MongoDB分片集群搭建
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB分片集群搭建相关的知识,希望对你有一定的参考价值。
参考技术A 分片(sharding)是一种跨多台机器分布数据的方法,MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署。换句话说:分片就是将数据拆分,将其分散存在不同的机器上的过程,将数据分散到不同的机器上,不需要功能强大的大型计算机就可以存储更多的数据,处理更多的负载。MongoDB分片集群包含以下组件:
下图描述了分片集群中组件的交互:
本文搭建的副本集集群是两个分片节点副本集(3+3)+一个配置节点副本集(3)+两个路由节点(2),共11个服务节点,具体如下图所示:
本次搭建一主一副本一仲裁,相关的配置文件、数据、日志都放在sharded_cluster相应的子目录下面,具体步骤如下:
myshardrs01
设置sharding.clusterRole需要mongod实例运行复制。 要将实例部署为副本集成员,请使用
replSetName设置并指定副本集的名称。
使用客户端命令连接主节点,这里最好连接主节点
执行初始化副本集命令:
查看副本集情况:
同样搭建一主一副本一仲裁,相关的配置文件、数据、日志都放在sharded_cluster相应的子目录下面,
具体步骤如下:
myshardrs02
myshardrs01_27318
设置sharding.clusterRole需要mongod实例运行复制。 要将实例部署为副本集成员,请使用
replSetName设置并指定副本集的名称
myshardrs01_27418
myshardrs01_27518
启动第二套副本集:一主一副本一仲裁
依次启动三个mongod服务:
查看服务是否启动:
新建或修改配置文件:
myconfigrs_27019:
新建或修改配置文件:
myconfigrs_27119
新建或修改配置文件:
myconfigrs_27219
依次启动配置的mongod副本集:一主两副本
查看服务是否启动:
Docker——基于Docker搭建MongoDB分片集群
基于Docker搭建MongoDB分片集群
- 学习视频来源
- 因为平台有相似的,发布为翻译-_-
基于Docker搭建MongoDB分片集群
- 分片 ( sharding ) 是MongoDB用来将大型集合分割到不同服务器(或者说一个集群)上所采用的方法,尽管分片起源于关系型数据库分区,但MongoDB分片完全又是另一回事。
- 和MySQL分区方案相比,MongoDB的最大区别在于它几乎能自动完成所有事情,只要告诉MongoDB要分配数据,它就能自动维护数据在不同服务器之间的均衡。
MongoDB分片简介
- 高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。
- 为了解决这些问题,有两个基本的方法:
垂直扩展和水平扩展。- 垂直扩展:增加更多的CPU和存储资源来扩展容量。
- 水平扩展:将数据集分布在多个服务器上,水平扩展即分片。
- 分片为应对高吞吐量与大数据星提供了方法。使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,集群可以提高自己的存储容量和吞吐量。举例来说,当插入一条数据时,应用只需要访问存储这条数据的分片
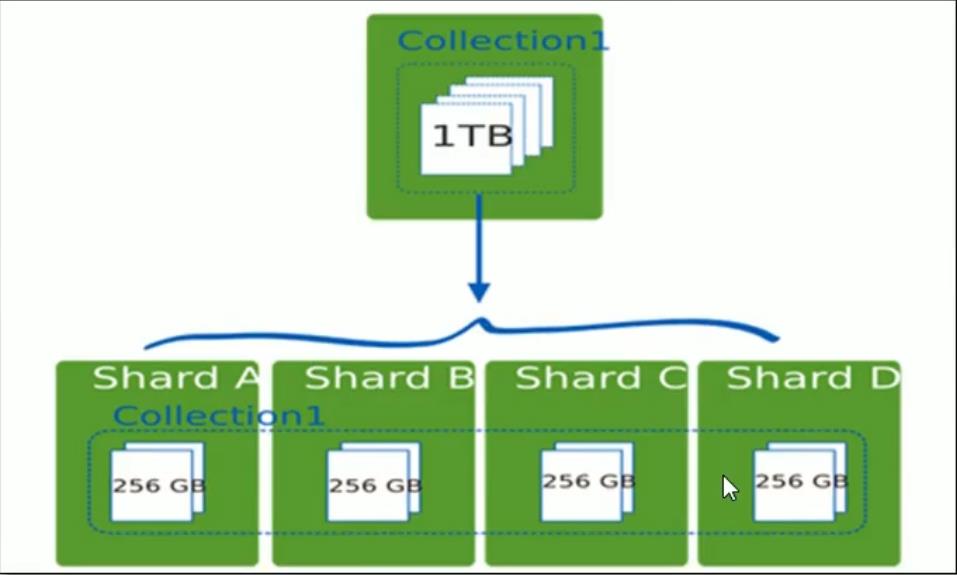
- 使用分片减少了每个分片存储的数据。例如,如果数据库1tb的数据集,并有4个分片,然后每个分片可能仅持有256 GB的数据。如果有40个分片,那么每个切分可能只有25GB的数据。
MongoDB分片的优势
- 对集群进行抽象,让集群
"不可见"- MongoDB自带了一个叫做
mongos的专有路由进程。mongos就是掌握统一路口的路由器,其会将客户发来的请求准确无误的路由到集群中的一个或者一组服务器上,同时会把接收到的响应拼装起来发回到客户端。
- MongoDB自带了一个叫做
- 保证集群总是可读写
