国内重要的 Go 语言项目:TiDB 3.0 GA,稳定性和性能大幅提升
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了国内重要的 Go 语言项目:TiDB 3.0 GA,稳定性和性能大幅提升相关的知识,希望对你有一定的参考价值。
参考技术A
TiDB 是 PingCAP 自主研发的开源分布式关系型数据库,具备商业级数据库的数据可靠性,可用性,安全性等特性,支持在线弹性水平扩展,兼容 mysql 协议及生态,创新性实现 OLTP 及 OLAP 融合。
TiDB 3.0 版本显著提升了大规模集群的稳定性,集群支持 150+ 存储节点,300+TB 存储容量长期稳定运行。易用性方面引入大量降低用户运维成本的优化,包括引入 Information_Schema 中的多个实用系统视图、EXPLAIN ANALYZE、SQL Trace 等。在性能方面,特别是 OLTP 性能方面,3.0 比 2.1 也有大幅提升,其中 TPC-C 性能提升约 4.5 倍,Sysbench 性能提升约 1.5 倍,OLAP 方面,TPC-H 50G Q15 因实现 View 可以执行,至此 TPC-H 22 个 Query 均可正常运行。新功能方面增加了窗口函数、视图(实验特性)、分区表、插件系统、悲观锁(实验特性)。
截止本文发稿时 TiDB 已在 500+ 用户的生产环境中长期稳定运行,涵盖金融、保险、制造,互联网, 游戏 等领域,涉及交易、数据中台、 历史 库等多个业务场景。不同业务场景对关系型数据库的诉求可用 “百花齐放”来形容,但对关系数据库最根本的诉求未发生任何变化,如数据可靠性,系统稳定性,可扩展性,安全性,易用性等。请跟随我们的脚步梳理 TiDB 3.0 有什么样的惊喜。
3.0 与 2.1 版本相比,显著提升了大规模集群的稳定性,支持单集群 150+ 存储节点,300+TB 存储容量长期稳定运行,主要的优化点如下:
1. 优化 Raft 副本之间的心跳机制,按照 Region 的活跃程度调整心跳频率,减小冷数据对集群的负担。
2. 热点调度策略支持更多参数配置,采用更高优先级,并提升热点调度的准确性。
3. 优化 PD 调度流程,提供调度限流机制,提升系统稳定性。
4. 新增分布式 GC 功能,提升 GC 的性能,降低大集群 GC 时间,提升系统稳定性。
众所周知,数据库查询计划的稳定性对业务至关重要,TiDB 3.0 版本采用多种优化手段提升查询计划的稳定性,如下:
1. 新增 Fast Analyze 功能,提升收集统计信息的速度,降低集群资源的消耗及对业务的影响。
2. 新增 Incremental Analyze 功能,提升收集单调递增的索引统计信息的速度,降低集群资源的消耗及对业务的影响。
3. 在 CM-Sketch 中新增 TopN 的统计信息,缓解 CM-Sketch 哈希冲突导致估算偏大,提升代价估算的准确性,提升查询计划的稳定性。
4. 引入 Skyline Pruning 框架,利用规则防止查询计划过度依赖统计信息,缓解因统计信息滞后导致选择的查询计划不是最优的情况,提升查询计划的稳定性。
5. 新增 SQL Plan Management 功能,支持在查询计划不准确时手动绑定查询计划,提升查询计划的稳定性。
1. OLTP
3.0 与 2.1 版本相比 Sysbench 的 Point Select,Update Index,Update Non-Index 均提升约 1.5 倍,TPC-C 性能提升约 4.5 倍。主要的优化点如下:
1. TiDB 持续优化 SQL 执行器,包括:优化 NOT EXISTS 子查询转化为 Anti Semi Join,优化多表 Join 时 Join 顺序选择等。
