mysql的索引何时生效
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql的索引何时生效相关的知识,希望对你有一定的参考价值。
简单的说:查询的时候生效。
判断mysql的索引生效的方法:
用explain 来执行检验sql 例如
explain select * from a
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len |ref | rows | Extra |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
第四列 type
这列很重要,显示了连接使用了哪种类别,有无使用索引.
从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL
(1).system
这是const联接类型的一个特例。表仅有一行满足条件.
2).const
表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,在这行的列值可被优化器剩余部分认为是常数。const表很快,因为它们只读取一次!
3). eq_ref
对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARYKEY。
eq_ref可以用于使用=操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。
(4).ref
对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARYKEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。
ref可以用于使用=或<=>操作符的带索引的列。
(5). ref_or_null
该联接类型如同ref,但是添加了mysql可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
在下面的例子中,MySQL可以使用ref_or_null联接来处理ref_tables:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
(6). index_merge
该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
例如:
mysql> explain select * from t4 where id=3952602 oraccountid=31754306 ;
+----+-------------+-------+-------------+----------------------------+----------------------------+---------+------+------+------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------------+----------------------------+----------------------------+---------+------+------+------------------------------------------------------+
| 1 | SIMPLE | t4 | index_merge | idx_t4_id,idx_t4_accountid |idx_t4_id,idx_t4_accountid | 4,4 | NULL| 2 | Using union(idx_t4_id,idx_t4_accountid); Usingwhere |
+----+-------------+-------+-------------+----------------------------+----------------------------+---------+------+------+------------------------------------------------------+
1 row in set (0.00 sec)
(7). unique_subquery
该类型替换了下面形式的IN子查询的ref:
value IN (SELECT primary_key FROM single_table WHEREsome_expr)
unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
(8).index_subquery
该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:
value IN (SELECT key_column FROM single_table WHEREsome_expr)
(9).range
只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。
当使用=、<>、>、>=、<、<=、ISNULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range
mysql> explain select * from t3 where id=3952602 or id=3952603;
+----+-------------+-------+-------+-------------------+-----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len |ref | rows | Extra |
