Flink部署与实战
Posted 尋覔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink部署与实战相关的知识,希望对你有一定的参考价值。
默认Hadoop,zookeeper等已完全配置好
遗留问题:Hadoop没有secondarynamenode结点
sbin/hadoop-daemon.sh start secondarynamenode
简单配置一下三台Hadoop
修改主机名字,添加主机名字
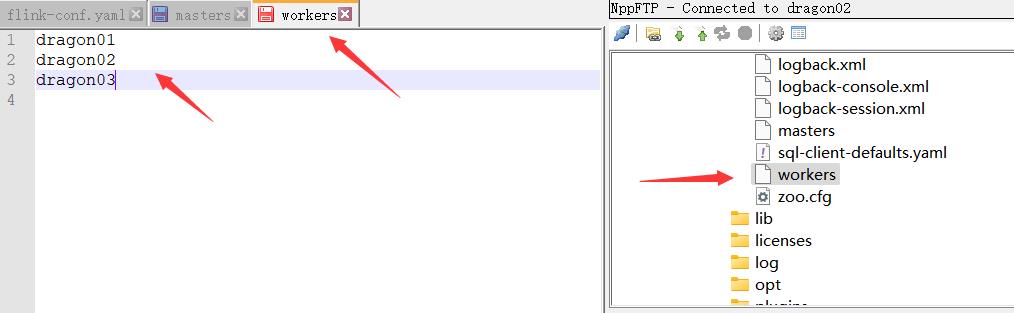
vi /etc/hosts,Hadoop/etc/hadoop/workers
添加名字
上传解压重命名,删除无效文件
