Deep Learning Recommendation Model(DLRM)
Posted zhiyong_will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep Learning Recommendation Model(DLRM)相关的知识,希望对你有一定的参考价值。
1. 概述
DLRM(Deep Learning Recommendation Model)[1]是Facebook在2019年提出的用于处理CTR问题的算法模型,与传统的CTR模型并没有太大的差别,文章本身更注重的是工业界对于深度模型的落地,在文中介绍了很多深度学习在实际落地过程中的细节,包括如何高效训练。在此我们更多的是关注模型本身,尝试揭开DLRM模型的本质。在DLRM模型中,突出解决两个问题:
- 第一,如何处理离散特征。CTR的训练样本中包含了大量的离散的类别特征,这样的数据是不能直接放入到深度学习模型中,在DLRM中,通过Embedding层将离散的特征转化成稠密的特征;
- 第二,如何做特征交叉。特征交叉对于CTR问题的求解具有重要的作用,在DLRM模型中,模仿着FM算法中的做法,对向量两两做点积。
2. 算法原理
2.1. DLRM模型的网络结构
DLRM模型的网络结构如下图所示:
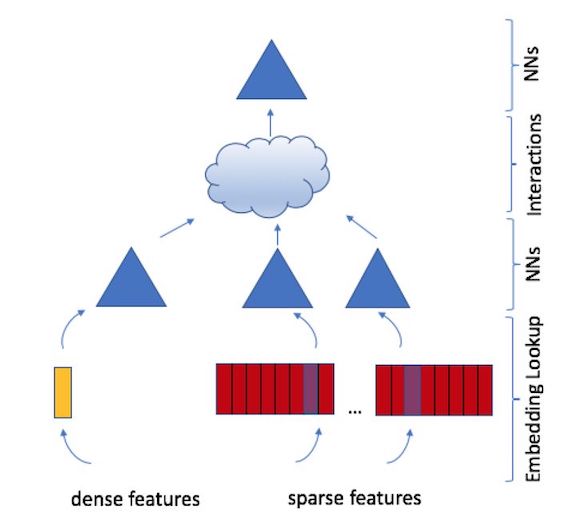
在DLRM模型的网络结构中,从下而上,包括了输入层,Embedding层,特征交叉层,以及FNN输出层。
2.2. DLRM模型的优化点
2.2.1. 特征处理
在CTR问题中,通常特征包括两种类型,第一类为类别、id类的离散特征,对于这类特征通常是利用one-hot编码对其进行编码,生成稀疏特征;第二类为数值型的连续特征。对于第一类的离散特征,通过one-hot编码后会变得特别稀疏,深度学习模型是不适合从稀疏数据中学习的,通常的做法是通过Embedding将其映射成一个稠密的连续值。假设one-hot编码后的向量是 e i e_i ei,向量中除了第 i i i个位置为1外,通过Embedding后得到的embedding向量 w i w_i wi为:
w i T = e i T W w_i^T=e_i^TW wiT=eiTW
其中, W ∈ R m × d W\\in \\mathbbR^m\\times d W∈Rm×d。而对于连续特征,DLRM中选择的处理方法是通过MLP多层感知机将所有的连续特征转化成一个与离散特征同样维度的embedding向量,如图中的黄色部分。
2.2.2. 特征交叉
通过Embedding层后,所有的特征,包括离散特征和连续特征,可以通过MLP神经网络层做进一步转换,如图中的三角部分。经过MLP处理后进入到interaction特征交叉层。从文中的介绍可知,在interaction层,首先会将所有的embedding结果两两做点积,以此实现特征的交叉。然后将交叉后的特征和之前embedding结果组合在一起,以此同时实现了线形特征和交叉特征。最终通过MLP得到最终的输出。
3. 总结
在DLRM模型中,没有太多复杂的操作,都是一些基本的操作流程,这一点也比较符合工业界的思维。这里没有介绍工程实践方面的细节,详细的可以参见参考文献[1]。
参考文献
[1] Naumov M, Mudigere D, Shi H J M, et al. Deep learning recommendation model for personalization and recommendation systems[J]. arXiv preprint arXiv:1906.00091, 2019.
[2] DLRM: An advanced, open source deep learning recommendation model
以上是关于Deep Learning Recommendation Model(DLRM)的主要内容,如果未能解决你的问题,请参考以下文章
Deep Learning(深度学习)之Deep Learning的基本思想
Deep Learning(深度学习)之Deep Learning的常用模型或者方法