数据集成变换与规约1
Posted 山城棒棒儿军
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据集成变换与规约1相关的知识,希望对你有一定的参考价值。
目录
- 6. 1 数据集成
- 6.2 数据变换
- 6.3 数据规约
- 6.4 案例——中国篮球运动员的基本信息分析
本博客所涉及的jupyter notebook及数据资料请在百度网盘下载
6. 1 数据集成
6.1.1 数据集成概述
数据分析中需要的数据往往来自不同的途径,这些数据的格式、特点、质量千差万别,给数据分析或挖掘增加了难度。为提高数据分析的效率,多个数据源的数据需要合并到一个数据源,形成一致的数据存储,这一过程就是数据集成。
在数据集成期间可能会面临很多问题,包括实体识别、冗余属性识别、元组重复、数据值冲突等问题!
-
实体识别:
实体识别指从不同数据源中识别出现实世界的实体,主要用于统一不同数据源的矛盾之处,常见的矛盾包括同名异义、异名同义、单位不统一等! -
冗余属性识别:
冗余属性是数据集成期间极易产生的问题,这一问题主要是因为同一属性多次出现、同一属性命名方式不一致造成的。 -
元组重复:
元组重复是数据集成期间另一个容易产生的数据冗余问题,这一问题主要是因为录入错误或未及时更新造成的。
由于存在如上问题,数据集成之后可能需要经过数据清理,以便清除可能存在的实体识别、冗余属性识别和元组重复问题。
pandas中有关数据集成的操作是合并数据,并为该操作提供了丰富的函数或方法。
6.1.2 合并数据
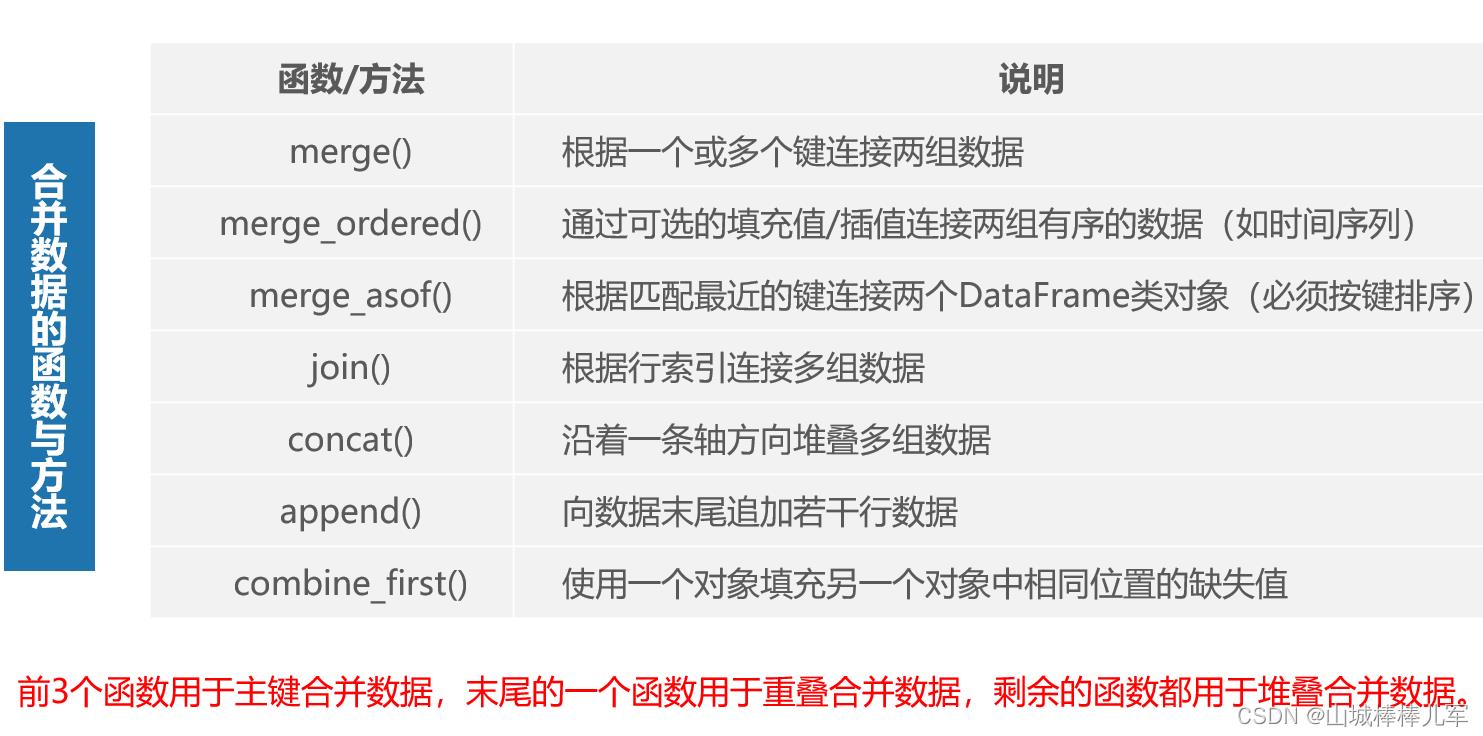
6.1.2.1 pandas中用于合并数据的函数与方法
pandas中内置了许多能轻松地合并数据的函数与方法,通过这些函数与方法可以将Series类对象或DataFrame类对象进行符合各种逻辑关系的合并操作,合并后生成一个整合的Series或DataFrame类对象。
6.1.2.2 主键合并
主键合并数据类似于关系型数据库的连接操作,主要通过指定一个或多个键将两组数据进行连接,通常以两组数据中重复的列索引为合并键。
6.1.2.2.1 pd.merger()
- pd.merge()的语法格式:
pd.merge(left, # 待合并的2个数据框
right,
how='inner', # ‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’
on=None, # 连接的键,默认是相同的键
left_on=None, # 指定不同的连接字段:键不同,但是键的取值有相同的内容
right_on=None,
left_index=False, # 根据索引来连接
right_index=False,
sort=False, # 是否排序
suffixes=('_x', '_y'), # 改变后缀
copy=True,
indicator=False, # 显示字段来源
validate=None)
-
参数的具体解释为:
-
left、right:表示参与合并的Series类对象或DataFrame类对象
-
how:数据合并的方式,有5种:‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’, 默认是 ‘inner’
-
1、left:左连接,保留left的全部数据,类比于SQL的left join;
-
