机器学习(20)——循环神经网络
Posted 进击的南方仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习(20)——循环神经网络相关的知识,希望对你有一定的参考价值。
文章目录
1 RNN 的缺点
我在上一篇博客中跟大家一步一步探索了 RNN 模型的网络结构,最后面也介绍了 RNN 的应用场景。但在实际应用中,标准 RNN 训练的优化算法面临一个很大的难题,就是长期依赖问题——由于网络结构的变深使得模型丧失了学习到先前信息的能力,通俗的说,标准的 RNN 虽然有了记忆,但很健忘,也即标准 RNN 只有短时记忆。循环神经网络在处理较长的句子时,往往只能够理解有限长度内的信 息,而对于位于较长范围类的有用信息往往不能够很好的利用起来。我们把这种现象叫做短时记忆。
针对标准 RNN 短时记忆的问题,最直接的想法就是延长这种短时记忆,使得 RNN 可以有效利用较大范围内的训练数据,从而提升性能。这时,一种基于 RNN 改进的新型网络模型——LSTM 该登场了。同时在上篇博客的最后面谈到了 RNN 的梯度消失问题,LSTM 模型可以有效地解决这个问题。
2 LSTM
1997 年,瑞士人工智能科学家 Jürgen Schmidhuber 提出了 长短时记忆网络(Long Short-Term Memory,简称 LSTM)。LSTM 相对于基础的 RNN 网络来说,记忆能力更强,更擅长处理较长的序列信号数据,LSTM 提出后,被广泛应用在序列预测、自然语言处理等任务中,几乎取代了基础的 RNN 模型。
首先回顾一下基础的 RNN 网络结构:

上一个时间戳的状态向量
h
t
−
1
\\boldsymbolh_t-1
ht−1 与当前时间戳的输入
x
t
\\boldsymbolx_t
xt 经过线性变换后,通过激活函数
t
a
n
h
\\boldsymboltanh
tanh 后得到新的状态向量
h
t
\\boldsymbolh_t
ht。相对于基础的 RNN,网络只有一个状态向量
h
t
\\boldsymbolh_t
ht,LSTM 新增了一个状态向量
C
t
\\boldsymbolC_t
Ct,同时引入了 门控(Gate)机制,通过门控单元来控制信息的遗忘和刷新: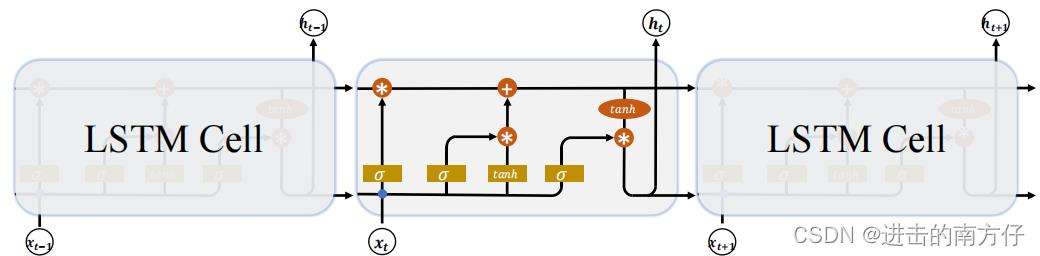
在 LSTM Cell 中,有两个状态向量
c
\\boldsymbolc
c 和
h
\\boldsymbolh
h,其中
c
\\boldsymbolc
c 作为 LSTM 的内部状态向量,可以理解为 LSTM 的 内存状态向量 Memory,而
h
\\boldsymbolh
h 表示 LSTM 的输出向量。相对于基础的 RNN 来说,LSTM 把内部 Memory 和输出分开为两个变量,同时利用三个门控:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)来控制内部信息的流动。
门控机制可以理解为控制数据流通量的一种手段,类比于水阀门:当水阀门全部打开时,水流畅通无阻地通过;当水阀门全部关闭时,水流完全被隔断。在 LSTM 中,阀门开和程度利用门控值向量
g
\\boldsymbolg
g 表示:
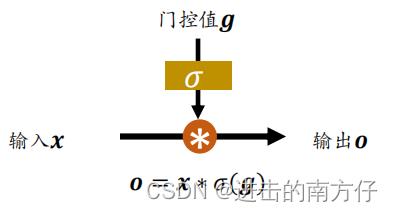
上图中通过
σ
(
g
)
\\boldsymbol\\sigma(g)
σ(g) 激活函数将门控值压缩到
[
0
,
1
]
\\boldsymbol[0, 1]
[0,1] 之间,当
σ
(
g
)
=
0
\\boldsymbol\\sigma(g) = 0
σ(g)=0 时,门控全部关闭,输出
o
=
0
\\boldsymbolo = 0
o=0;当
σ
(
g
)
=
1
\\boldsymbol\\sigma(g) = 1
σ(g)=1 时,门控全部打开,输出
o
=
x
\\boldsymbolo = x
o=x。通过门控机制可以较好地控制数据的流量程度。
