hadoop hdfs的默认目录问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop hdfs的默认目录问题相关的知识,希望对你有一定的参考价值。
在初始化hadoop时会提示 Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted,但是我在用hadoop命令创建文件夹时又显示是在/user/hadoop目录下,这两个目录到底是什么啊,有什么区别。
frostfish425说的是对的!/user/hadoop是安装目录,就是说你hadoop相关的配置和代码都是放在这个位置,这个你自己定就可以了,但是要注意你配置文件和环境变量中的相关配置都要相应的发生改变。而/tmp/hadoop-hadoop/dfs/name是你配置的hdfs目录,也就是数据存放目录,在hdfs-site.xml中配置的,当然你也可以改变这个目录!这个目录挂载的磁盘要足够大,不然数据存放不下,你初始化的时候报的这个Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted其实就是在/tmp/hadoop-hadoop/dfs这个目录下创建了name目录,意思就是告诉你,数据存放目录已经创建成功了! 参考技术A 能贴个图,说详细些么乍看 /user/hadoop/ 像是你的hadoop安装目录,/tmp/hadoop-hadoop/dfs/name是hdfs的路径
大数据学习知识点总结关于Hadoop|HDFS|MapReduce的一些问题与解答
1、如何解除Hadoop系统的安全模式?
答:
(1)修改dfs.safemode.threshold.pct为一个比较小的值,默认缺省是0.999f。
在hadoop的安装目录中的hdfs-site.xml 加修改的配置项,默认的值是float类型,设置一个较小的数值。
<property>
<name>dfs.safemode.threshold.pct</name>
<value>0.999f</value>
<description>
Specifies the percentage of blocks that should satisfy
the minimal replication requirement defined by
dfs.replication.min.
Values less than or equal to 0 mean not to wait for any particular
percentage of blocks before exiting safemode.
Values greater than 1 will make safe mode permanent.
</description>
</property>
(2)hadoop dfsadmin -safemode leave命令强制离开
用户可以通过dfsadmin -safemode value 来操作安全模式,参数value的说明如下:
- enter - 进入安全模式
- leave - 强制NameNode离开安全模式
- get - 返回安全模式是否开启的信息
- wait - 等待,一直到安全模式结束。
两种方法对比:
方法一:可以一劳永逸,但是有风险。
方法二:需要在每次重启hdfs集群的时候都要输入。
2、为什么HDFS不适合低延迟数据访问?
答:
Hadoop 完全是批处理系统, 旨在存储和分析结构化, 非结构化和半结构化数据。
Hadoop 的 map / reduce 框架相对较慢,因为它旨在支持不同的格式,结构和大量数据。
我们不应该说 HDFS 较慢,因为 HBase no-sql 数据库和基于 MPP 的数据源(例如 Impala,Hawq)位于 HDFS 上。这些数据源 Action 更快,因为它们不遵循mapreduce 执行来进行数据检索和处理。
仅由于基于映射/归约的执行的性质而导致出现速度慢,在这种情况下,它会生成大量中间数据,在节点之间交换大量数据,从而导致巨大的磁盘 IO 延迟。此外, 它必须将大量数据保留在磁盘中以在阶段之间进行同步,以便它可以支持从故障中恢复作业。同样,mapreduce 中也没有办法将全部/子集数据缓存在内存中。
3、为什么HDFS无法高效存储大量小文件?
答:
因为Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150字节左右的空间,所以,如果你有100万个文件,每一个占据一个Block,你就至少需要300MB内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于当前的硬件水平来说就没法实现了。还有一个问题就是,因为Map task的数量是由splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Maptask,线程管理开销将会增加作业时间。
大量的小文件,也会影响 NameNode 的寻址时间:
(1)小文件过多,会过多占用 namenode 的内存,并浪费 block。文件的元数
据(包括文件被分成了哪些 blocks,每个 block 存储在哪些服务器的哪个 block
块上) ,都是存储在 namenode 上的。
HDFS 的每个文件、目录、数据块占用 150B,因此 300M 内存情况下,只能存储
不超过 300M/150=2M 个文件/目录/数据块的元数据
- dataNode 会向 NameNode 发送两种类型的报告: 增量报告和全量报告。
- 增量报告是当dataNode接收到block或者删除block时, 会向nameNode
报告。 - 全量报告是周期性的,NN 处理 100 万的 block 报告需要 1s 左右,这 1s
左右 NN 会被锁住,其它的请求会被阻塞
(2)文件过小,寻道时间大于数据读写时间,这不符合 HDFS 的设计:
HDFS 为了使数据的传输速度和硬盘的传输速度接近, 则设计将寻道时间 (Seek)相对最小化,将 block 的大小设置的比较大,这样读写数据块的时间将远大于寻址时间,接近于硬盘的传输速度。
HDFS 天生就是为存储大文件而生的, 一个块的元数据大小大概在 150byte 左右,存储一个小文件就要占用 150byte 的内存,如果存储大量的小文件很快就将内存耗尽,而整个集群存储的数据量很小,失去了 HDFS 的意义可以将数据合并上传,或者将文件 append 形式追加在 HDFS 文件末尾。
总结来说:就是两点:
无法高效的对大量小文件进行存储。
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
4、为什么HDFS不支持多用户写入及任意修改文件?