2、right:右连接,保留right的全部数据,类比于SQL的right join
-
3、outer:全连接功能,left与right的数据都将被保留,类似SQL的full outer join
-
4、inner:基于left合right的共有键的交叉连接,类比于SQL的inner join
-
5、cross:创建两个数据帧DataFrame的笛卡尔积,默认保留左边的顺序
-
-
on:连接的列属性;默认是两个DataFrame的相同字段
-
left_on/right_on:指定两个不同的键进行联结
-
left_index、right_index:通过索引进行合并
-
suffixes:指定我们自己想要的后缀
-
indictor:显示字段的来源
-
-
pd.merge()实例:
# 模拟数据
import pandas as pd
df_left = pd.DataFrame('key':['K0','K1','K2','K4'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'])
df_right = pd.DataFrame('key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'])
df_left
| key | A | B | |
|---|---|---|---|
| 0 | K0 | A0 | B0 |
| 1 | K1 | A1 | B1 |
| 2 | K2 | A2 | B2 |
| 3 | K4 | A3 | B3 |
df_right
| key | C | D | |
|---|---|---|---|
| 0 | K0 | C0 | D0 |
| 1 | K1 | C1 | D1 |
| 2 | K2 | C2 | D2 |
| 3 | K3 | C3 | D3 |
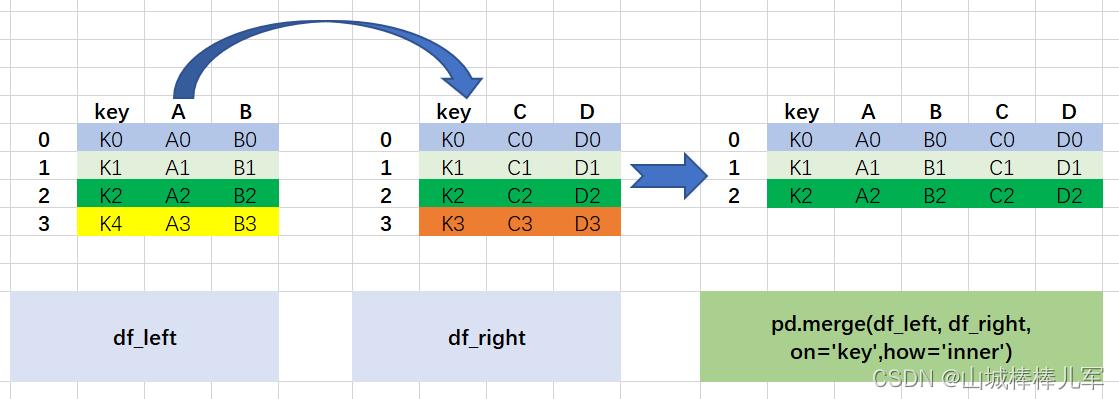
1. 内连接----共有键部分的连接
# 以key为主键,采用内连接的方式合并数据
result = pd.merge(df_left, df_right, on='key',how='inner')
result
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
图解过程如下:
- 两个数据框df_left、df_right有相同的字段key
- 默认是通过相同的字段(键)进行关联,取出键中相同的值(K0,K1,K2),若每个键的记录要全部显示
# 默认参数情况下的连接及为内连接
result = pd.merge(df_left,df_right)
result
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
# 也可以采用dataFrame对象的方法的方式调用
df_left.merge(df_right)
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
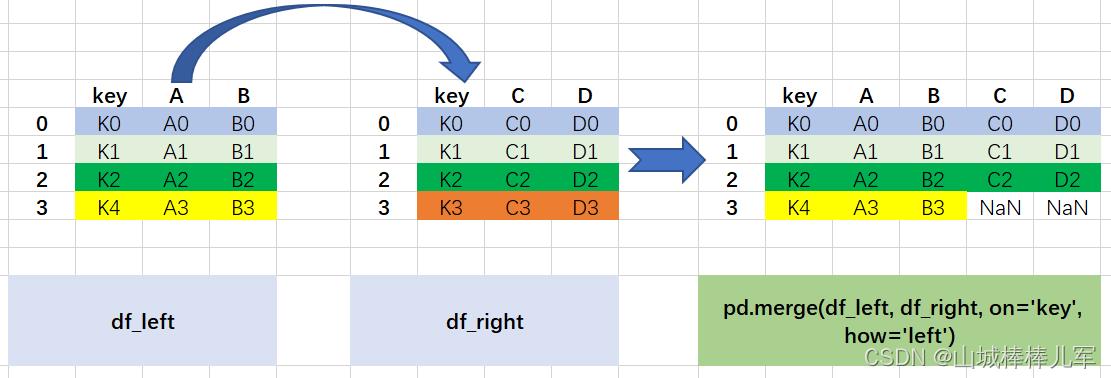
2. 左外连接----以左数据为主,保留左侧全部的连接
# 以key为主键,采用左外连接的方式合并数据
result = pd.merge(df_left, df_right, on='key', how='left')
result