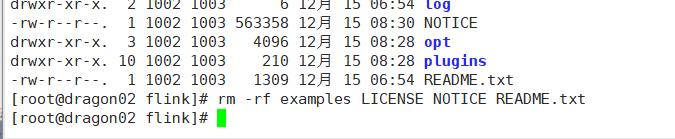
flink standalone单机模式
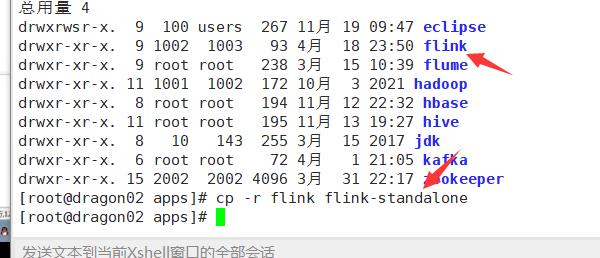
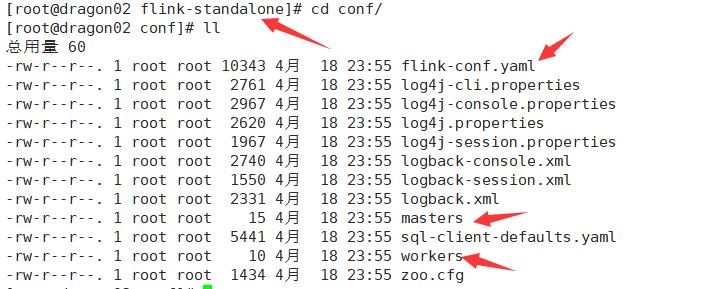
配置三个文件
这里使用note++配置
安装插件
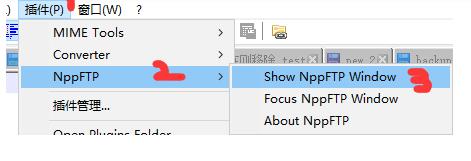
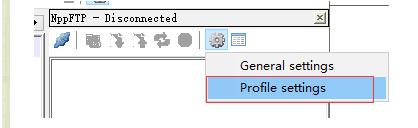
修改参数
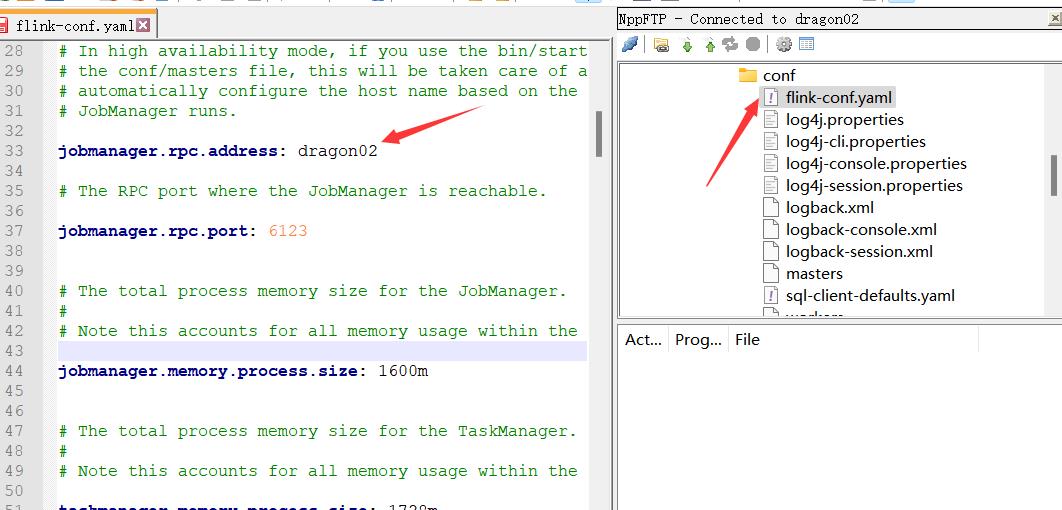

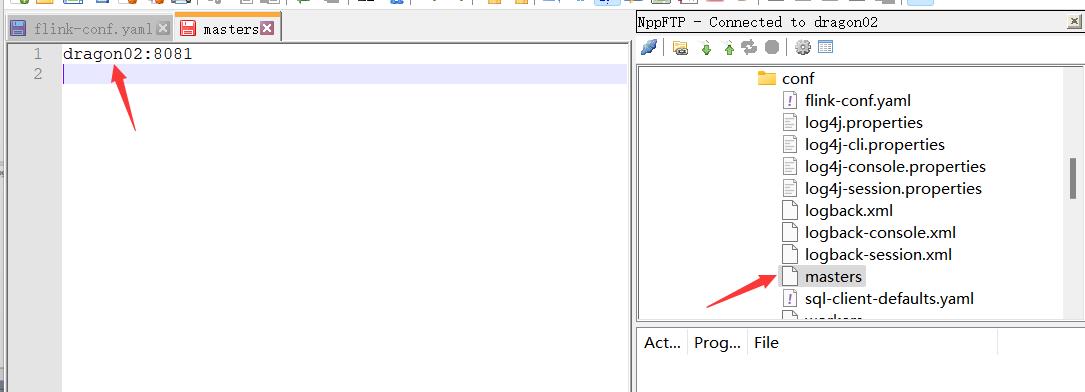
传输两台电脑