2. 优化 Index Join 逻辑,扩大 Index Join 算子的适用场景并提升代价估算的准确性。
3. TiKV 批量接收和发送消息功能,提升写入密集的场景的 TPS 约 7%,读密集的场景提升约 30%。
4. TiKV 优化内存管理,减少 Iterator Key Bound Option 的内存分配和拷贝,多个 Column Families 共享 block cache 提升 cache 命中率等手段大幅提升性能。
5. 引入 Titan 存储引擎插件,提升 Value 值超过 1KB 时性能,缓解 RocksDB 写放大问题,减少磁盘 IO 的占用。
6. TiKV 新增多线程 Raftstore 和 Apply 功能,提升单节点内可扩展性,进而提升单节点内并发处理能力和资源利用率,降低延时,大幅提升集群写入能力。
TiDB Lightning 性能与 2019 年年初相比提升 3 倍,从 100GB/h 提升到 300GB/h,即 28MB/s 提升到 85MB/s,优化点,如下:
1. 提升 SQL 转化成 KV Pairs 的性能,减少不必要的开销。
2. 提升单表导入性能,单表支持批量导入。
3. 提升 TiKV-Importer 导入数据性能,支持将数据和索引分别导入。
4. TiKV-Importer 支持上传 SST 文件限速功能。
RBAC(Role-Based Access Control,基于角色的权限访问控制) 是商业系统中最常见的权限管理技术之一,通过 RBAC 思想可以构建最简单“用户-角色-权限”的访问权限控制模型。RBAC 中用户与角色关联,权限与角色关联,角色与权限之间一般是多对多的关系,用户通过成为什么样的角色获取该角色所拥有的权限,达到简化权限管理的目的,通过此版本的迭代 RBAC 功能开发完成。
IP 白名单功能(企业版特性) :TiDB 提供基于 IP 白名单实现网络安全访问控制,用户可根据实际情况配置相关的访问策略。
Audit log 功能(企业版特性) :Audit log 记录用户对数据库所执行的操作,通过记录 Audit log 用户可以对数据库进行故障分析,行为分析,安全审计等,帮助用户获取数据执行情况。
加密存储(企业版特性) :TiDB 利用 RocksDB 自身加密功能,实现加密存储的功能,保证所有写入到磁盘的数据都经过加密,降低数据泄露的风险。
完善权限语句的权限检查 ,新增 ANALYZE,USE,SET GLOBAL,SHOW PROCESSLIST 语句权限检查。
1. 新增 SQL 方式查询慢查询,丰富 TiDB 慢查询日志内容,如:Coprocessor 任务数,平均/最长/90% 执行/等待时间,执行/等待时间最长的 TiKV 地址,简化慢查询定位工作,提高排查慢查询问题效率,提升产品易用性。
2. 新增系统配置项合法性检查,优化系统监控项等,提升产品易用性。
3. 新增对 TableReader、IndexReader 和 IndexLookupReader 算子内存使用情况统计信息,提高 Query 内存使用统计的准确性,提升处理内存消耗较大语句的效率。
4. 制定日志规范,重构日志系统,统一日志格式,方便用户理解日志内容,有助于通过工具对日志进行定量分析。
5. 新增 EXPLAIN ANALYZE 功能,提升SQL 调优的易用性。
6. 新增 SQL 语句 Trace 功能,方便排查问题。
7. 新增通过 unix_socket 方式连接数据库。
8. 新增快速恢复被删除表功能,当误删除数据时可通过此功能快速恢复数据。