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
| 3 | K4 | A3 | B3 | NaN | NaN |
# 类似的
result = df_left.merge(df_right,on='key',how='left')
result
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
| 3 | K4 | A3 | B3 | NaN | NaN |
图解过程如下:
- 以左边数据框中的键(K0,K1,K2,K4)为基准;
- 如果左边存在(K4)但是右边不存在(K4),则右边用NaN表示
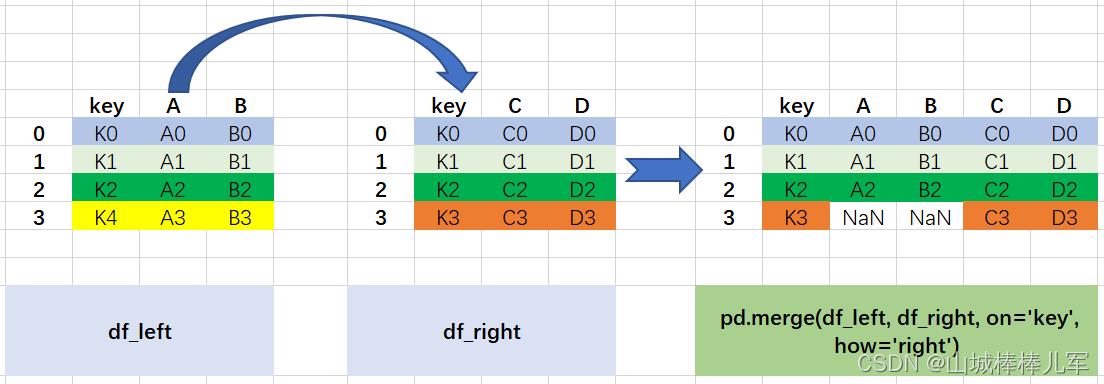
3. 右外连接----以右数据为主,保留右侧全部的连接
# 以key为主键,采用右外连接的方式合并数据
result = pd.merge(df_left, df_right, on='key', how='right')
result
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
| 3 | K3 | NaN | NaN | C3 | D3 |
图解过程如下:
- 以右边数据框中的键(K0,K1,K2,K3)为基准;
- 如果右边存在(K3)但是右边不存在(K3),则左边用NaN表示
4. 全外连接----左右两侧数据都完全保留的连接
# 以key为主键,采用全外连接的方式合并数据
result = pd.merge(df_left, df_right, on='key', how='outer')
result
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
| 3 | K4 | A3 | B3 | NaN | NaN |
| 4 | K3 | NaN | NaN | C3 | D3 |
图解过程如下:
outer称之为外连接,在拼接的过程中会取两个数据框中键的并集进行拼接
- 外连接,取出全部交集键的并集。例子中是user的并集
- 如果某个键在某个数据框中不存在数据,则为NaN
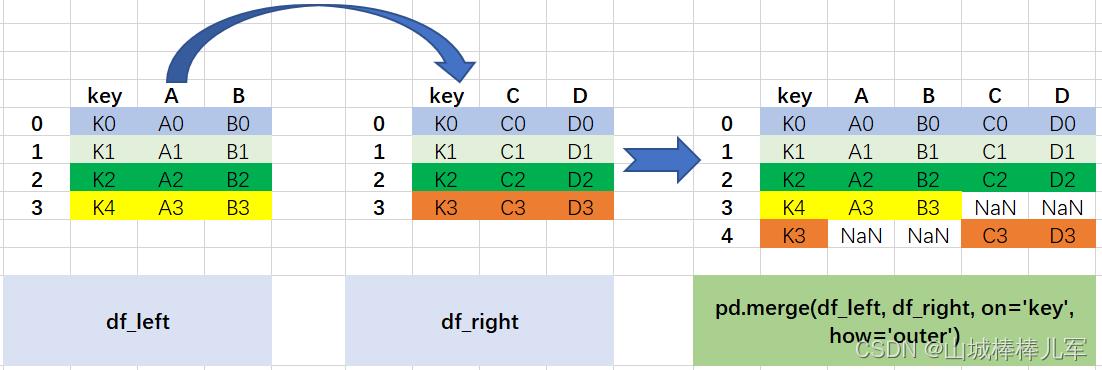
5. 笛卡尔积----两个数据框中的数据交叉匹配,出现n1*n2的数据量
# 以key为主键,采用笛卡尔积连接的方式合并数据
result = pd.merge(df_left, df_right, how='cross')
print(result)
key_x A B key_y C D
0 K0 A0 B0 K0 C0 D0
1 K0 A0 B0 K1 C1 D1
2 K0 A0 B0 K2 C2 D2
3 K0 A0 B0 K3 C3 D3
4 K1 A1 B1 K0 C0 D0
5 K1 A1 B1 K1 C1 D1
6 K1 A1 B1 K2 C2 D2
7 K1 A1 B1 K3 C3 D3
8 K2 A2 B2 K0 C0 D0
9 K2 A2 B2 K1 C1 D1
10 K2 A2 B2 K2 C2 D2
11 K2 A2 B2 K3 C3 D3
12 K4 A3 B3 K0 C0 D0
13 K4 A3 B3 K1 C1 D1
14 K4 A3 B3 K2 C2 D2
15 K4 A3 B3 K3 C3 D3
笛卡尔积的图解过程如下:
- 出现的数据量是4*2,userid下面的数据交叉匹配