[root@dragon02 apps]# scp -r flink-standalone/ dragon03:/opt/apps/启动集群
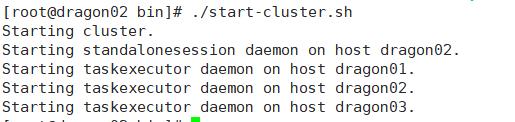
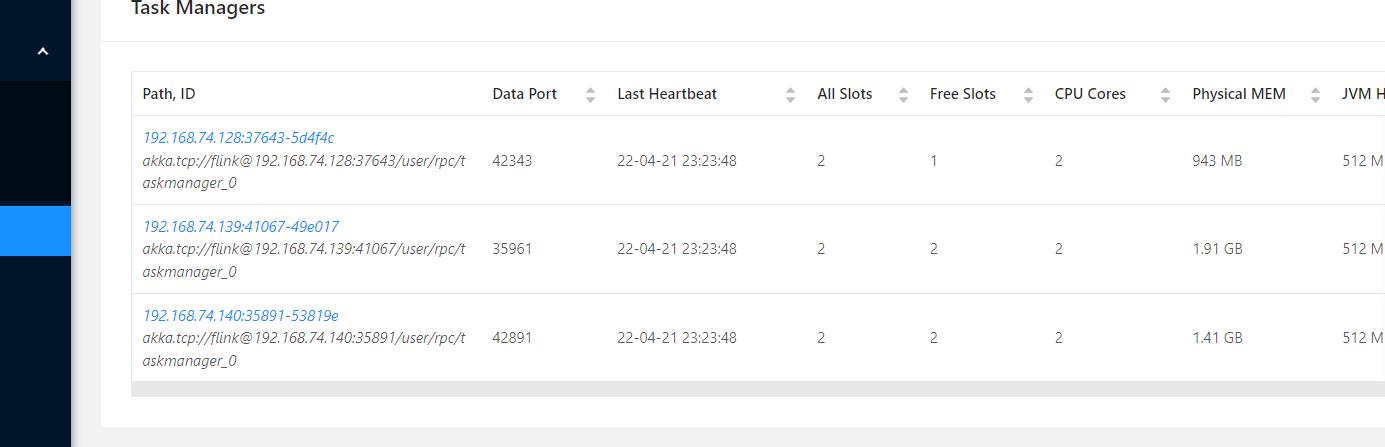
TaskManagerRunner任务管理器
访问后台
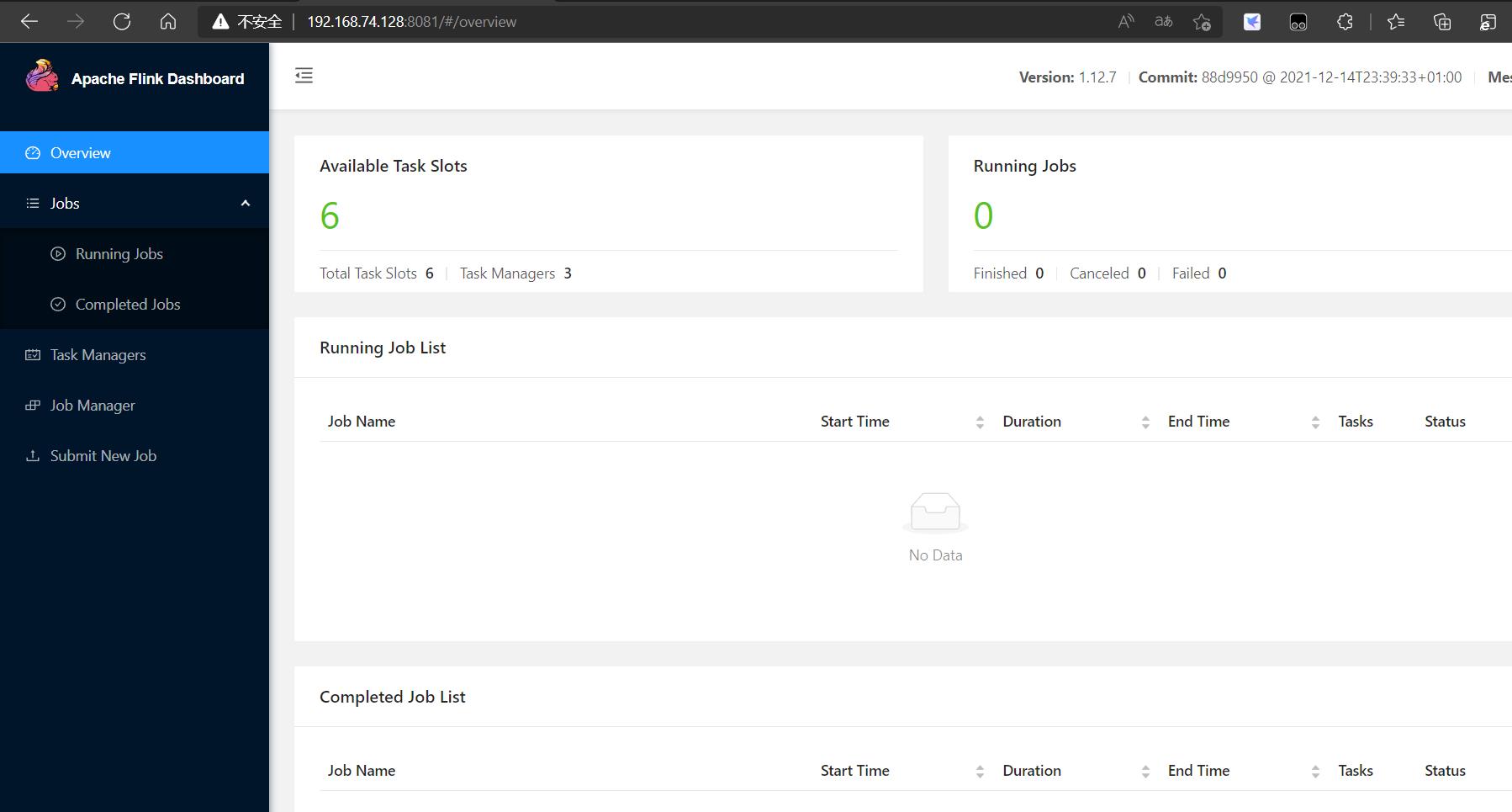
上传任务
先进行打包
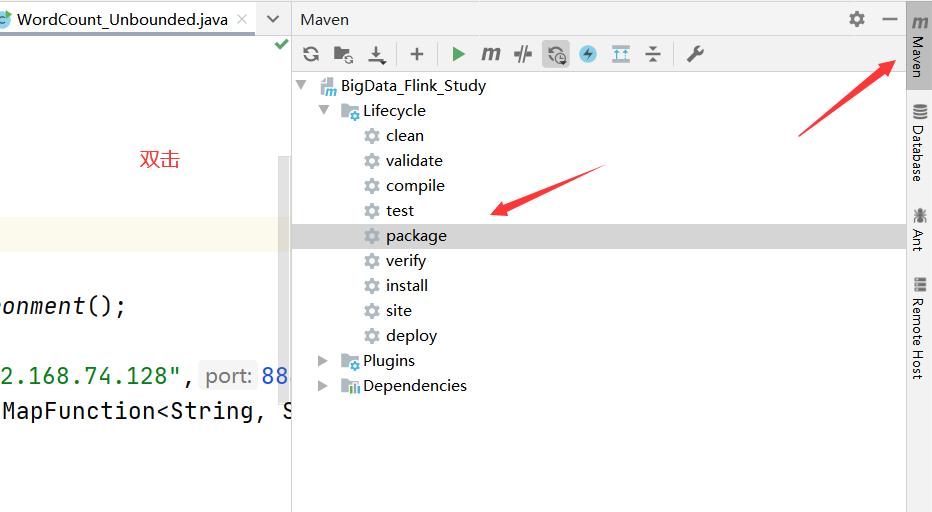 拷贝一下全名称:edu.hao.day02.WordCount_Unbounded
拷贝一下全名称:edu.hao.day02.WordCount_Unbounded
