PyTorch 在 Tesla 自动驾驶中的应用 —— Andrej Karpathy
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch 在 Tesla 自动驾驶中的应用 —— Andrej Karpathy相关的知识,希望对你有一定的参考价值。
本文翻译自2019年 Andrej Karpathy 在 PyTorch 的演讲,视频链接:PyTorch at Tesla - Andrej Karpathy, Tesla
大家好,我是Andrej,我时特斯拉AI部门的负责人,今天非常激动能够站在这里跟大家分享特斯拉是如何使用 PyTorch 训练自动驾驶的神经网络。

对于还不熟悉自动驾驶的人,我现在简单介绍一下,自动驾驶最基本的功能就是要保证车辆在车道线内,并且要与其它车辆保持安全距离。我们也正在构建更多自动驾驶功能,比如自动驾驶导航,你可以在地图上标记出你的目的地,然后在高速公路上,汽车就会自动完成所有的驾驶任务,保证能够到达目的地。

两周前,我们发布了智能召唤功能,你可以在停车场门口召唤汽车,然后汽车就会自动从停车位出来,开到你面前,这也是一个神奇的功能。

更进一步,我们的团队对于开发具有全自动驾驶能力的汽车也非常感兴趣,这也是我们最近集中精力在做的工作。我们的自动驾驶方法没有使用雷达和高精度地图,所有的自动驾驶功能的构建都是基于机器学习和计算机视觉,通过汽车周围8个摄像头的原始视频流实现的。如下是8个摄像头在某个瞬间拍摄到的图像,我们通过很多卷积神经网络处理大量的这种图像。

特斯拉现在是一家相当垂直整合的公司,在自动驾驶方面也是如此,我们会自己制造汽车,并在车辆周围安装传感器,用于收集自动驾驶所需要的数据,然后将它们放在预置的GPU集群中进行训练,之后通过整个 STACK 在我们自己开发的硬件运行神经网络。

接下来我想稍微深入分享一下我们团队通过 PyTorch 实现的分布式训练。我们的主要工作是分析图像,比如对于这张图像,如果想要让车辆能够自动驾驶,那么它对这个环境就需要有足够的了解,要理解交通信号灯的含义、标记出车道线、检测其它物体等等,有非常多的设定任务。

我们的很多网络都采用了下面这种结构,我们叫它 HydraNets,它有一个共享的主干网络,然后有很多子任务挂在它上面,主干网络通常是 ResNet 50 之类的。之所以采用这种结构,是因为我们不可能为每一个任务都训练一个神经网络,在自动驾驶中几乎有100+个任务,所以必须摊销一些计算。

如下展示了在智能召唤任务中对道路边缘的检测,这是必须从环境中了解的内容,因为要避免车辆碰撞或开上路沿石。

HydraNets直接在图像中进行预测,然后将它们投射出来,并在时间和空间上进行拼接,依次来了解所处的环境。这里有一个例子,展示了道路边缘检测以及它们是如何被投影的,当人们召唤它时,汽车会在这个停车场周围盘旋,试图找到通往目标的道路。