- 在最终结果中相同的字段userid为了避免混淆,会带上默认的后缀_x、_y
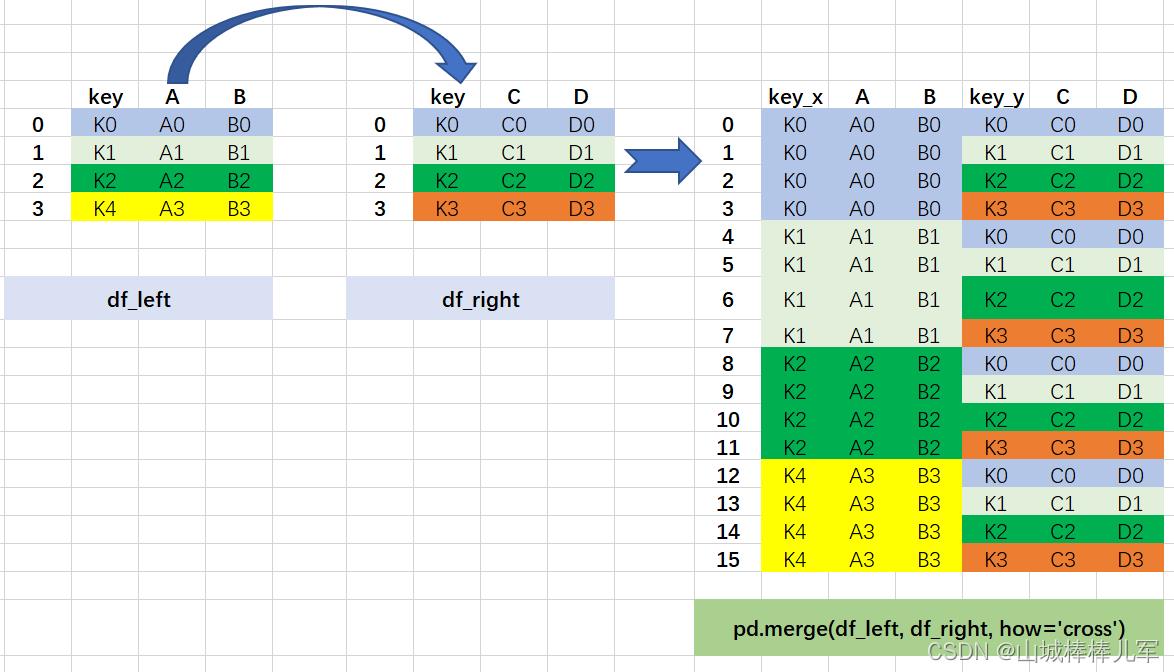
6.1.2.2.2 pd.merge_ordered()
使用可选的填充/插值对有序数据执行合并。专为时间序列数据等有序数据而设计。
- pd.merge_ordered()语法格式:
pandas.merge_ordered(left,
right,
on=None,
left_on=None,
right_on=None,
left_by=None,
right_by=None,
fill_method=None,
suffixes=('_x', '_y'),
how='outer')
-
参数解释:
-
left: 用于连接的 左DataFrame
-
right: 用于连接的 右DataFrame
-
on: 连接关键字。必须 同时存在于 左DataFrame、右DataFrame
-
left_on: 左DataFrame 中用于连接的关键字
-
right_on: 右DataFrame 中用于连接的关键字
-
left_by: 对 左DataFrame 进行分组的关键字
-
right_by: 对 右DataFrame 进行分组的关键字
-
fill_method: 对缺失数据填充的值
-
suffixes: 连接后,同时存在于 左DataFrame、右DataFrame 中的字段,添加的后缀名
-
how: 连接方式。默认为 外连接
-
-
注意:
-
使用参数 on 时,不能同时使用 “left_on” 或 “right_on”
-
left_on 与 right_on 必须同时存在
-
如果 on、left_on 、right_on 的参数值均为空时,默认以 同时存在于两个 DataFrame 中的列,为连接关键字。
如果不存在共同列,将会报错:pandas.errors.MergeError: No common columns to perform merge on. -
left_by 与 right_by 不能同时存在
-
pd.merge_ordered()实例:
- 构建实例数据
df1 = pd.DataFrame(
"key": ["a", "c", "e", "a", "c", "e"],
"lvalue": [1, 2, 3, 1, 2, 3],
"group": ["a", "a", "a", "b", "b", "b"]
)
df2 = pd.DataFrame("key": ["b", "c", "d"], "rvalue": [1, 2, 3])
df1
| key | lvalue | group | |
|---|---|---|---|
| 0 | a | 1 | a |
| 1 | c | 2 | a |
| 2 | e | 3 | a |
| 3 | a | 1 | b |
| 4 | c | 2 | b |
| 5 | e | 3 | b |
df2
| key | rvalue | |
|---|---|---|
| 0 | b | 1 |
| 1 | c | 2 |
| 2 | d | 3 |
# df1 df2
# key lvalue group key rvalue
# 0 a 1 a 0 b 1
# 1 c 2 a 1 c 2
# 2 e 3 a 2 d 3
# 3 a 1 b
# 4 c 2 b
# 5 e 3 b
1. 如果 left_by 与 right_by 均为空,等价于 merge