TiDB 3.0 新增 TiFlash 组件,解决复杂分析及 HTAP 场景。TiFlash 是列式存储系统,与行存储系统实时同步,具备低延时,高性能,事务一致性读等特性。 通过 Raft 协议从 TiKV 中实时同步行存数据并转化成列存储格式持久化到一组独立的节点,解决行列混合存储以及资源隔离性问题。TiFlash 可用作行存储系统(TiKV)实时镜像,实时镜像可独立于行存储系统,将行存储及列存储从物理隔离开,提供完善的资源隔离方案,HTAP 场景最优推荐方案;亦可用作行存储表的索引,配合行存储对外提供智能的 OLAP 服务,提升约 10 倍复杂的混合查询的性能。
TiFlash 目前处于 Beta 阶段,计划 2019 年 12 月 31 日之前 GA,欢迎大家申请试用。
未来我们会继续投入到系统稳定性,易用性,性能,弹性扩展方面,向用户提供极致的弹性伸缩能力,极致的性能体验,极致的用户体验。
稳定性方面 V4.0 版本将继续完善 V3.0 未 GA 的重大特性,例如:悲观事务模型,View,Table Partition,Titan 行存储引擎,TiFlash 列存储引擎;引入近似物理备份恢复解决分布数据库备份恢复难题;优化 PD 调度功能等。
性能方面 V4.0 版本将继续优化事务处理流程,减少事务资源消耗,提升性能,例如:1PC,省去获取 commit ts 操作等。
弹性扩展方面,PD 将提供弹性扩展所需的元信息供外部系统调用,外部系统可根据元信息及负载情况动态伸缩集群规模,达成节省成本的目标。
我们相信战胜“未知”最好的武器就是社区的力量,基础软件需要坚定地走开源路线。截止发稿我们已经完成 41 篇源码阅读文章。TiDB 开源社区总计 265 位 Contributor,6 位 Committer,在这里我们对社区贡献者表示由衷的感谢,希望更多志同道合的人能加入进来,也希望大家在 TiDB 这个开源社区能够有所收获。
TiDB 3.0 GA Release Notes: https://pingcap.com/docs-cn/v3.0/releases/3.0-ga/
申砾:Go in TiDB
在 4 月 15 日的 GopherChina 2017 上,PingCAP Engineering VP 申砾发表了《Go in TiDB》的主题演讲。现奉上演讲实录,enjoy~
各位好,我叫申砾,来自 PingCAP。之前在网易有道和 360 搜索做过各种垂直搜索主要设计信息检索、数据挖掘、分布式计算。目前在 PingCAP 负责 TiDB 的技术,主要做分布式存储/计算。
今天和大家分享一下 Go 语言在分布式数据库 TiDB 开发中的一些使用经验。我先会介绍一下 TiDB 是什么,有什么样的特点。然后介绍 TiDB 的整体架构特别是 SQL 层的一些东西,最后会介绍一些我们开发过程中使用 Golang 的一些实践经验。
TiDB 是什么

简单来讲,TiDB 是一个分布式数据库。数据库有很多种,各有各的特点,解决各自的应用场景,那么为什么我们要开发一个新的数据库,这个数据库有什么特点?一些场景下,数据库问题已经被很好的解决,比如小数据量,以及中小规模的查询量,单机数据库已经很好的解决了问题。但是在一些场景下,问题还远没有解决,而且这些场景出现的越来越多。我们认为下一代分布式数据库应该有这样一些特点:
首先必须是可以水平扩展的。大家应用场景中数据越来越多,能把数据顺利的保存下来是基本的要求。所以才有了各种分库分表、中间件、NoSQL 数据库,或者是各种通过共享存储解决容量问题分方案。一句话讲,数据存不下来,其他的一切都是无用功。我们希望有一种方式能通过简单的增加节点就能实现水平扩展的方案。
第二是高可用以及 Auto-Failover。当你的数据库能水平扩展,业务蒸蒸日上,用户越来越多,集群规模越来越大时,那么恭喜你已经走上人生巅峰。但是,机器是会出现故障的,硬盘、网卡、电源、光纤被挖断,总有一款适合你。集群规模大了之后,故障就会变得常见。那么我们就需要应对这种情况。靠人肉运维是不可能的,我们需要集群能够在出现少量节点故障的情况下依旧能服务,并且能自动恢复。
