Python验证码识别和生成(5000字详细实例和概念讲解)
Posted YR_T
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python验证码识别和生成(5000字详细实例和概念讲解)相关的知识,希望对你有一定的参考价值。
目录
哈喽O(∩_∩)O
:.,,.-:*``*:-.,,.-:*``*:
╭╧╮ ╭╧╮ ╭╧╮ ╭╧╮
║周║║末║║快║║乐║
└﹏┘└﹏┘└﹏┘└﹏┘
* * * * * * * * * * * * *
╒╧╕ ╒╧╕ ╒╧╕ ╒╧╕ ╒╧╕
|財||招||吉||大||閣|
|源||財||祥||吉||家|
|廣||進||如||大||平|
|進||寶||意||利||安|
╘═╛ ╘═╛ ╘═╛ ╘═╛ ╘═╛
今天,我研究了一下Python爬虫的功能——验证码识别
比如某网站有这样一张人机验证的图片
我要用程序识别出验证码是什么,并输入验证码,打开网站,爬取内容。

ddddocr
ddddocr是一款开源库,专门用来识别验证码,方便快捷
安装
终端运行:pip install ddddocr
使用
ddddocr接收这几个参数
| 参数名 | 默认值 | 说明 |
|---|---|---|
| use_gpu | False | Bool 是否使用gpu进行推理,如果该值为False则device_id不生效 |
| device_id | 0 | int cuda设备号,目前仅支持单张显卡 |
classification
| 参数名 | 默认值 | 说明 |
|---|---|---|
| img | 0 | bytes 图片的bytes格式 |
试一下
在编译器中输入如下代码:
import ddddocr
ocr=ddddocr.DdddOcr(old=True)
with open("1.jpg", 'rb') as f:
image = f.read()
print(ocr.classification(image))1.jpg是这样的

输出结果:

可以看到,成功识别出了 z4ta
但是,这个广告看着就很难受,有没有什么方法能去掉呢?
首先,我们来判断一下验证码和前面的广告是库作者拼接在一个字符串里,
还是是两个分别的字符串,分别输出
我们输出这个字符串的第0项看看
import ddddocr
ocr=ddddocr.DdddOcr(old=True)
with open("1.jpg", 'rb') as f:
image = f.read()
print(ocr.classification(image)[0])输出:z
这就证明这是两个字符串,不影响正常使用
去除广告
我们按住 Ctrl,把光标移到“import ddddocr” 的ddddocr上,发现ddddocr变蓝了

然后我们单击ddddocr,出来这个界面
这就是ddddocr的代码
我们找到这里
 把这几行代码注释掉,改成 pass
把这几行代码注释掉,改成 pass
再运行刚才的文件,发现输出变成了只有 z4ta
标记验证码
效果图:

可以看到,程序把 Z 、4、T、A 都用红圈圈了出来
程序(请安装opencv)
import ddddocr
import cv2
det = ddddocr.DdddOcr(det=True)
with open("1.jpg", 'rb') as f:
image = f.read()
poses = det.detection(image)
print(poses)
im = cv2.imread("1.jpg")
for box in poses:
x1, y1, x2, y2 = box
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)注意,1.jpg是我们要识别的验证码的图片
源码阅读
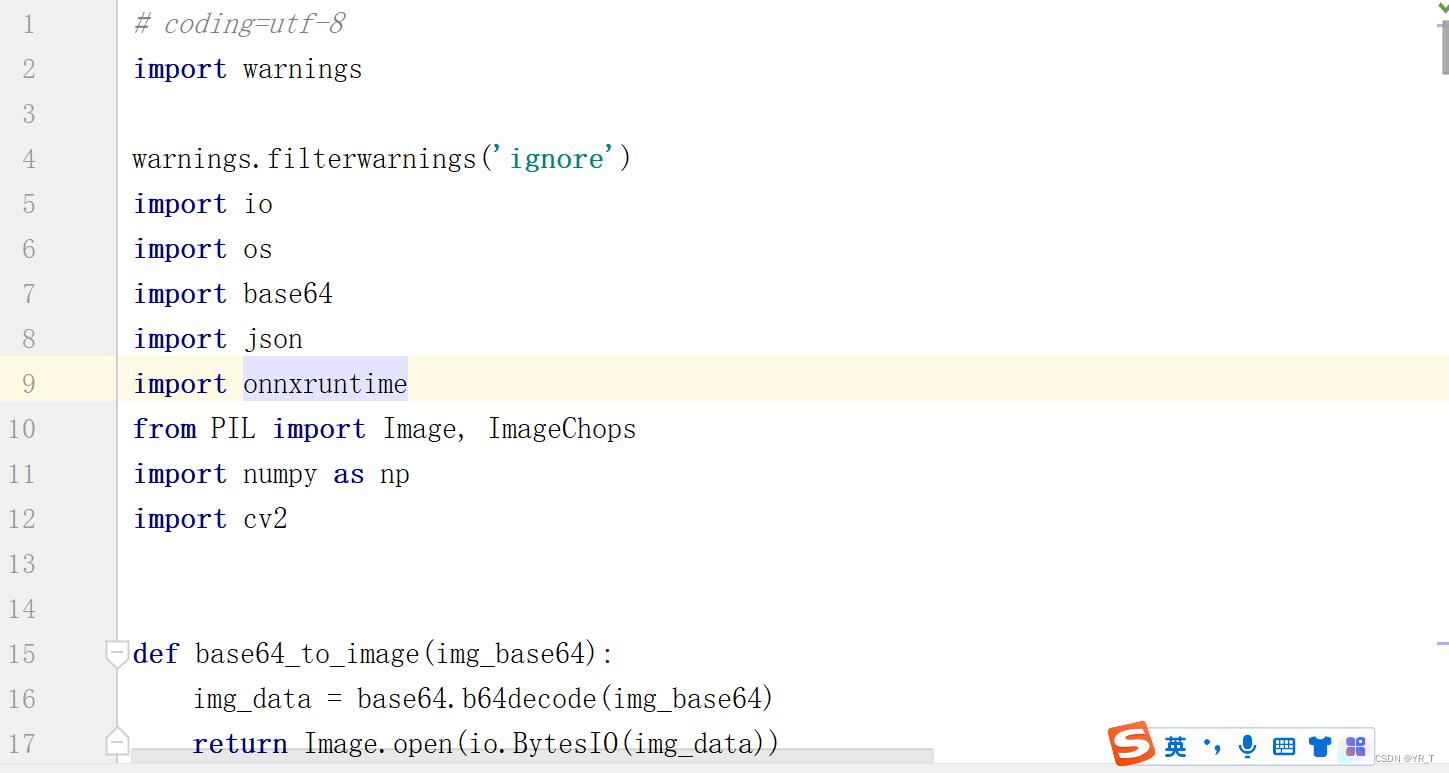
import warnings
warnings.filterwarnings('ignore')
import io
import os
import onnxruntime
from PIL import Image
import numpy as np这里使用onnxruntime模型,使用filterwarnings过滤了可能出现的警告。PIL用于读入图片和缩放,使用numpy转化为矩阵。
class DdddOcr(object):
def __init__(self, use_gpu: bool = False, device_id: int = 0):
self.__graph_path = os.path.join(os.path.dirname(__file__), 'common.onnx')
if use_gpu:
self.__providers = [
('CUDAExecutionProvider',
'device_id': device_id,
'arena_extend_strategy': 'kNextPowerOfTwo',
'cuda_mem_limit': 2 * 1024 * 1024 * 1024,
'cudnn_conv_algo_search': 'EXHAUSTIVE',
'do_copy_in_default_stream': True,
),
]
else:
self.__providers = [
'CPUExecutionProvider',
]
self.__ort_session = onnxruntime.InferenceSession(self.__graph_path, providers=self.__providers)
self.__charset = ["", "掀", ...] # 省略亿点点代码此处定义了Ddddocr类,
| 名字 | 意义 |
|---|---|
self.__graph_path | 模型位置 |
self.__providers | 模型参数 |
self.__ort_session | 模型session |
self.__charset | 字符集 |
... # 上面的代码
def classification(self, img: bytes):
image = Image.open(io.BytesIO(img)) # 使用BytesIO+pillow读入图片
image = image.resize((int(image.size[0] * (64 / image.size[1])), 64), Image.ANTIALIAS).convert('L') # 缩放为验证码大小,转为二值图
image = np.array(image).astype(np.float32) # 转为float32的矩阵
image = np.expand_dims(image, axis=0) / 255.
image = (image - 0.5) / 0.5
ort_inputs = 'input1': np.array([image]) # 设置模型输入
ort_outs = self.__ort_session.run(None, ort_inputs) # 获取结果
result = []
last_item = 0
for item in ort_outs[0][0]: # 遍历模型,获取结果
if item == last_item:
continue
else:
last_item = item
if item != 0:
result.append(self.__charset[item])
return ''.join(result) # 返回result
生成验证码
如果你觉得用别人的验证码不过瘾的话,可以自己做验证码
代码比较简单
from PIL import Image,ImageDraw,ImageFont
import random
def getRandomColor():
r = random.randint(0, 255)
g = random.randint(0, 255)
b = random.randint(0, 255)
return (r,g,b)
def getRandomStr():
num_random = str(random.randint(1,9))
random_upper_alpha = chr(random.randint(65,90))
random_char = random.choice([num_random,random_upper_alpha])
return random_char
image = Image.new('RGB',(120,40),(255,255,255))
draw = ImageDraw.Draw(image)