pd.merge_ordered(df1, df2).sort_values(by=["key", "lvalue"], ignore_index=True)
| key | lvalue | group | rvalue | |
|---|---|---|---|---|
| 0 | a | 1.0 | a | NaN |
| 1 | a | 1.0 | b | NaN |
| 2 | b | NaN | NaN | 1.0 |
| 3 | c | 2.0 | a | 2.0 |
| 4 | c | 2.0 | b | 2.0 |
| 5 | d | NaN | NaN | 3.0 |
| 6 | e | 3.0 | a | NaN |
| 7 | e | 3.0 | b | NaN |
等价于如下:
pd.merge(df1, df2, how="outer").sort_values(by=["key", "lvalue"], ignore_index=True)
| key | lvalue | group | rvalue | |
|---|---|---|---|---|
| 0 | a | 1.0 | a | NaN |
| 1 | a | 1.0 | b | NaN |
| 2 | b | NaN | NaN | 1.0 |
| 3 | c | 2.0 | a | 2.0 |
| 4 | c | 2.0 | b | 2.0 |
| 5 | d | NaN | NaN | 3.0 |
| 6 | e | 3.0 | a | NaN |
| 7 | e | 3.0 | b | NaN |
2. 如果 left_by 或 right_by 不为空,会先按这个参数值对 DataFrame 进行分组,将分组后的 DataFrame 再进行连接
pd.merge_ordered(df1, df2, left_by="group")
#第一步:将 df1 根据 group 进行分组
# 第二步:将分组后的 df1 中每一组的数据,通过连接关键字 key 与 df2 进行连接
| key | lvalue | group | rvalue | |
|---|---|---|---|---|
| 0 | a | 1.0 | a | NaN |
| 1 | b | NaN | a | 1.0 |
| 2 | c | 2.0 | a | 2.0 |
| 3 | d | NaN | a | 3.0 |
| 4 | e | 3.0 | a | NaN |
| 5 | a | 1.0 | b | NaN |
| 6 | b | NaN | b | 1.0 |
| 7 | c | 2.0 | b | 2.0 |
| 8 | d | NaN | b | 3.0 |
| 9 | e | 3.0 | b | NaN |
pd.merge_ordered(df1, df2, right_by="rvalue")
# 第一步:将 df2 根据 rvalue 进行分组
# 第二步:将分组后的 df2 中每一组的数据,通过连接关键字 key 与 df1 进行连接
| key | lvalue | group | rvalue | |
|---|---|---|---|---|
| 0 | a | 1.0 | a | 1 |
| 1 | a | 1.0 | b | 1 |
| 2 | b | NaN | NaN | 1 |
| 3 | c | 2.0 | a | 1 |