第三是 ACID,也就是事务。很多数据库方案为了实现之前的两点,放弃了事务,这样开发数据库的难度一下子就下来了不少,如果业务用不到事务还好,一但需要,就很痛苦,需要自己去写各种逻辑,包括正常情况的处理、冲突情况的处理以及各种异常情况的处理。Jeff Dean 说过,他很后悔没给 BigTable 加上事务,导致了内部团队各种造轮子。不但造成重复劳动,而且大家造的也不一定是对的。
最后是 SQL。提供 KV 接口已经能解决不少问题,并且只提供简单的 KV 接口能够简化存储模型。但是 SQL 这门古老而强大的语言在数据库中被广泛使用,在现在以及可见的将来都有很强的生命力。支持 SQL 对业务端能提供非常好的支持。所以我们做了一个新的数据库,具备上述四个特点,这就是 TiDB。
接下来我会逐步介绍一些 TiDB 内部的东西,包括整体架构核实现细节。

接下来我会逐步介绍一些 TiDB 内部的东西,包括整体架构核实现细节。
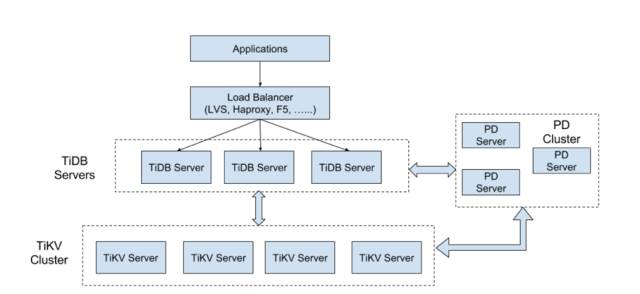
上图是 TiDB 的整体架构,我们可以看到最下面是 TiKV 集群,也就是整个 TiDB 的存储引擎层,这里是一个带事务的分布式KV,且内置一个和 TiDB SQL 层一起使用的分布式计算框架。我们会把一些计算逻辑发送到 TiKV 处理。右边是 PD 集群,主要负责三件事情:
1. 管理 TiKV 集群的元信息,主要是有哪些实例、哪些 region、每个 region 的 startkey 和 endkey 是什么。
2. 对 TiKV 集群做调度,包括新增结点后,能够以 region 为单位做调度,结点 down 机后,能够将上面的数据调度走,还有就是根据容灾策略、机器负载做调度。
3. 生成时间戳,用于事务。
中间这层是 SQL 层,提供对业务的接口,负责处理 protocol、SQL 解析、查询计划生成、整个执行器的控制和调度。
在这层之上,可以添加 proxy,用来负载均衡。这个已经有很多优秀的方案,直接拿来用就好。我们对外暴露的就是 MySQL 协议,业务端不需要感知下面是 TiDB 还是 MySQL。
大部分人都用过数据库,但是真正自己开发过数据库或者是看过一些数据库实现的人可能不多。我从 SQL 的角度简单介绍一下 TiDB 的核心流程。
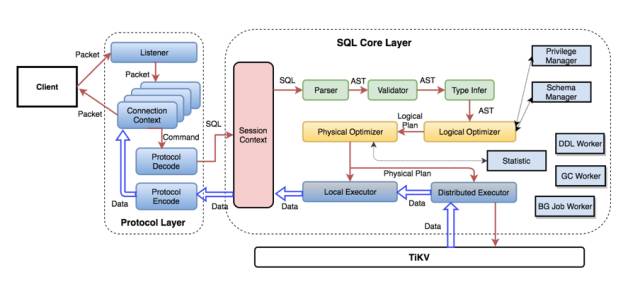
这张图是 SQL 层的架构。首先前端要在某个端口上监听 client 请求,在一个 connection 的生命周期内,我们需要维护他的一些信息,还要做编解码转换,得到结构化的请求。这个请求就会丢进 core layer 开始处理。我们还会维护一个 session conext,包括这个 session 的各种信息,比如 session scope 的 variable 值。这个 context 也是整个 SQL 层的入口。SQL 进来之后先交给 parser 从文本处理成结构化的数据,也就是 ast,也就是从 string 转换成为一个易于处理的内部树形结构。接下来对这个结构进行各种处理,包括做合法性验证、名字解析、类型推导、权限检查等等,为之后的查询计划制定做各种准备。
下面进去了核心组件:optimizer。首先是进行逻辑优化,将每个 ast 的 node 转化成逻辑上的 plan,并且从数学角度做等价变化,简化 SQL 的逻辑,比如做常量折叠,select * from t where 1=1; 被转换为 select * from t;,还有常量传播:select * from t where c1=1 and c2 = c1; 被转换为 select * from t c1=1 and c2=1;。