- MongoDB通过多种途径来确保集群的可用性和可靠性。
- 将MongoDB的分片和复制功能结合使用,在确保数据分片到多台服务器的同时,也确保了每分数据都有相应的备份,这样就可以确保有服务器换掉时,其他的从库可以立即接替坏掉的部分继续工作。
- 使集群易于扩展
- 当集群需要更多的空间和资源的时候,MongoDB使我们可以按需方便地扩充系统容量
MongoDB分片架构
| 组件 | 说明 |
|---|---|
Config Server | 存储集群所有节点、分片数据路由信息,默认需要配置3个Config Server节点 |
Mongos | 提供对外应用访问,所有操作均通过Mongos执行,一般有多个Mongos节点,数据迁移和数据自动平衡 |
Mongod | 存储应用数据记录,一般有多个Mongod节点,达到数据分片目的 |
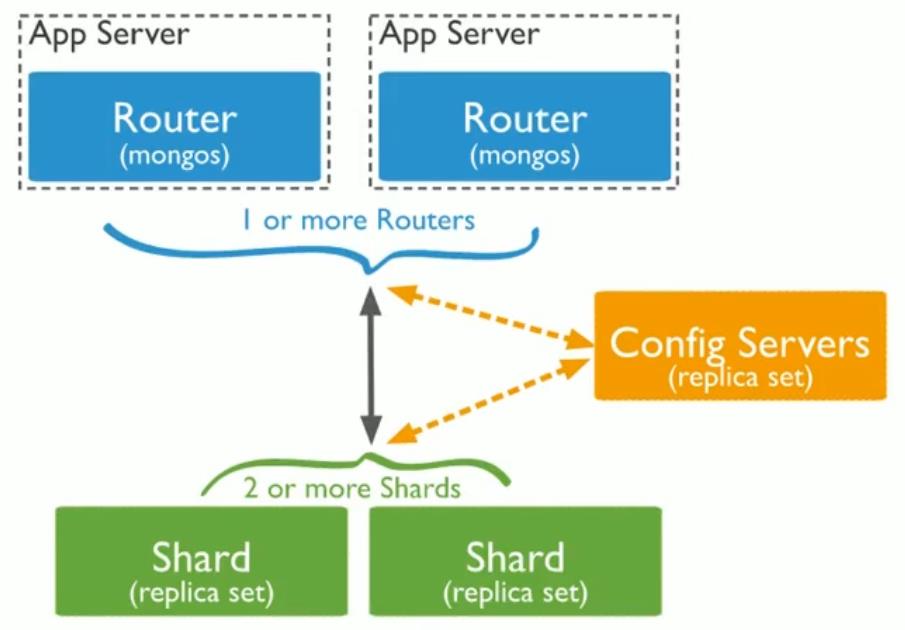
- Mongos本身并不持久化数据,Sharded cluster所有的元数据都会存储到Config Server,而用户的数据会分散存储到各个shard。Mongos启动后,会从配置服务器加载元数据,开始提供服务,将用户的请求正确路由到对应的分片。
- 当数据写入时,MongoDB Cluster根据
分片键设计写入数据。当外部语句发起数据查询时,MongoDB根据数据分布自动路由至指定节点返回数据。
集群中数据分布
- 在一个shard server内部,MongoDB会把数据分为chunks,每个chunk代表这个shard server内部一部分数据。chunk的产生,会有以下两个用途︰
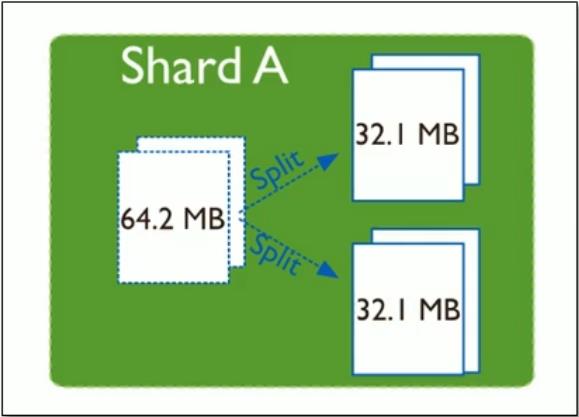
- Splitting:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况
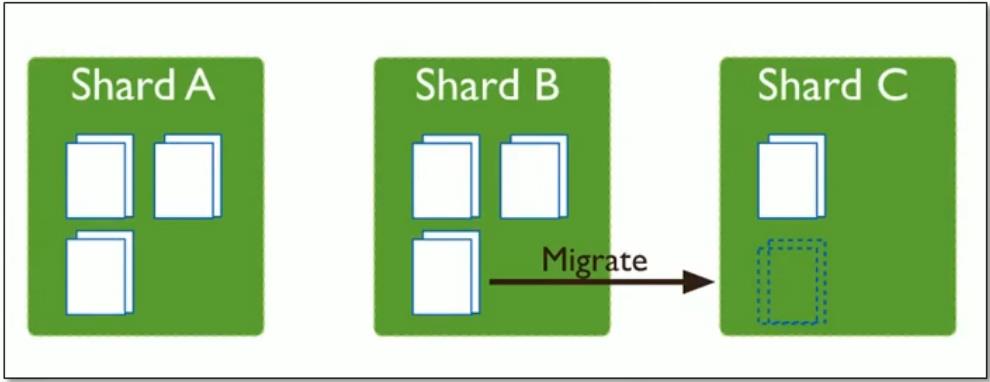
- Balancing :在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk , chunk size默认值
64M,生产库上选择适合业务的chunk size是最好的。MongoDB会自动拆分和迁移chunks。
Chunk分裂及迁移
- 随着数据的增长,其中的数据大小超过了配置的chunk size,默认是64M,则这个chunk就会分裂成两个。数据的增长会让chunk分裂得越来越多。
- 这时候,各个shard 上的chunk数量就会不平衡。mongos中的一个组件balancer就会执行自动平衡。把chunk从chunk数量最多的shard节点挪动到数量最少的节点
Chunksize
- chunk的分裂和迁移非常消耗IO资源;chunk分裂的时机∶在插入和更新,读数据不会分裂。
- 小的chunksize:数据均衡是迁移速度快,数据分布更均匀。数据分裂频繁,路由节点消耗更多资源。
- 大的chunksize:数据分裂少。数据块移动集中消耗IO资源。
- 适合业务的chunksize是最好的。
chunksize对分裂及迁移的影响
- MongoDB默认的chunkSize为64MB,如无特殊需求,建议保持默认值;chunkSize 会直接影响到chunk分裂、迁移的行为。
- chunkSize越小, chunk分裂及迁移越多,数据分布越均衡;反之,chunkSize越大,chunk分裂及迁移会更少,但可能导致数据分布不均。
- chunk自动分裂只会在数据写入时触发,所以如果将chunkSize改小,系统需要一定的时间来将chunk分裂到指定的大小。
- chunk只会分裂,不会合并,所以即使将chunkSize改大,现有的chunk数量不会减少,但chunk大小会随着写入不断增长,直到达到目标大小。
MongoDB分片集群搭建
#搭建三个config节点
#--configsvr 默认走的端口27019 --replSet 设置复制集名称