现在我们只讨论了在独立图像上运行的网络,实际上自动驾驶任务必须同时对多个图像进行处理。例如,我们想估计这些图像的深度,那么通过同一场景的其它视图辅以预测每个像素的深度会更加准确。其它还有诸如道路布局预测、方向盘转向预测等,都需要很多来自各个图像经过 HydraNets 提取的特征。
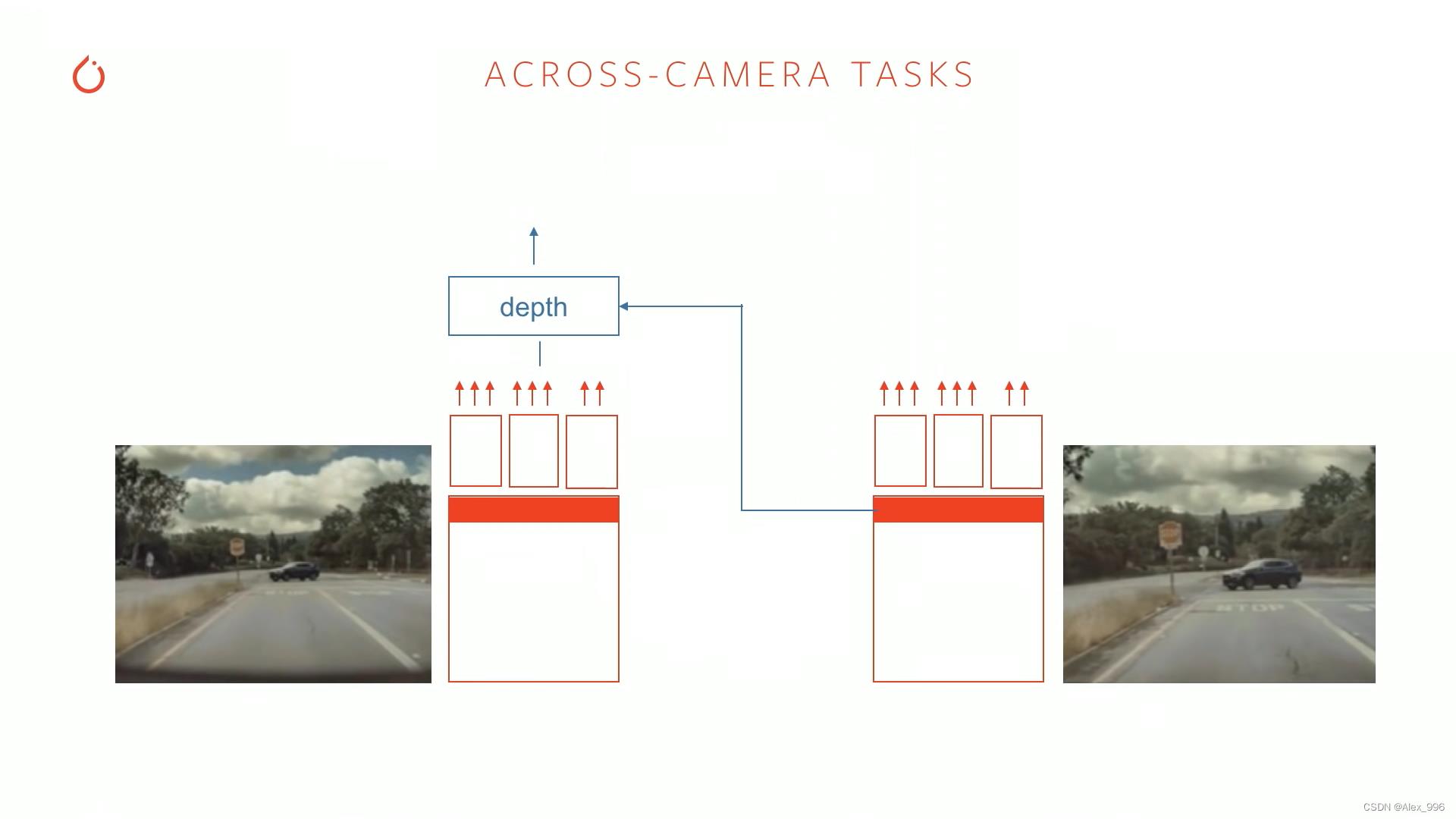
这看起来是我们为不同的相机提供而不同的HydraNets网络,实际上是想从这些网络中提取一些特征,然后进入第二步——可选循环处理,产生类似道路布局预测的东西。现在拼接不会发生,在C++代码库中,跨域时间和空间的拼接发生在循环神经网络内部。
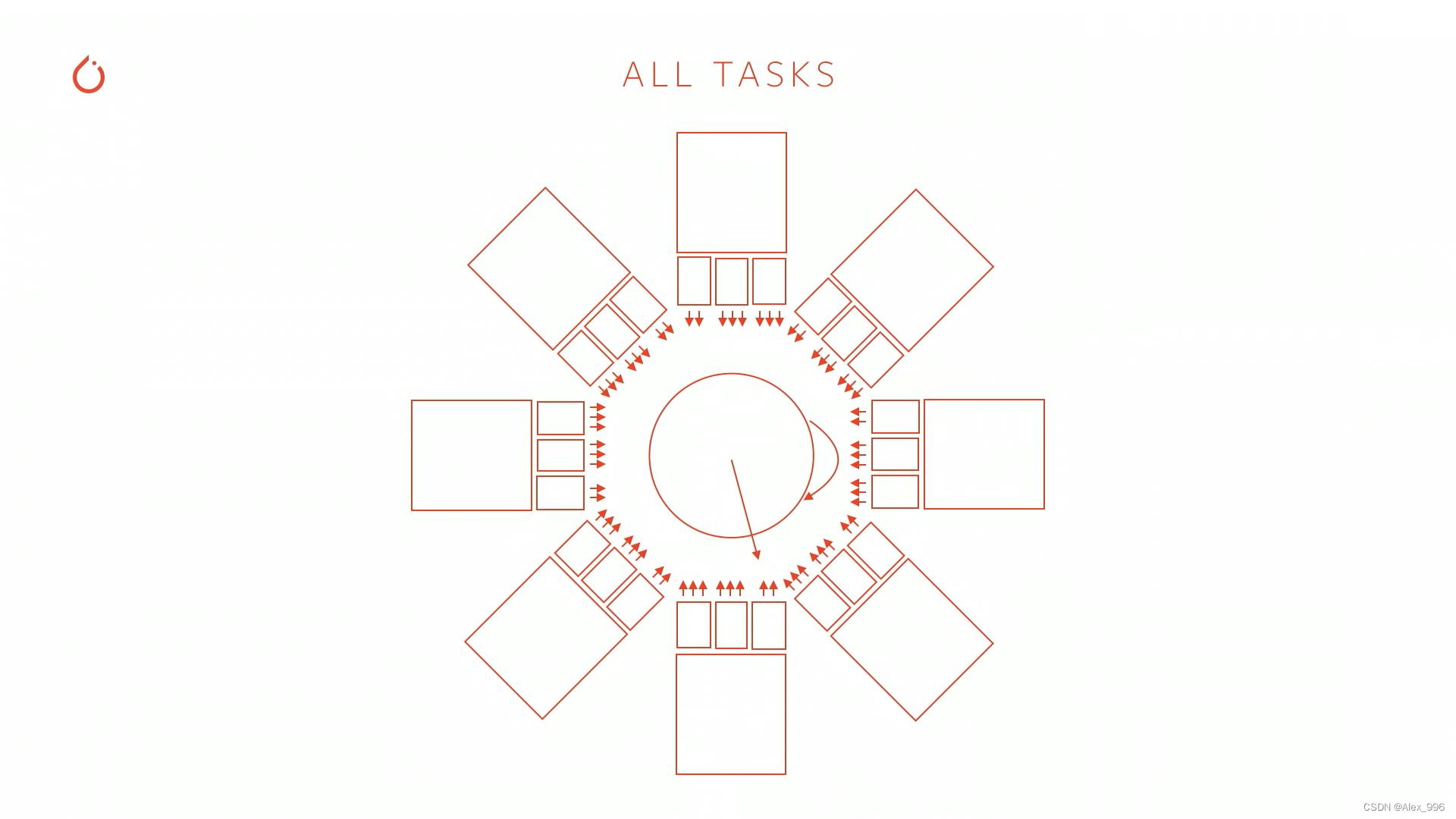
8个摄像头都通过 HydraNets 网络,都产生各种中间预测,但除了这些网络提取的特征之外,还有之前循环处理的特征,特别之处在于,每个子任务都对这个网络的部分进行下采样并传输。例如,可以使用相机在线训练对象检测器,或者可以训练深度网络,或者可以训练道路布局预测网络,所有这些任务对图形进行二次采样,并只训练那部分。
网络的真正训练并没有那么容易,8个摄像头,16个时间步,32个batch size,那么将在内存中保存4096个图像,并且它们所有的激活都在一个前向传播中,单个GPU甚至单个节点进行训练时,典型的分布式数据并行将中断,因为内存会爆掉。因此我们的很多训练必须结合一些数据结构,将真实数据并行分布,结合数据并行和模型并行。