接下来根据逻辑计划制定物理计划,这两个有什么区别呢?简单来讲,逻辑计划是不关系细节,只关心 SQL 的逻辑,比如 select * from t where c > 10; 不管这个表是否有索引,是本地内存表还是远程的存储引擎中的表,都认为 from t 是一个 datasource。但是物理优化需要考虑各种现实问题,比如去哪里读数据、怎么去读数据会比较快。再举个通俗点的例子,老婆说我要吃好吃的,那么这个就是一个逻辑计划,没有任何现实考虑。老公就要制定物理计划,比如在家里吃还是外面买吃,要吃什么口味的,花多少钱比较合适,有没有团购可用、几点出发、做什么车去、会不会堵车排队、吃完这顿还有没有钱吃下顿,怎么才能让这顿饭吃的多快好省。
下面这一层是执行器,就是能按照物理计划老老实实的做各种操作,优化器就是老板,负责制定计划,执行器就是员工,来做执行。执行的时候,少不了要和存储交互,取数据、做运算。
整个 SQL 层除了这些之外,还包括很多重要组件,比如权限管理、schema 管理、DDL worker、统计信息管理等。
上面讲了流程,这里以一个 SQL 为例进行说明。

假设我们有这样一个 schema,两个字段,一个索引。现在要处理这样一条 SQL,有查询条件以及一个 count 操作,很简单的一条 SQL。
我们拿到这个 AST 之后,先不考虑那么多,制定出逻辑的计划。这条 SQL 比较简单,首先是从一个数据源拿数据,然后看看每行数据是否满足要求,满足这个 where 条件的,就增加计数器。
接下来就要开始考虑现实的问题,表结构是什么样的,数据从哪里来、到哪里去、如何处理。比如这里可以选择通过 index1 来过滤数据,再检查 c2 上面的条件是否满足,最后计算 count。当然这里还会取决于数据的分布,假设所有的数据中 c1 都是大于 10 的,那么索引就没起作用,还不去直接去读取数据来的快。这里就需要计算 plan 的 cost,也就是大家常说的 cost-based optimize。
在单机情况下,刚才的 plan 已经不错了,但是我们做的是一个分布式数据库,大部分情况都要处理分布式的计算。刚才的那个 SQL 丢给 TiDB 最终会制定出这样一个 plan,SQL 层和 TiKV 层会一起协作,一部分数据交给 TiKV 层做计算,最终结果汇总到 SQL 层,做 final aggregate。这样有很多好处,首先参与计算的节点变多,计算速度加快,第二计算靠近储存,能够很快的读取数据出来,并且做了过滤以及聚合,减少了大量的网络传输。
大家从上面可以看到,整个逻辑是非常复杂的。我们构建这个分布式数据库面临了很多挑战。
首先,我们构建的是一个大规模的分布式系统,而且是一个很复杂的系统,各种分布式系统中的问题我们都会遇到,比如一致性问题。
第二,分布式数据库和单机数据库一个很大的区别是,需要大量的网络操作,无论是维护集群状态,还是处理 SQL 语句,都需要大量的网络操作系统,我们需要简单方便的网络操作。
第三,数据库作为业务的核心,其性能至关重要,对于 OLTP 业务,一般来说对用户的响应时间低于 200ms,用户就感受不到延迟,这 200ms 在网络上就要消耗不少,再加上业务代码的处理,真正留给数据库的时间并不多。
第四,数据库往往要处理海量的数据,那么请求处理过程中,这些数据需要申请内存,用完之后还要销毁内存。有 GC 会帮助很大。
第五,数据库需要抗并发能力强,OLTP 业务往往需要很高的吞吐,到几十万甚至上百万。
第六,作为一个存储了海量数据的数据库,不提供 OLAP 能力是很不方便的,否则用户还需要用 ETL 工具将数据倒出去,浪费资源并且费时费力、无法获取实时数据。OLAP 是一个大坑,各种复杂的查询处理起来还是很难的。
还好,面对这么多挑战,有 Go 语言这个好帮手。
我们为什么选择了 Go 语言?它有哪些地方吸引我们,帮我们解决问题?