docker create --name configsvr01 -p 17000:27019 -v mongoconfigsvr-data-01:/data/configdb mongo:4.0.3 --configsvr --replSet "rs_configsvr" --bind_ip_all
docker create --name configsvr02 -p 17001:27019 -v mongoconfigsvr-data-02:/data/configdb mongo:4.0.3 --configsvr --replSet "rs_configsvr" --bind_ip_all
docker create --name configsvr03 -p 17002:27019 -v mongoconfigsvr-data-03:/data/configdb mongo:4.0.3 --configsvr --replSet "rs_configsvr" --bind_ip_all
#启动服务
docker start configsvr01 configsvr02 configsvr03
#进入容器操作
docker exec -it configsvr01 /bin/bash
mongo 192.168.100.100:17000
#集群初始化
rs.initiate(
{
_id: "rs_configsvr",
configsvr: true,
members: [
{ _id: 0, host : "192.168.100.100:17000" },
{ _id: 1, host : "192.168.100.100:17001" },
{ _id: 2, host : "192.168.100.100:17002" },
]
}
)
rs_configsvr:SECONDARY>
rs_configsvr:PRIMARY>
#搭建2个shard集群,每个集群都有3个数据节点
#--shardsvr 参数添加后 默认端口为27018
#集群一
docker create --name shardsvr01 -p 37000:27018 -v mongoshardsvr-data-01:/data/db mongo:4.0.3 --replSet "rs_shardsvr1" --bind_ip_all --shardsvr
docker create --name shardsvr02 -p 37001:27018 -v mongoshardsvr-data-02:/data/db mongo:4.0.3 --replSet "rs_shardsvr1" --bind_ip_all --shardsvr
docker create --name shardsvr03 -p 37002:27018 -v mongoshardsvr-data-03:/data/db mongo:4.0.3 --replSet "rs_shardsvr1" --bind_ip_all --shardsvr
#集群二
docker create --name shardsvr04 -p 37003:27018 -v mongoshardsvr-data-04:/data/db mongo:4.0.3 --replSet "rs_shardsvr2" --bind_ip_all --shardsvr
docker create --name shardsvr05 -p 37004:27018 -v mongoshardsvr-data-05:/data/db mongo:4.0.3 --replSet "rs_shardsvr2" --bind_ip_all --shardsvr
docker create --name shardsvr06 -p 37005:27018 -v mongoshardsvr-data-06:/data/db mongo:4.0.3 --replSet "rs_shardsvr2" --bind_ip_all --shardsvr
#启动容器
docker start shardsvr01 shardsvr02 shardsvr03
docker start shardsvr04 shardsvr05 shardsvr06
