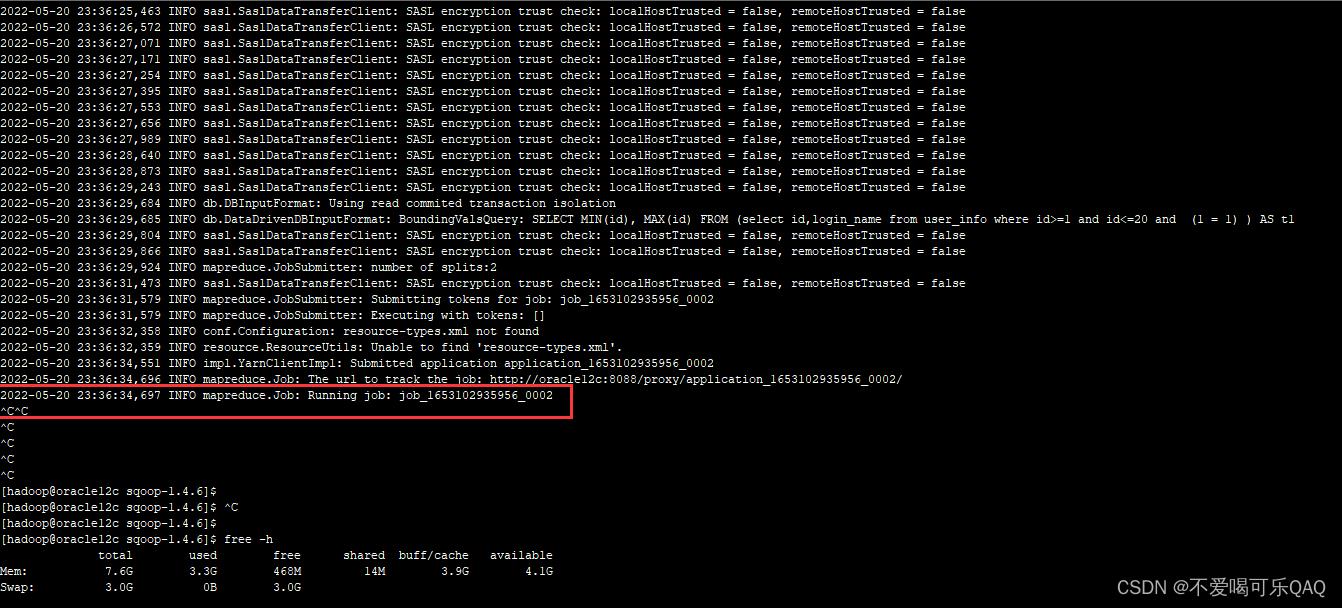
二、问题解决
- 在yarn-site.xml配置文件中修改如下配置,之前的总内存设置(resource.memory-mb)只有2046,现在增加到3072。单个容器的最小内存(minimum-allocation-mb)设置256。设置好之后保存退出,重启yarn服务,最后在执行sqoop的导入命令就能成功了。
<!--nodemanager 必须拥有大于等于1024的内存空间-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
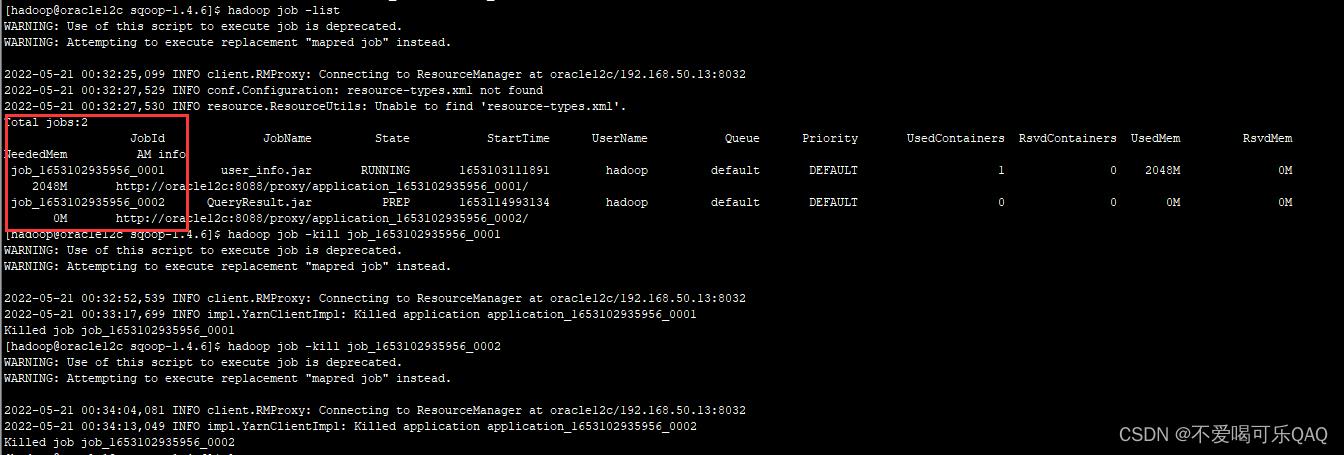
- 注意!在重新执行导入任务之前,要先kill掉之前的导入任务,不然可能也会卡住。
hadoop job -list #查看hadoop正在运行的job任务
hadoop job kill job名称 #结束掉运行的任务
以上是关于Sqoop运行import导入数据至HDFS卡在MapReduce(问题记录)的主要内容,如果未能解决你的问题,请参考以下文章