首先是开发效率,构建一个如此大规模的系统,并且支持 SQL 这么复杂的东西,再加上我们支持了 MySQL 的协议和行为。支持协议简单,支持行为很难,特别是我们还需要支持 MySQL 的 bug(因为有些用户已经把 bug 当做 feature 用了)。我们需要一门开发效率高、工程上优秀的语言。
Go 语言最大的特点就是并发写起来很舒服方便、这正适合一个需要抗高并发、需要做并行计算提速的数据库。
Go 的网络编程很简单,我们很容易写出高质量的网络程序。
GC,有了 GC 降低了很多心智负担,也降低了代码中出问题的概率。当然 GC 也会带来延迟和抖动、我们也需要很好的去和 GC 相处。
Go 有强大的标准库和丰富的第三方库,import 机制也很好用。很少出现缺失库的问题。
Go 官方还提供很多好用的工具,比如 pprof,trace 等,多次帮助我们定位了问题。
性能对数据库至关重要,Go 语言运行速度非常不错,虽然还是赶不上 C/C++,但是已经让我们很满意。
另外还有一点,Go 的开发还是很活跃,半年一个版本,每次都有令人兴奋的特性。这也给我们很好的支持。
Go 语言在 PingCAP 有大量的应用,除了 TiKV 和一些自动化部署工具之外,所有的组件都是 Go 来开发的。我统计了一下 SQL 层的代码,目前已经超过 11w 行 Go 代码,并且有 100 多个 contributor 贡献过代码。我们在实践中积累了一些实践经验,和大家分享一下。
首先看 Goroutine。Goroutine 是 Go 最大的特点,语言名字就是 Go 这个关键词。在代码中,我们可以很简单方便的启动一个新的 Goroutine,并且 Goroutine 之间有原生的通讯机制(channel),这样我们就很容易写成并发程序,充分利用现代的多核计算资源。接下来介绍两个例子,我们是如何通过并行计算提高计算效率。
先看一个并行读取数据的例子。
通过索引读取数据是一个普遍的需求,TiDB 支持 Global Index,索引数据和表中的数据并不一定在一台机器上,那么我们就需要先去一些机器上读取索引,再根据这些索引信息读取真实的数据。由于索引分散在很多 TiKV 上面,需要向这些节点发消息,等待返回结果。这个时候我们是并行发送请求,并且拿到第一个索引结果后,就可以开始查询 Table 中的数据,同样查询 Table 中的数据请求也是并行发送。这样我们通过并行+流水线的方式,将整个过程尽可能并行,尽可能快的进行,减小启动时间以及整体执行时间。
下面是一个并行 HashJoin 的例子。
HashJoin 在中小规模数据量上总是表现的不错,我们也实现这个算子,同时我们做了一些优化,尽可能的并行处理数据。首先参与 Join 的表是并行读取,读取小表时,会建立 Hash 表,读取大表数据后,会交给多个 Worker。当 Hash 表建完后,会通知所有的 Worker,就可以开始进行 Join 操作,输出结果。
我们项目中还有很多并行的例子,我们也在不断将各种算子并行化。
Goroutine 虽然好,但是用不好就会有内存泄露的问题。一般情况下泄露会出现在读取一个没人写入的 Channel,或者是向一个没人读取的 Channel 写入数据。Goroutine 泄露后,除了对 Go runtime 的调度造成压力之外,更重要的是会将这些 Goroutine 持有的资源泄露,包括内存、fd 等等。当出现泄露的时候,我们可以用 Go 的 block profile 工具查看当前阻塞的 Goroutine,定位泄露位置。当然这是亡羊补牢的方法。我们还是尽可能的减少泄露的出现,一般来说可以在代码中加入等待超时,或者是通过 context 的 cancel 机制保证来清理资源。