答:
不支持多用户写入:HDFS只支持单用户写,因为需要创建副本所以怕冲突,并且若加入多用户写入特性可能会使效率降低;
HDFS 本来就不是适合频繁写入的文件系统,它比较适合一次写入,多次使用。
目前 Hadoop 只支持单用户写,不支持并发多用户写。可以使用 Append 操作在文件的末尾添加数据,但不支持在文件的任意位置进行修改。
5、HDFS如何解决名称节点运行期间EditLog不断变大的问题?
答:
解决方案:利用SecondaryNameNode第二名称节点
第二名称节点是HDFS架构中的一个组成部分,用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。(SecondaryNameNode一般是单独运行在一台机器上)
SecondaryNameNode的工作情况:
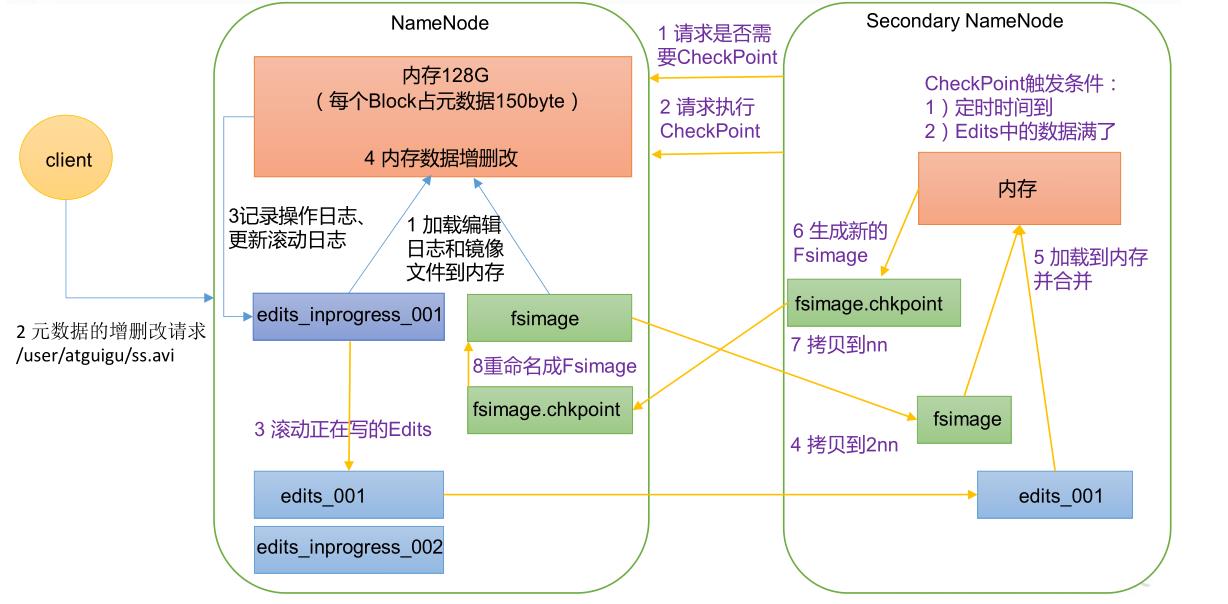
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
(5)NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
6、Map任务为什么要进行分区操作,如何分区?
为什么需要分区操作:
- 假设始终使用一个分区,在处理大型文件时效率极低,因为一台机器必须处理所有输出文件,从而完全丧失了 MapReduce 所提供的并行架构的优势。
- 但是,如果使用一个 partitioner 来描述结果,运行多个 ruduce 任务,运行partition 时,将数据分配到每个 reduce 中,最后合并输出文件,就得到了有意义的最终结果。
- 在将map()函数处理后得到的(key,value)对写入到缓冲区之前,需要先进行分区操作,这样就能把map任务处理的结果发送给指定的reducer去执行,从而达到负载均衡,避免数据倾斜。
如何进行分区操作:
- MapReduce提供默认的分区类(HashPartitioner),我们也可以自定义分区,让其继承Partitioner类,并重写getPartition()方法,让其针对不同情况返回不同数值即可。并在最后通过job设置指定分区类和reducer任务数量即可。
7、MapReduce中多个Reduce任务的结果会做进一步的处理么?为什么?