| 4 | c | 2.0 | b | 1 |
| 5 | e | 3.0 | a | 1 |
| 6 | e | 3.0 | b | 1 |
| 7 | a | 1.0 | a | 2 |
| 8 | a | 1.0 | b | 2 |
| 9 | c | 2.0 | a | 2 |
| 10 | c | 2.0 | b | 2 |
| 11 | e | 3.0 | a | 2 |
| 12 | e | 3.0 | b | 2 |
| 13 | a | 1.0 | a | 3 |
| 14 | a | 1.0 | b | 3 |
| 15 | c | 2.0 | a | 3 |
| 16 | c | 2.0 | b | 3 |
| 17 | d | NaN | NaN | 3 |
| 18 | e | 3.0 | a | 3 |
| 19 | e | 3.0 | b | 3 |
3. 如果,“left_by 或 right_by 的值” 与 “连接关键字” 相同,那无论是什么连接方式,结果都一样
pd.merge_ordered(df1, df2, left_by="key")
| key | lvalue | group | rvalue | |
|---|---|---|---|---|
| 0 | a | 1 | a | NaN |
| 1 | a | 1 | b | NaN |
| 2 | c | 2 | a | 2.0 |
| 3 | c | 2 | b | 2.0 |
| 4 | e | 3 | a | NaN |
| 5 | e | 3 | b | NaN |
pd.merge_ordered(df1, df2, left_by="key", how="inner")
| key | lvalue | group | rvalue | |
|---|---|---|---|---|
| 0 | a | 1 | a | NaN |
| 1 | a | 1 | b | NaN |
| 2 | c | 2 | a | 2.0 |
| 3 | c | 2 | b | 2.0 |
| 4 | e | 3 | a | NaN |
| 5 | e | 3 | b | NaN |
pd.merge_ordered(df1, df2, left_by="key", how="right")
| key | lvalue | group | rvalue | |
|---|---|---|---|---|
| 0 | a | 1 | a | NaN |
| 1 | a | 1 | b | NaN |
| 2 | c | 2 | a | 2.0 |
| 3 | c | 2 | b | 2.0 |
| 4 | e | 3 | a | NaN |
| 5 | e | 3 | b | NaN |
6.1.2.2.3 pd.merge_asof()
pandas 的 merge_asof() 类似于有序的LEFT JOIN,只是我们在最近的键上匹配,而不是相等键。
- pd.merge_asof()语法格式:
pandas.merge_asof(left,
right,
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
by=None,
left_by=None,
right_by=None,
suffixes=(‘_x’, ‘_y’),
tolerance=None,
allow_exact_matches=True,