接下来聊一下内存和 GC。TiDB 面临 OLTP/OLAP 混合业务,在 OLAP 业务中,往往需要处理海量的数据,处理几千万甚至上亿行数据,在一些较为复杂的 SQL 运行过程中,我们通过 profile 工具往往发现内存分配和 GC 的时间可以占到总时间的一半。
大量的内存开销一方面拖慢了运行速度,第二程序会面临 OOM 的风险。所以内存使用是一个需要特别重视的问题。我们花费了大量的精力来优化内存使用,有几点经验和大家分享。
首先是想办法降低内存分配的次数。相比分配的大小,分配次数是更关键的指标,我们需要尽可能将分配次数减小,比如一次分配足够的 Slice,或者是将多个结构组合在一起,一次分配。
第二点是尽可能重用对象。举一个实际的例子,我们在 TiDB 的 parser 中引入了一个对象 cache,一个 Session 的多个 Query 在进行 parse 的时候会使用一个对象 stack,经过测试我们发现对内存使用优化效果明显。
第三点是尽量使用 sync.Pool。这是标准库中提供的重用对象的工具,在 TiDB 广泛应用。并发安全,使用简单。我们用 sync.Pool 实现了一个 bytespool,在大查询下显著的提升了性能。
Protobuf 是比较标准的 rpc 序列化工具,被广泛的应用,TiDB 也用 protobuf 作为序列化工具。当涉及到大数据量传输以及大量的请求时,rpc 的效率至关重要。我们开始的时候用的 golang/protobuf,但是在 profile 的时候发现速度并不理想,并且会申请很多内存,后来看到了 gogo/protobuf 这个项目,提供更快的编解码速度,并且对于原始类型,可以设置 nullable=fasle 标签,一方面减少指针的数量,减少内存分配次数,另一方面代码写起来也方便些。
处理优化内存使用之外。我们还尝试对内存进行监控,包括对整个进程的内存使用以及每个 Session 的内存使用。对于单个 Session 而言,我们会对大块分配的内存以及比较消耗内存的算子进行监控,比如 HashJoin,这样对内存使用做一个粗略的统计。
Go1.8 发布后带来一些新特性,其中有两个特性对我们比较有用。第一是 GC 进一步优化,很多时候 GC 能够在 10 μs 内完成,这点对提高 TiDB 稳定性很有用。第二点是增加了 sort.Slice 方法,TiDB 中有大量的排序需求,我们经过 benchmark 发现这个方法比以前的 sort.Sort 有不小的优势。
讲完了我们的使用经验之后,和大家分享一下我们接下来的一些计划。首先是马上会将通讯框架换成 gRPC,之前没用 gRPC 是因为 Rust 缺少对应的库,切换到 gRPC 之后就可以通过 streaming 的方式获取数据,提高计算效率。第二,我们计划支持文档操作,具体的形式是仿照 MySQL 的 document store,这个会在近期启动。第三是会持续优化统计信息以及基于代价的查询优化,这个非常有技术难度,我们已经取得了不错的成果,在 GA 版本中大家会看到更多的成果。第四,我们会开发一个更快更通用的分布式计算引擎,用来处理 OLAP 需求。最后,我们正在将 Spark 接到 TiKV 上,这样可以直接读取数据进行分析,很多数据挖掘、机器学习的工作也可以通过 Spark + TiDB 的方式解决。
最后给大家分享一首小诗
May all the data find their ownplace,
May all the SQL queries speed up!
Come, and join us,
To make the best NewSQL database!
以上是关于国内重要的 Go 语言项目:TiDB 3.0 GA,稳定性和性能大幅提升的主要内容,如果未能解决你的问题,请参考以下文章