Spark SQL中的DataFrame的创建
Posted 鄙人阿彬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL中的DataFrame的创建相关的知识,希望对你有一定的参考价值。
创建 SparkSession 对象可以通过SparkSession.builder().getOrCreate()方法获取,但使用 Spark-Shell编写程序时,Spark-Shell客户端会默认提供了一个名为sc的 SparkContext 对象和一个名为 spark 的 SparkSession对象,因此可以直接使用这两个对象,不需要自行创建。启动 Spark-Shell命令如下所示。
Spark-shell --master local [2]
启动之后如下图:

(1)准备数据:
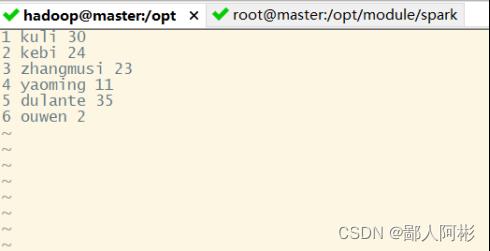
在HDFS文件系统的/spark目录中创建一个person.txt文件(vi person.txt),内容如下:
1 kuli 30
2 kebi 24
3 zhangmusi 23
4 yaoming 11
5 dulante 35
6 ouwen 2
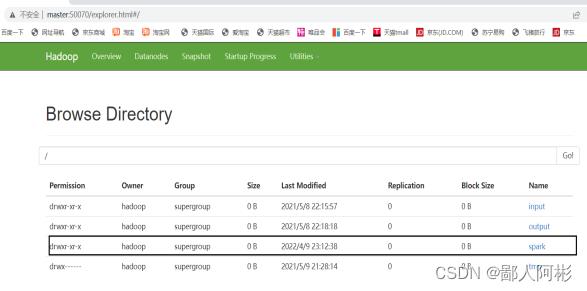
由于/spark目录已经存在,就不用再创建,只需把person.txt文件上传到/spark。
hadoop fs -put person.txt /spark
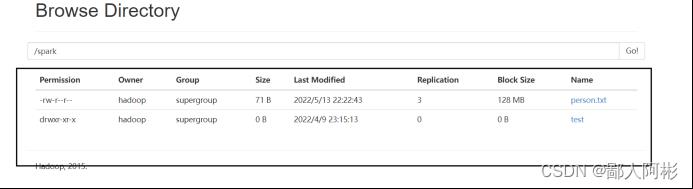
由上图可知person.txt文件已经上传成功。
(2)通过文件直接创建DataFrame,代码如下:
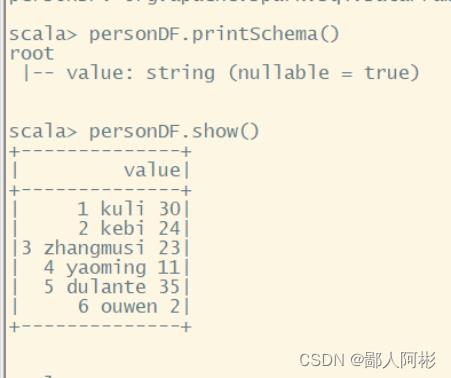
val personDF = spark.read.text(“/spark/person.txt”)
personDF.printSchema()

使用DataFrame的show()方法查看当前DataFrame的结果数据:personDF.show()
(3)RDD转换DataFrame
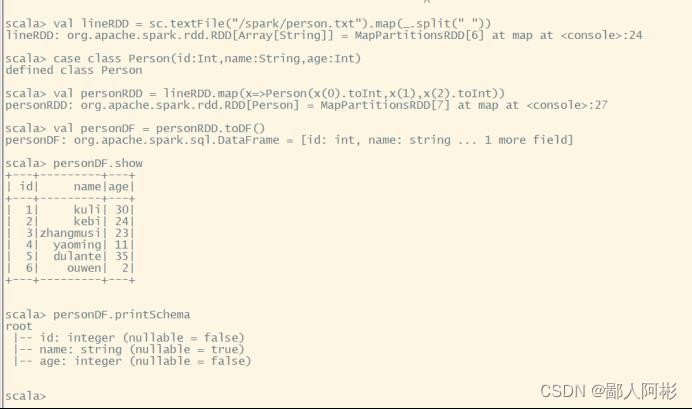
调用RDD的toDF()方法,可以将RDD转换为DataFrame对象,具体代码如下:
val lineRDD = sc.textFile(“/spark/person.txt”).map(_.split(“ ”))
case class Person(id:Int,name:String,age:Int)
val personRDD = lineRDD.map(x => Person(x(0).toInt,x(1),x(2).toInt))
val personDF = personDF.toDF()
personDF.show
personDF.printSchema
好啦,Spark SQL中的DataFrame这样就做好了,下一篇啊彬会给大家鞋一篇关于Spark SQL中DataFrame的操作。
以上是关于Spark SQL中的DataFrame的创建的主要内容,如果未能解决你的问题,请参考以下文章