答:
会,因为reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据,取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)形成大文件。
8、参照“第四章-MapReduce”中的图4-7、4-8和4-9,如果有两个Reduce,重新画出用户没有定义Combiner时的MapReduce过程示意图,并简要说明Shuffle过程。
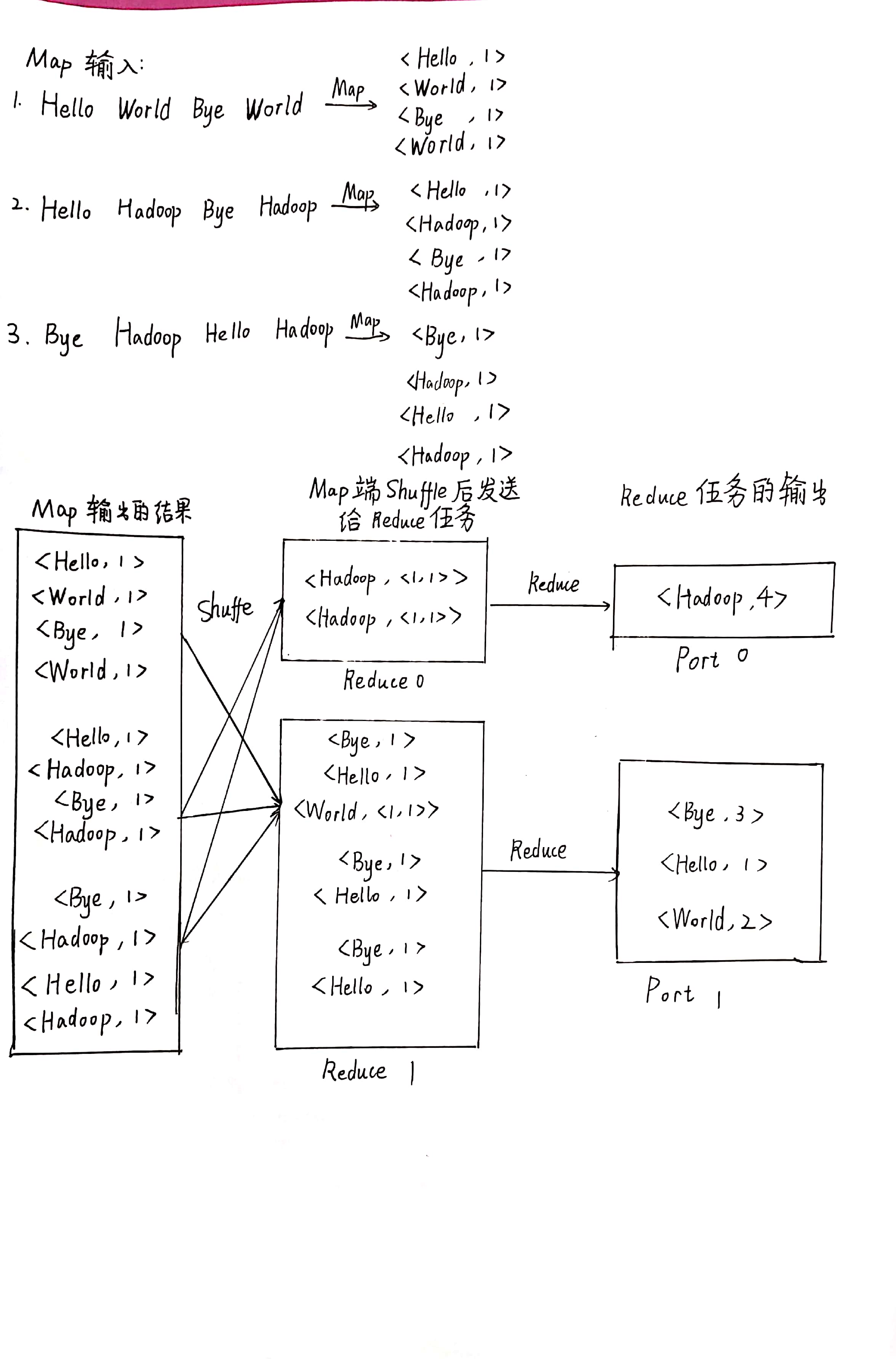
Shuffle 过程:
- 分区
在将 map 函数处理后得到<key, value>对写入到缓冲区之前, 需要先进行分区操作,这样就能把 Map 任务处理的结果发送给指定的Reducer 去执行,从而达到负载均衡,避免数据倾斜。 - 执行溢写
一旦缓冲区内容达到阈值,就会会锁定内存,并在每个分区中对其中的键值对按键进行 sort 排序, 排序完成后创建一个溢出写文件, 然后开启一个后台线程把这部分数据以一个临时文件的方式溢出写到本地磁盘中。 - 归并 merge
如果一个 task 处理的数据很大,以至于超过缓冲区内存时,就会生成多个 spill 文件。此时就需要对同一个 map 任务产生的多个 spill 文件进行归并生成最终的一个已分区且已排序的大文件。 这个过程包括排序和合并,归并得到的文件内键值对可能拥有相同的 key。
以上是关于hadoop hdfs的默认目录问题的主要内容,如果未能解决你的问题,请参考以下文章