Reactor模型(高并发必备)
Posted 敲代码的Messi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Reactor模型(高并发必备)相关的知识,希望对你有一定的参考价值。
前言
一般我们做服务器,常常是基于线程架构的
也就是thread-based architecture
这种模式可以用下图来描述:
这种方式适合初中级程序员
优点在于结构清晰,逻辑明了,可读性强
但是缺点也是非常明显的:
每个客户端的请求,都需要一个线程来处理
如果有一万个用户,就需要一万个线程来处理
有十万个用户,就需要开十万个线程
暂且不说十万个,单单一万个线程,仅仅是切换这些线程
基本CPU就废了
处了这个问题,还有另外一个问题,就是无法控制算力
比如一百个线程,可能某一刻,一百个线程都在闲着,CPU闲到发慌
也可能下一刻所有的线程都需要忙起来,CPU瞬间原地爆炸
而且这种情况完全不受服务器控制
也难以预测,完全由用户的行为来主导
注:线程之间会有恶性竞争,比如说,这个客户端连接到一半,又被其他请求挤下去了。
基于上面这种方式的问题
我们有了事件驱动架构(event-driven architecture)
这种架构把要使用CPU的内容定义为一个事件
比如网络编程中的客户端接入、数据读取、数据发送、连接关闭
当有客户端接入的事件发生的时候
我们就安排线程来处理接入
处理完了,就将该事件移出线程,等待其他事件的发生
这种方式有很多好处
比如我们可以控制CPU的利用率
还是上面那个例子,一百个用户连上来
如果某一刻一百个人都在做请求
这个时候我们可以指定几个线程来处理这些请求
没有处理到的用户会在一个事件队列中等候处理
这样不会出现一百个用户同时被处理,但是每个都无法很好的处理(没有了恶行竞争)
Reactor模型
基于事件驱动架构的模式就是Reactor模式
这种模式的典型情况如下图
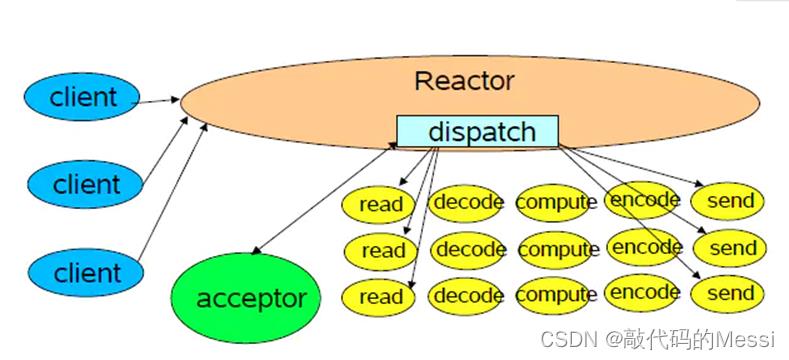
用户来了,reactor(反应堆)会将事件分发给接收、读取、解码、计算、编码、发送各个处理模块
这些模块没有单独的执行权限
全部靠reactor来分派线程,进而执行内容
这种方式,除非没有任何事件发生
否则线程就一直都会干活
但是再多事件发生,也只会有指定数量的线程在干活
如果硬件性能差,则把数量减少一些
如果硬件性能好,则把线程数量增加一些
整个服务器的性能峰值就可以控制在手上了。
注:我们还可以将将一些功能扔到另一台服务器去做,这就初步形成了一个分布式架构。
在这种反应堆模式中,几个概念是需要强调的
Handle(句柄)
具体的事件源,可以是文件描述符、网络套接字等等
Synchronous Event Demultiplexer同步事件分离器
分离器一般是系统的接口
比如select、poll或者epoll函数
这些东西将程序的状态由事件触发状态切换到事件处理状态
比如select会阻塞,直到某个select关注的handle产生事件
Event Handler事件处理器
这个元素里面一般包含一个回调函数
当handle上产生事件的时候
这个回调函数则可能被执行
Concrete Event Handler具体的事件处理器
注意,这个一般是事件处理器的子类
会实现具体的回调,完成业务逻辑
Initiation Dispatcher初始分发器
提供注册、删除与转发event handler的方法
当同步事件分离器(Synchronous Event Demultiplexer)发现某个handle上有事件的时候
就会通知初始分发器(本概念)来调用事件处理器来处理事件
工作流程
用户需要在初始分发器中注册具体的事件处理器
说明在什么事件发生的时候,调用本具体的事件处理器
注意,注册的时候,也要事件处理器绑定好对应的句柄
注册完成后,初始分发器会开启事件循环,然后使得同步事件分离器来等待事件的发生
当某个句柄上产生的事件为就绪的时候
同步事件分离器就会通知初始化分发器
初始化分发器会调用事件处理器的回调:
通过事件来定位对应的句柄和句柄回调方法
具体的事件处理器会调用器内部关联的回调方法来处理具体的事件。
以上是关于Reactor模型(高并发必备)的主要内容,如果未能解决你的问题,请参考以下文章