注:到此您可以跳转至 3 GUR 阅读完 GUR 的原理之后再回来阅读 LSTM,因 GUR 结构较为简单。
2.1 遗忘门
遗忘门作用于 LSTM 状态向量 c \\boldsymbolc c,用于控制上一个时间戳的记忆 c t − 1 \\boldsymbolc_t - 1 ct−1 对当前时间戳的影响。
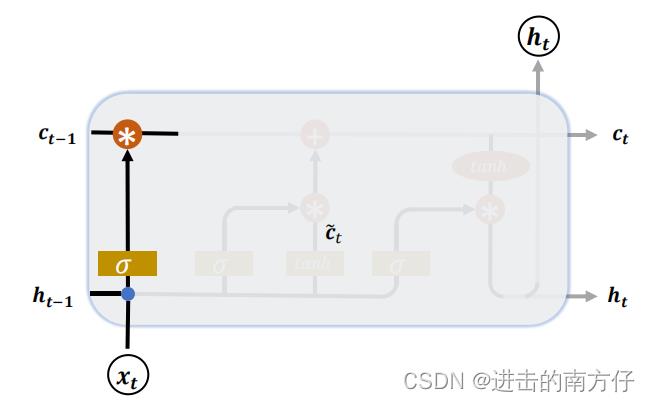
遗忘门的控制变量
g
f
\\boldsymbolg_f
gf 计算过程如下:
g
f
=
σ
(
W
f
[
h
t
−
1
;
x
t
]
+
b
f
)
\\boldsymbolg_f = \\sigma(W_f[h_t- 1;x_t]+b_f)
gf=σ(Wf[ht−1;xt]+bf)
其中
W
f
\\boldsymbolW_f
Wf 和
b
f
\\boldsymbolb_f
bf 为遗忘门的参数张量,可由反向传播算法自动优化,
σ
\\boldsymbol\\sigma
σ 为激活函数,一般使用 Sigmoid 函数。当
g
f
=
1
\\boldsymbolg_f = 1
gf=1 时,遗忘门全部打开,LSTM 接受上一个状态
c
t
−
1
\\boldsymbolc_t-1
ct−1 的所有信息 ;当
g
f
=
0
\\boldsymbolg_f = 0
gf=0 时,遗忘门关闭,LSTM 直接忽略
c
t
−
1
\\boldsymbolc_t-1
ct−1 的所有信息输出为 0 的向量。这也是遗忘门的名字由来。经过遗忘门后,LSTM 的状态向量
c
t
\\boldsymbolc_t
ct 变为
g
f
c
t
−
1
\\boldsymbolg_fc_t-1
gfct−1。
2.2 输入门
输入门用于控制 LSTM 对输入的接收程度。
以上是关于机器学习(20)——循环神经网络的主要内容,如果未能解决你的问题,请参考以下文章
首先通过对当前时间戳的输入
x
t
\\boldsymbolx_t
xt 和上一个时间戳的输出
h
t
−
1
\\boldsymbolh_t - 1
ht−1 做非线性变换得到新的输入向量
c
t
~
\\boldsymbol\\tildec_t
ct~:
c
t
~
=
t
a
n
h
(
W
c
[
h
t
−
1
;
x
t
]
+
b
c
)
\\boldsymbol\\tildec_t = tanh(W_c[h_t -1;x_t] +b_c)
ct~=tanh(Wc[ht−1;xt]+bc)
其中
W
c
\\boldsymbolW_c
Wc 和
b
c
\\boldsymbolb_c
bc 为输入门的参数,需要通过反向传播算法自动优化,
t
a
n
h
\\boldsymboltanh
tanh 为激活函数,用于将输入标准化到
[
−
1
,
1
]
\\boldsymbol[-1,1]
[−1,1] 区间。
c
t
~
\\boldsymbol\\tildec_t
ct~ 并不会全部刷新进入 LSTM 的 Memory,而是通过输入门控制接受输入的量。输入门的控制变量同样来自于输入
x
t
\\boldsymbolx_t
xt 和输出
h
t
−
1
\\boldsymbolh_t - 1
ht−1:
g
i
=
σ
(
W
i
[
h
t
−
1
;
x
t
]
+
b
i
)
\\boldsymbolg_i = \\sigma(W_i[h_t - 1;x_t]+b_i)
gi=σ(Wi[ht−1;xt]+bi)
其中
W
i
\\boldsymbolW_i
Wi 和
b
i
\\boldsymbolb_i
bi 为输入门的参数,可由反向传播算法自动优化,
σ
\\boldsymbol\\sigma
σ 为激活函数,一般使用 Sigmoid 函数。输入门控制变量
g
i
\\boldsymbolg_i
gi 决定了 LSTM 对当前时间戳的新输入
c
t
~
\\boldsymbol\\tildec_t
ct~ 的接受程度:当
g
i