direction=’backward’, )
-
参数说明:
- left, right: DataFrame
- on:标签,要加入的字段名称。必须在两个DataFrame中都找到。
- left_on:标签,要在左侧DataFrame中加入的字段名称。
- right_on:标签,要在右侧DataFrame中加入的字段名称。
- left_index:布尔值,使用左侧DataFrame的索引作为连接键。
- right_index:布尔值,使用正确的DataFrame的索引作为连接键。
-
pd.merge_asof()实例:
# importing package
import pandas
# creating data
left = pandas.DataFrame('a':[1, 5, 10],
'left_val':['a', 'b', 'c'])
right = pandas.DataFrame('a':[1, 2, 3, 6, 7],
'right_val':[1, 2, 3, 6, 7])
# view data
print(left)
print(right)
# applying merge_asof on data
print(pandas.merge_asof(left, right, on='a'))
print(pandas.merge_asof(left, right, on='a',allow_exact_matches=False))
a left_val
0 1 a
1 5 b
2 10 c
a right_val
0 1 1
1 2 2
2 3 3
3 6 6
4 7 7
a left_val right_val
0 1 a 1
1 5 b 3
2 10 c 7
a left_val right_val
0 1 a NaN
1 5 b 3.0
2 10 c 7.0
6.1.2.3 堆叠合并数据
- dataframe.join(): 根据行索引连接多组数据
- pd.concat(): 沿着某个轴方向堆叠多组数据
- dataframe.append(): 向数据末尾追加若干行数据
6.1.2.3.0 构建数据
import pandas as pd
import numpy as np
df1 = pd.DataFrame(
"姓名":["小明","小红","小周"],
"年龄":[18,24,20]
)
df1
| 姓名 | 年龄 | |
|---|---|---|
| 0 | 小明 | 18 |
| 1 | 小红 | 24 |
| 2 | 小周 | 20 |
df2 = pd.DataFrame(
"姓名":["小孙","小芳"],
"年龄":[25,19]
)
df2
| 姓名 | 年龄 | |
|---|---|---|
| 0 | 小孙 | 25 |
| 1 | 小芳 | 19 |
df3 = pd.DataFrame(
"地址":["深圳","广州","珠海"],
"成绩":[600,630,598]
)
df3
| 地址 | 成绩 | |
|---|---|---|
| 0 | 深圳 | 600 |
| 1 | 广州 | 630 |
| 2 | 珠海 | 598 |
df4 = pd.DataFrame(
"地址":["深圳","广州","东莞"],
"爱好":["乒乓球","羽毛球","高尔夫"]
)
df4
| 地址 | 爱好 | |
|---|---|---|
| 0 | 深圳 | 乒乓球 |