font = ImageFont.truetype(r'K:\\msyh.ttc',size=24)
for i in range(4):
draw.text((10+i*30,10),getRandomStr(),getRandomColor(),font=font)
width = 120
height = 40
for i in range(5):
x1 = random.randint(0,width)
x2 = random.randint(0,width)
y1 = random.randint(0,height)
y2 = random.randint(0,height)
draw.line((x1,x2,y1,y2),fill=getRandomColor())
for i in range(20):
draw.point([random.randint(0,width),random.randint(0,height)],fill=getRandomColor())
x = random.randint(0,width)
y = random.randint(0,height)
draw.arc((x,y,x+5,y+5),0,90,fill=getRandomColor())
image.save('1.jpg')模拟登录网站
我们可以自己做一个简单的页面(html)
再自己破解。
import unittest
from PIL import Image
from selenium import webdriver
from time import sleep
import ddddocr
class WeChat(unittest.TestCase):
# def __init__(self):
def setUp(self) -> None:
self.driver = webdriver.Chrome()
# 自己的网站
self.driver.get('website.html')
# 全屏打开
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.ocr = ddddocr.DdddOcr()
def test_login_success(self):
# 打开自己的网站会有安全认证
self.driver.find_element('id', 'details-button').click()
self.driver.find_element('id', 'proceed-link').click()
self.driver.find_element('xpath', '//*[@id="layui-layer1"]/div[3]/a').click()
sleep(1)
self.driver.find_element('id', 'account').send_keys('BluetoothHaAdmin')
self.driver.find_element('id', 'password').send_keys('000000')
# 先获取屏幕截图,在找元素,定位大小,通过定位出来的地方截图后使用识别验证码模块,将其
# 以二进制的方式识别后,输出后填写到填写验证码的位置
self.driver.save_screenshot('Login_page.png')
yzm_btn = self.driver.find_element('id', 'id_img')
# 获取图片元素的位置
loc = yzm_btn.location
# 获取图片的宽高
size = yzm_btn.size
# 获取验证码上下左右的位置
left = loc['x']
top = loc['y']
right = (loc['x'] + size['width'])
bottom = (loc['y'] + size['height'])
val = (left, top, right, bottom)
# 打开网页截图
login_pic = Image.open('Login_page.png')
# print(val)
# 通过上下左右的值,去截取验证码
yzm_pic = login_pic.crop(val)
yzm_pic.save('yzm.png')
with open('yzm.png', 'rb') as f:
img_bytes = f.read()
# print (img_bytes)
res = self.ocr.classification(img_bytes)
print("验证码:", res, type(res))
self.driver.find_element('id', 'id_webVerificationCode').send_keys(res)
sleep(1)
self.driver.find_element('id', 'id_loginButton').click()
sleep(12)
self.driver.quit()
if __name__ == '__main__':
ocr = ddddocr.DdddOcr()
wechat = WeChat()
# 点击安全提醒
sleep(12)
#退出
wechat.driver.quit()最后
今天写了一篇长文,大家看了我的文章可能有一些收获
三连必回,其他不多说了了,拜拜!

 创作打卡挑战赛
创作打卡挑战赛
 赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖
以上是关于Python验证码识别和生成(5000字详细实例和概念讲解)的主要内容,如果未能解决你的问题,请参考以下文章