找到jar包文件上传至flink-standalone
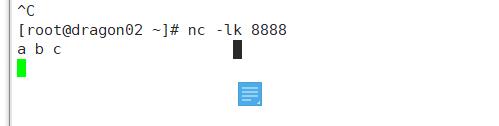
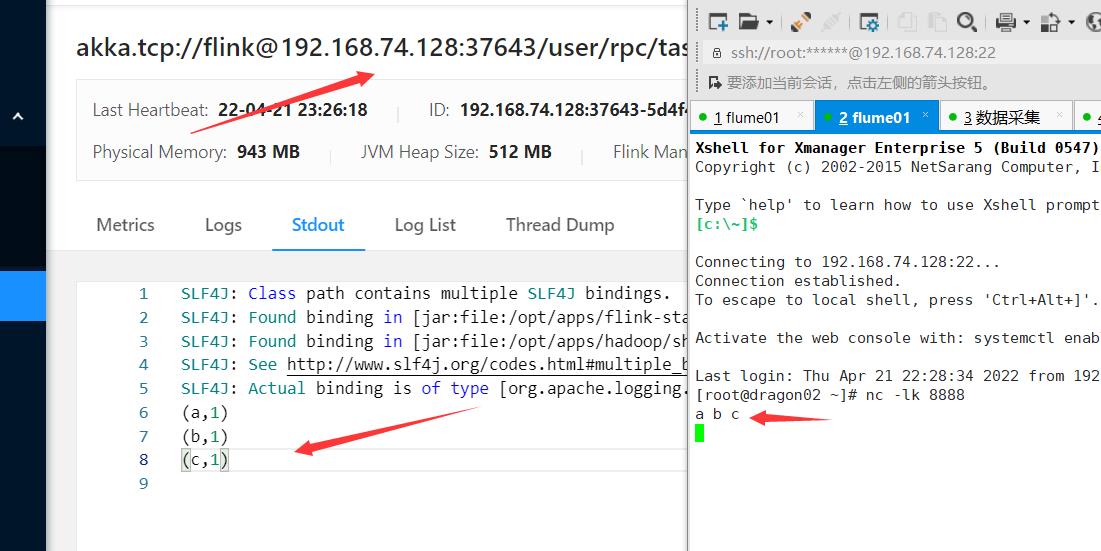
运行,首先复制一下启动nc -lk 8888
[root@dragon02 flink-standalone]# bin/flink run -m dragon02:8081 -c edu.hao.day02.WordCount_Unbounded ./BigData_Flink_Study-1.0-SNAPSHOT.jar 版本不一样
已解决

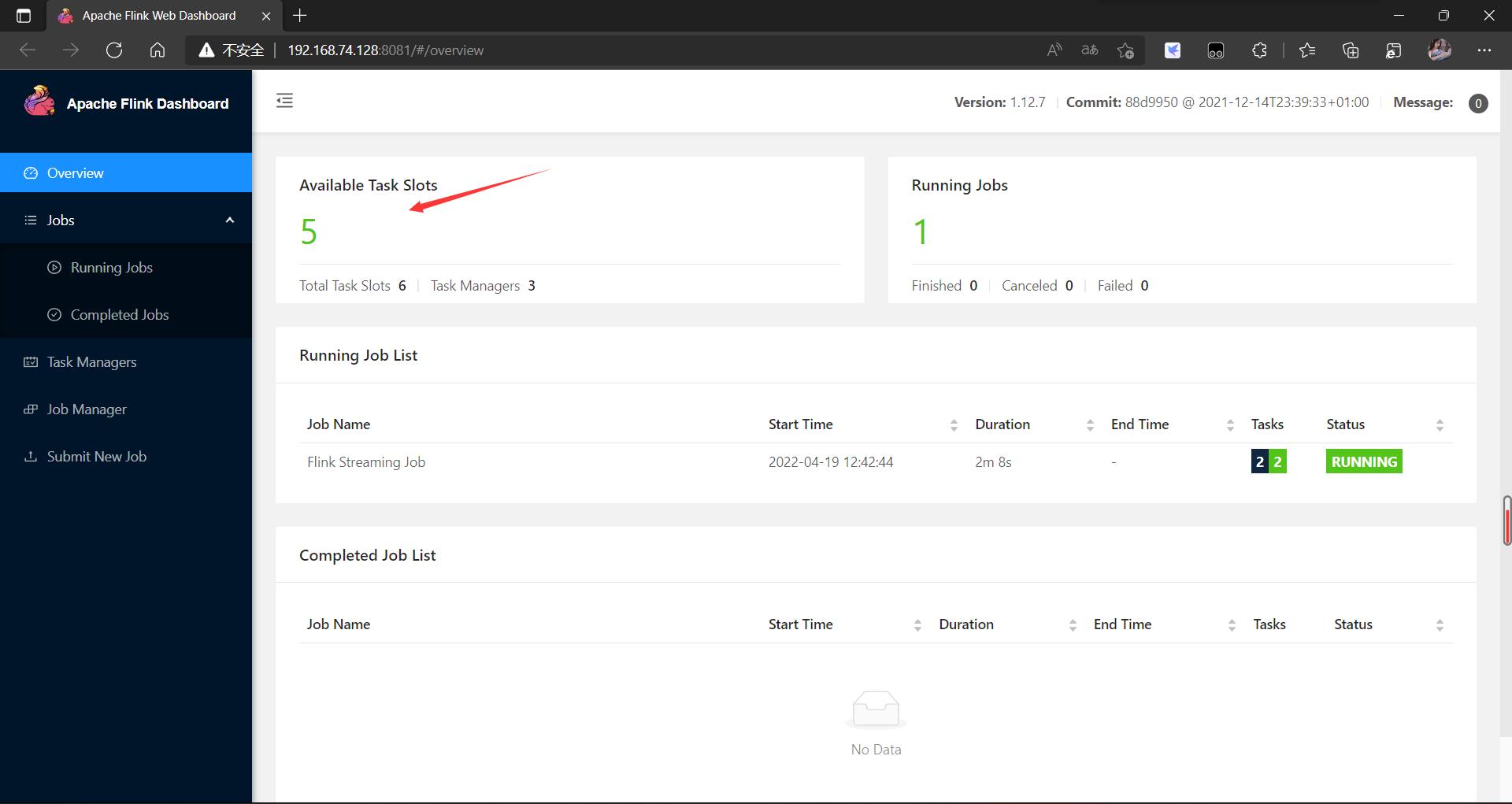