| 1 | 广州 | 羽毛球 |
| 2 | 东莞 | 高尔夫 |
df5 = pd.DataFrame(
"地址":["深圳","广州","东莞","上海","北京"],
"爱好":["乒乓球","羽毛球","高尔夫","跑步","健身"]
)
df5
| 地址 | 爱好 | |
|---|---|---|
| 0 | 深圳 | 乒乓球 |
| 1 | 广州 | 羽毛球 |
| 2 | 东莞 | 高尔夫 |
| 3 | 上海 | 跑步 |
| 4 | 北京 | 健身 |
6.1.2.3.1 pd.concat()
解决两个表或者多个表按照纵向或者横向拼接。
- pd.concat()的语法格式:
pandas.concat(objs, # 合并对象
axis=0, # 合并方向,默认是0纵轴方向
join='outer', # 合并取的是交集inner还是并集outer
ignore_index=False, # 合并之后索引是否重新
keys=None, # 在行索引的方向上带上原来数据的名字;主要是用于层次化索引,可以是任意的列表、数组、元组或者列表数组
levels=None, # 指定用作层次化索引各级别上的索引,如果是设置了keys
names=None, # 行索引的名字,列表形式
verify_integrity=False, # 检查行索引是否重复;有则报错
sort=False, # 对非连接的轴进行排序
copy=True # 是否进行深拷贝
)
-
pd.concat()的参数详细说明:
- objs:Series,DataFrame或Panel对象的序列或映射。如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文)。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。
- axis:0,1,…,默认为0。沿着连接的轴。
- join:‘inner’,‘outer’,默认为“outer”。如何处理其他轴上的索引。outer为联合和inner为交集。
- ignore_index:boolean,default False。如果为True,请不要使用并置轴上的索引值。结果轴将被标记为0,…,n-1。如果要连接其中并置轴没有有意义的索引信息的对象,这将非常有用。注意,其他轴上的索引值在连接中仍然受到尊重。
- join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。
- keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。
- levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。
- names:list,default无。结果层次索引中的级别的名称。
- verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。
- copy:boolean,default True。如果为False,请勿不必要地复制数据。
-
pd.concat()使用实例:
- 根据实际数据调整合并的方向,默认是axis=0
- 某个数据库中不存在的数据,用NaN代替
- ignore_index是否保留原表索引,默认保留,为 True 会自动增
以上是关于数据集成变换与规约1的主要内容,如果未能解决你的问题,请参考以下文章