#进入容器执行
docker exec -it shardsvr01 /bin/bash
mongo 192.168.100.100:37000
#初始化集群
rs.initiate(
{
_id: "rs_shardsvr1",
members: [
{ _id: 0, host : "192.168.100.100:37000" },
{ _id: 1, host : "192.168.100.100:37001" },
{ _id: 2, host : "192.168.100.100:37002" },
]
}
)
docker exec -it shardsvr04 /bin/bash
mongo 192.168.100.100:37003
rs.initiate(
{
_id: "rs_shardsvr2",
members: [
{ _id: 0, host : "192.168.100.100:37003" },
{ _id: 1, host : "192.168.100.100:37004" },
{ _id: 2, host : "192.168.100.100:37005" },
]
}
)
#创建Mongos节点容器,需要指定config服务
#--entrypoint 指定入口点
docker create --name mongos -p 6666:27017 --entrypoint "mongos" mongo:4.0.3 --configdb rs_configsvr/192.168.100.100:17000,192.168.100.100:17001,192.168.100.100:17002 --bind_ip_all
docker start mongos
#进入容器执行
docker exec -it mongos bash
mongo 192.168.100.100:6666
mongos>
#添加shard节点
sh.addShard("rs_shardsvr1/192.168.100.100:37000,192.168.100.100:37001,192.168.100.100:37002")
sh.addShard("rs_shardsvr2/192.168.100.100:37003,192.168.100.100:37004,192.168.100.100:37005")
#查看集群状态
sh.status()
集群测试操作
#启用分片
sh.enableSharding("test")
#设置分片规则,按照_id的hash进行区分
sh.shardCollection("test.order", {"_id": "hashed"})
#插入数据测试
use test
for (i = 1; i <= 1000; i=i+1){
db.order.insert({'id':i , 'price': 100+i})
}
WriteResult({ "nInserted" : 1 })
mongos> db.order.count()
1000
mongos> db.order.find()
#分别在两个shard集群中查询数据进行测试
root@591de2dfcfe5:/# mongo 192.168.100.100:37000/test
rs_shardsvr1:PRIMARY> db.order.count()
502
root@591de2dfcfe5:/# mongo 192.168.100.100:37003/test
rs_shardsvr2:PRIMARY> db.order.count()
498
#集群操作(在Mongos中执行)
mongos> use config #需要进入config库
mongos> db.databases.find() #列出所有数据库分片情况
mongos> db.collections.find() #查看分片的片键
mongos> sh.status() #查询分片集群的状态信息
以上是关于MongoDB分片集群搭建的主要内容,如果未能解决你的问题,请参考以下文章