Hadoop概念补充
Posted 小企鹅推雪球!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop概念补充相关的知识,希望对你有一定的参考价值。
文章目录
NameNode如何支撑高并发访问(双缓冲机制)
- HDFS的元数据管理机制,Client每次请求NameNode修改一条元数据(比如说申请上传一个文件,都要写一条edits log,包括两个步骤:
- 写入本地磁盘–edits文件
- 通过网络传输给JournalNodes集群。
- 高并发的难点主要在于数据的多线程安全以及每个操作效率
- NameNode在写edits log有几个原则来保证多线程安全:
- 写入数据到edits_log必须保证每条edits都有一个全局顺序递增的transactionId(简称为txid),这样才可以标识出来一条一条的edits的先后顺序。
- 如果要保证每条edits的txid都是递增的,就必须得加同步锁。也就是每个线程修
- 改了元数据,要写一条edits 的时候,都必须按顺序排队获取锁后,才能生成一个递增的txid,代表这次要写的edits的序号。
- 如果每次都是在一个加锁的代码块里,生成txid,然后写磁盘文件edits log,这种既有同步锁又有写磁盘操作非常耗时!!
HDFS优化解决方案
- 串行化:使用分段锁,写磁盘:使用双缓冲
- 分段加锁机制:首先各个线程依次第一次获取锁,生成顺序递增的txid,然后将edits写入内存双缓冲的区域1,接着就立马第一次释放锁了。趁着这个空隙,后面的线程就可以再次立马第一次获取锁然后立即写自己的edits到内存缓冲。
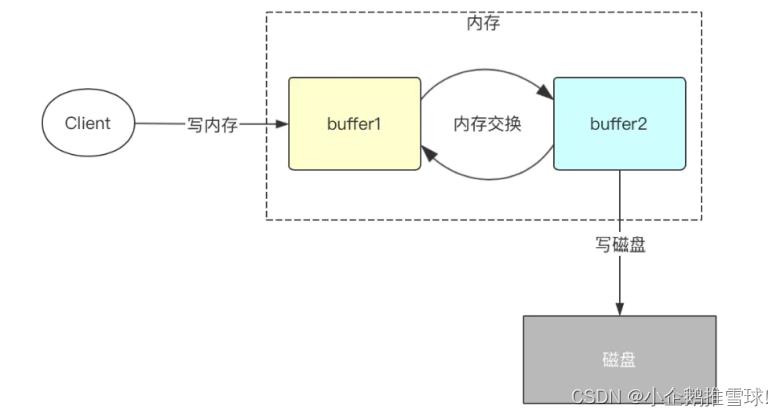
- 双缓冲机制:程序中将会开辟两份一模一样的内存空间,一个为bufCurrent,产生的数据会直接写入到这个bufCurrent,而另一个叫bufReady,在bufCurrent数据写入(达到一定标准)后,两片内存就会exchange(交换)。直接交换双缓冲的区域1和区域2。保证接收客户端写入数据请求的都是操作内存而不是同步写磁盘。
Job执行三原则
- Job执行三原则: 充分利用集群资源,reduce阶段尽量放在一轮,每个task的执行时间要合理
- 充分利用集群资源:Job运行时,尽量让所有的节点都有任务处理,这样能尽量保证集群资源被充分利用,任务的并发度达到最大。可以通过调整处理的数据量大小,以及调整map和reduce个数来实现
- Reduce个数的控制使用“mapreduce.job.reduces”
- Map个数取决于使用了哪种InputFormat,默认的TextFileInputFormat将根据block的个数来分配map数(一个block一个map)。
- ReduceTask并发调整:努力避免出现以下场景
- 观察Job如果大多数ReduceTask在第一轮运行完后,剩下很少甚至一个ReduceTask刚开始运行这种情况下,这个ReduceTask的执行时间将决定了该job的运行时间。可以考虑将reduce个数减少
- 观察Job的执行情况如果是MapTask运行完成后,只有个别节点有ReduceTask在运行。这时候集群资源没有得到充分利用,需要增加Reduce的并行度以便每个节点都有任务处理。
- Task执行时间要合理:一个job中,每个MapTask或ReduceTask的执行时间只有几秒钟,这就意味着这个job的大部分时间都消耗在task的调度和进程启停上了,因此可以考虑增加每个task处理的数据大小。建议一个task处理时间为1分钟
Job调优
- 推测执行:集群规模很大时(几百上千台节点的集群),个别机器出现软硬件故障的概率就变大了,并且会因此延长整个任务的执行时间推测执行通过将一个task分给多台机器跑,取先运行完的那个,会很好的解决这个问题。对于小集群,可以将这个功能关闭。

- Slow Start:MapReduce的AM在申请资源的时候,会一次性申请所有的Map资源,延后申请reduce的资源,这样就能达到先执行完大部分Map再执行Reduce的目的。当多少占比的Map执行完后开始执行Reduce。默认5%的Map跑完后开始起Reduce。如果想要Map完全结束后执行Reduce调整该值为1
- 小文件优化:
- HDFS:hadoop的存储每个文件都会在NameNode上记录元数据,如果同样大小的文件,文件很小的话,就会产生很多文件,造成NameNode的压力。
- MR:Mapreduce中一个map默认处理一个分片或者一个小文件,如果map的启动时间都比数据处理的时间还要长,那么就会造成性能低,而且在map端溢写磁盘的时候每一个map最终会产生reduce数量个数的中间结果,如果map数量特别多,就会造成临时文件很多,而且在reduce拉取数据的时候增加磁盘的IO。
- 如何处理小文件?
- 从源头解决,尽量在HDFS上不存储小文件,也就是数据上传HDFS的时候就合并小文件
- 通过运行MR程序合并HDFS上已经存在的小文件
- MR计算的时候可以使用CombineTextInputFormat来降低MapTask并行度
以上是关于Hadoop概念补充的主要内容,如果未能解决你的问题,请参考以下文章