+----+-------------+-------+-------+-------------------+-----------+---------+------+------+-------------+
| 1 | SIMPLE | t3 | range | PRIMARY,idx_t3_id | idx_t3_id | 4 | NULL | 2 | Using where |
+----+-------------+-------+-------+-------------------+-----------+---------+------+------+-------------+
1 row in set (0.02 sec)
(10).index
该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。
当查询只使用作为单索引一部分的列时,MySQL可以使用该联接类型。
(11). ALL
对于每个来自于先前的表的行组合,进行完整的表扫描。如果表是第一个没标记const的表,这通常不好,并且通常在它情况下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常数值或列值被检索出。
参考技术A 数索引顾名思义就是加给字段加了函数的索引,这里的函数也可以是表达式。所以也叫表达式索引。MySQL 5.7 推出了虚拟列的功能,MySQL8.0的函数索引内部其实也是依据虚拟列来实现的。
MySQL索引的分类何时使用何时不使用何时失效?
1、分类
MySQL索引分为普通索引、唯一索引、主键索引、组合索引、全文索引。索引不会包含有null值的列,索引项可以为null(唯一索引、组合索引等),但是只要列中有null值就不会被包含在索引中。
(1)普通索引: create index index_name on table(column);
或者创建表时指定,create table(..., index index_name column);
(2)唯一索引: 类似普通索引,索引列的值必须唯一(可以为空,这点和主键索引不同)
create unique index index_name on table(column);或者创建表时指定unique index_name column
(3)主键索引: 特殊的唯一索引,不允许为空,只能有一个,一般是在建表时指定primary key(column)
(4)组合索引: 在多个字段上创建索引,遵循最左前缀原则。alter table t add index index_name(a,b,c);
(5)全文索引: 主要用来查找文本中的关键字,不是直接与索引中的值相比较,像是一个搜索引擎,配合match against使用,现在只有char,varchar,text上可以创建全文索引。
在数据量较大时,先将数据放在一张没有全文索引的表里,然后再利用create index创建全文索引,比先生成全文索引再插入数据快很多。
2、何时使用索引
MySQL每次查询只使用一个索引。与其说是“数据库查询只能用到一个索引”,倒不如说,和全表扫描比起来,去分析两个索引B+树更加耗费时间。所以where A=a and B=b这种查询使用(A,B)的组合索引最佳,B+树根据(A,B)来排序。
主键,unique字段;
和其他表做连接的字段需要加索引;
在where里使用>,≥,=,<,≤,is null和between等字段;
使用不以通配符开始的like,where A like \'China%\';
聚集函数MIN(),MAX()中的字段;
order by和group by字段;
3、何时不使用索引
表记录太少;
数据重复且分布平均的字段(只有很少数据值的列);
经常插入、删除、修改的表要减少索引;
text,image等类型不应该建立索引,这些列的数据量大(假如text前10个字符唯一,也可以对text前10个字符建立索引);
MySQL能估计出全表扫描比使用索引更快时,不使用索引;
4、索引何时失效
组合索引未使用最左前缀,例如组合索引(A,B),where B=b不会使用索引;
like未使用最左前缀,where A like \'%China\';
搜索一个索引而在另一个索引上做order by,where A=a order by B,只使用A上的索引,因为查询只使用一个索引 ;
or会使索引失效。如果查询字段相同,也可以使用索引。例如where A=a1 or A=a2(生效),where A=a or B=b(失效)
如果列类型是字符串,要使用引号。例如where A=\'China\',否则索引失效(会进行类型转换);
在索引列上的操作,函数(upper()等)、or、!=(<>)、not in等;
5、explain语句
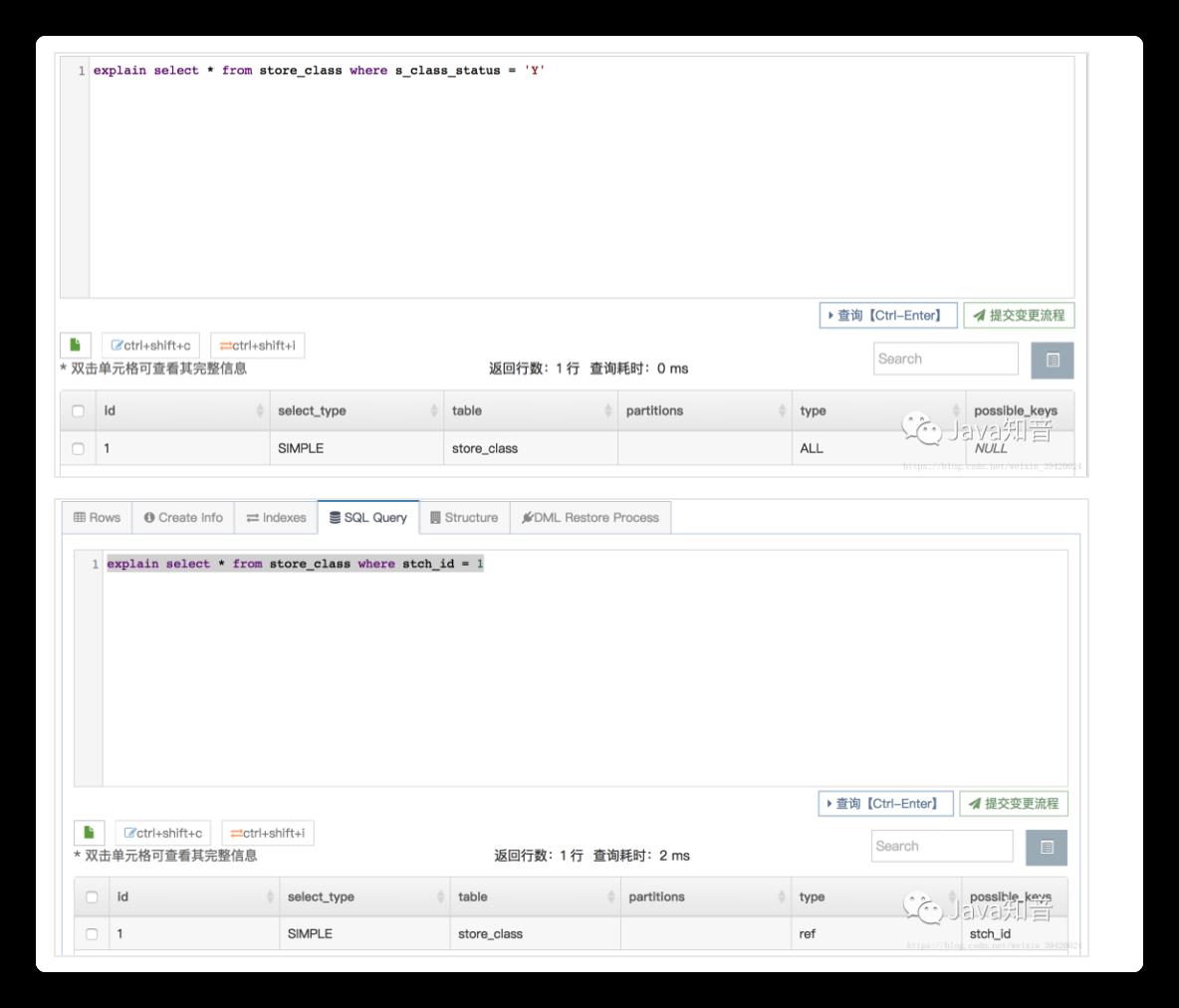
type字段为All,未使用索引;为ref,使用索引
ALL: 全表扫描
index: 索引全扫描
range: 索引范围扫描,常用语<,<=,>=,between等操作
ref: 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
eq_ref: 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
const/system: 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
null: MySQL不访问任何表或索引,直接返回结果
还有key字段表示用到的索引,没有用到为null。
以上是关于mysql的索引何时生效的主要内容,如果未能解决你的问题,请参考以下文章