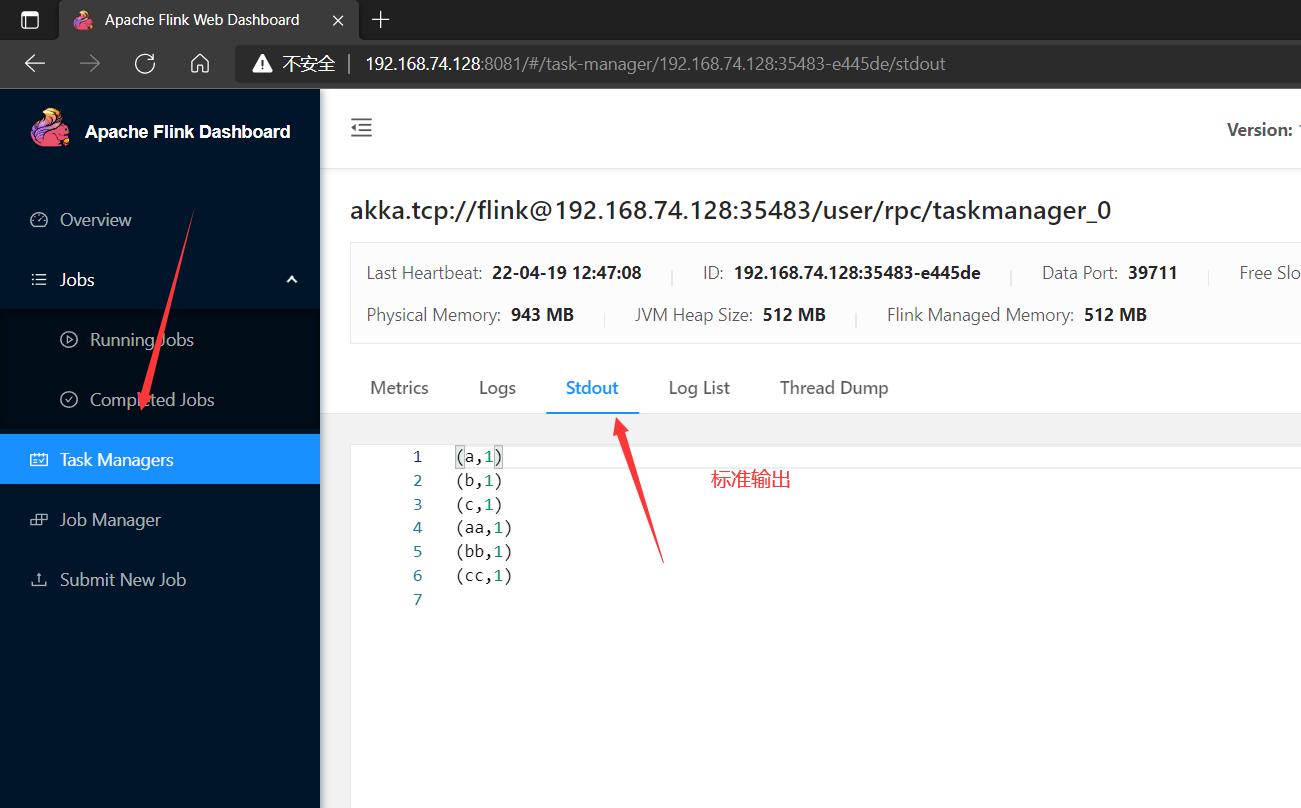 结束进程
结束进程

现在可以停止了bin/./stop-cluster.sh
flink 高可用集群搭建
专门用于计算的框架
有一个SSC被kill了,另一个还可以访问

修改conf文件
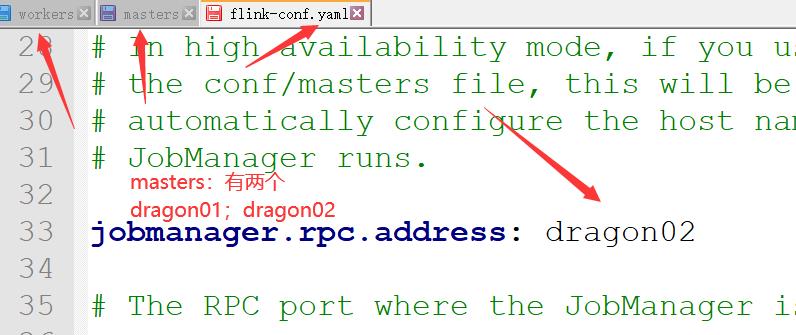 添加
添加
high-availability: zookeeper
high-availability.storageDir: hdfs://dragon02:8020/flink/ha12
high-availability.zookeeper.quorum: dragon01:2181,dragon02:2181,dragon03:2181