除此之外,训练神经网络还有一个比较棘手的问题,典型的最简单的情况可能是所有的GPU对不同任务的循环训练,但是当有100+个任务的时候,只把任务1训练好可能会导致任务2、3失控。一个可能的解决方案是定义一个GPU训练池,有的训练目标检测,有的训练道路布局预测,有的训练深度预测,这些都是非常异构的工作流程,同时训练网络的不同部分,然后就可以同步/异步的安排它们。
总而言之,训练一个自动驾驶的神经网络是一个非常昂贵的任务,特别是今天将训练48个不同的神经网络,做出1000个不同的预测,如果计算输出张量的数量,需要70000个GPU小时来训练编译自动驾驶神经网络。所以如果你有一个带有8个GPU的单个节点,那么将训练1年,并且不是训练1次就完成的,还需要在这个基础上进行迭代。
我们的团队正在自动化许多工作流程,不仅仅是神经网络训练本身,还有周围许多相关任务,以及验证和评估,特别是我们必须校准所有不同的阈值。自动化的工作流程从数据集开始,然后训练神经网络,之后可以做校准和评估,可以看到一个持续的集成。

我还想再谈谈推理这方面,因为我们谈到了很多关于训练的内容。我们有专门的硬件团队开发后端,我们称之为FSD计算机,与我们在推出此芯片之前使用GPU相比,它提供了大约144个int8 TOPS运算,大约是一个数量级的提升,并且成本更低,所以我们现在所有生产线出来的最新汽车中都使用了它。
除了GPU集群之外,我们的硬件团队还在做一个我们称之为Dojo集群的项目,这是一个神经网络训练计算机/芯片,我们希望可以在训练中做与推理完全相同的事情。
总而言之,今天谈到了为自动驾驶开发这些神经网络的整个生命周期,这些网络相当复杂和庞大,如果我们真的想训练这头“野兽”,需要处理很多的问题,但它同样也给了我们一些非常有趣的结果,而且这样做的好处不仅是我们开始训练非常棒的大型网络,同样我们也将它进行了落地应用。
目前特斯拉的自动驾驶已经累积了10亿英里(1.60934 * 10^9 km)的数据,确认记录了200000次变道,遍布全球50+个国家和地区。

最后,我要感谢PyTorch团队的反应迅速和乐于助人,让我们能够开发所有这些网络并真正大规模地训练它们,然后再现实世界中玩真的很有趣的应用。
以上是关于PyTorch 在 Tesla 自动驾驶中的应用 —— Andrej Karpathy的主要内容,如果未能解决你的问题,请参考以下文章