high-availability.zookeeper.path.root: /flink-ha12
high-availability.cluster-id: /cluster_hao 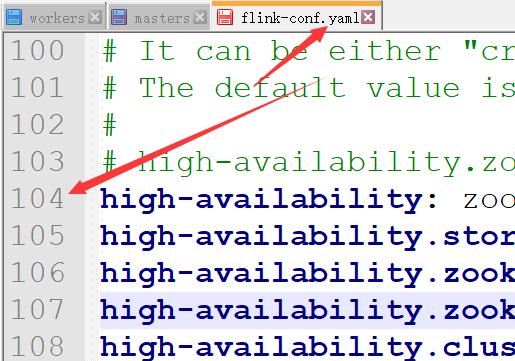
保存并发送
启动zookeeper和dfs
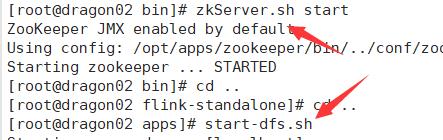
启动高可用集群
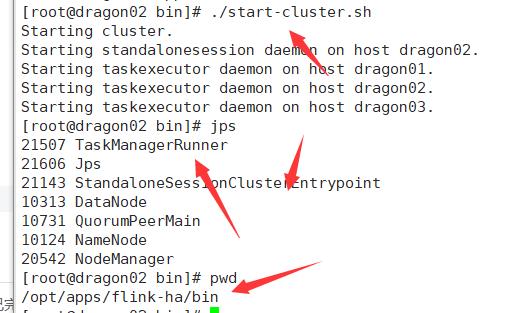
之后操作同上
flink-Yarn模式
分配资源框架
在运行之前处理问题:
在hadoop-2.7.6/logs/yarn-root-resourcemanager-hadoop102.log下查看日志
resourcemanager报错是java.net.BindException: 无法指定被请求的地址。
需要: 如果在完全分布式部署,Namenode和ResourceManger如果不是同一台机器,不能在NodeManager上启动 yarn,应该在ResouceManager所在的机器上启动yarn
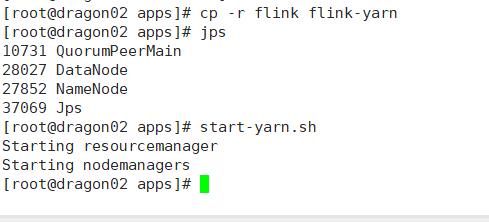
配置环境变量
export HADOOP_CLASSPATH=`hadoop classpath`
现在就可以运行了
由于小编这里在dragon01上面运行着ResourceManager
所以把他放到dragon02上面
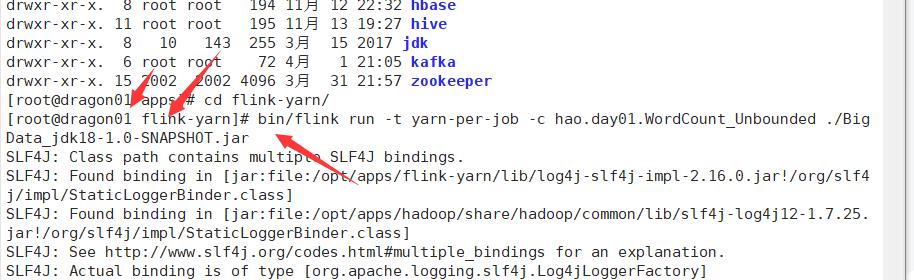
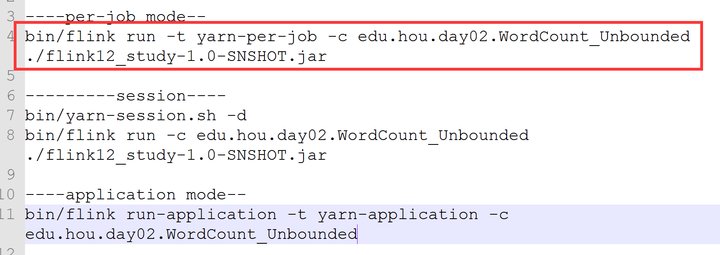
bin/flink run -t yarn-per-job -c hao.day01.WordCount_Unbounded ./BigData_jdk18-1.0-SNAPSHOT.jar

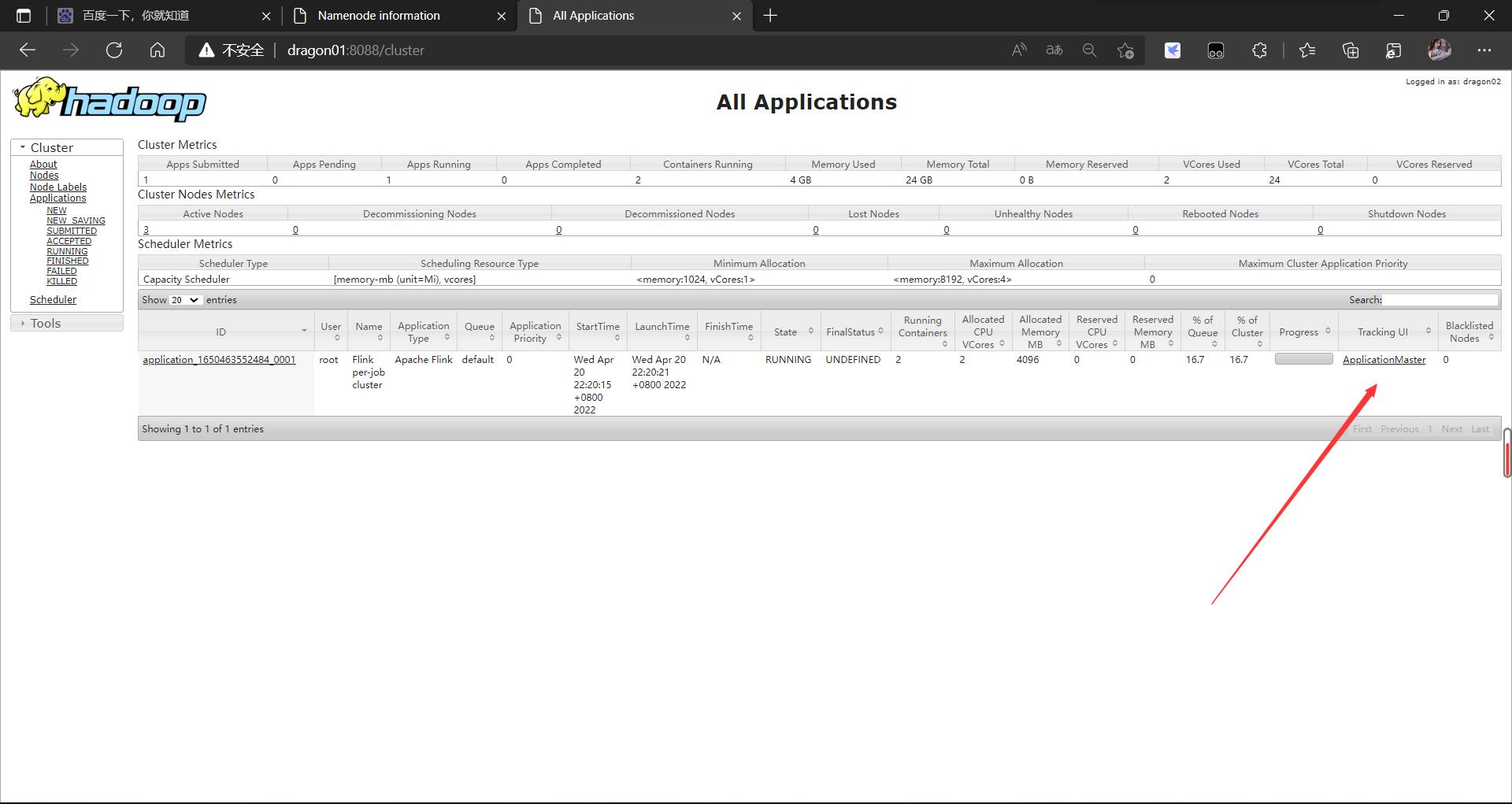
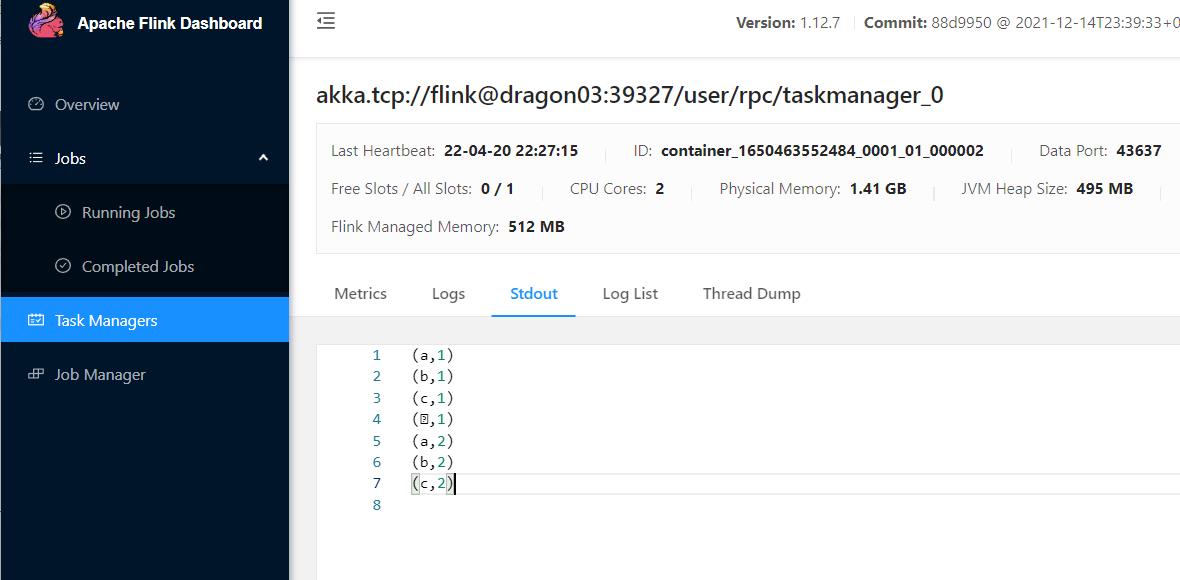
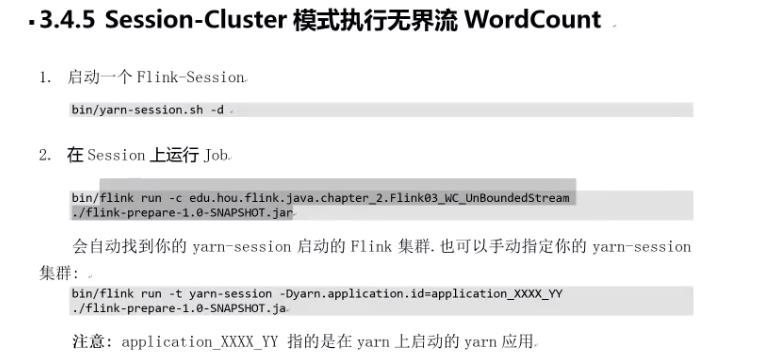
session模式
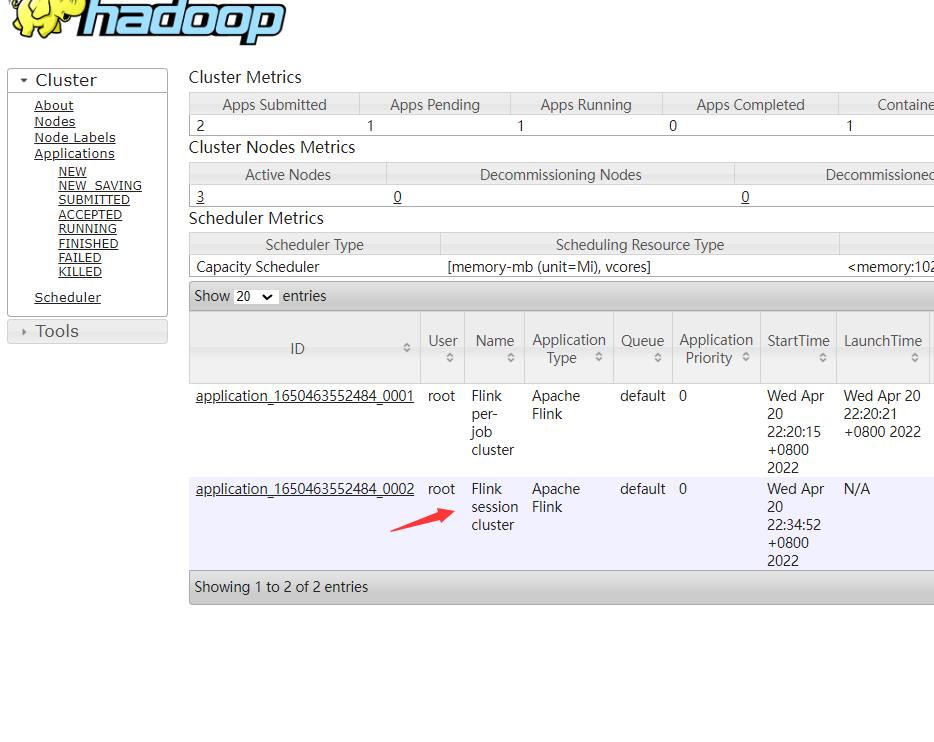
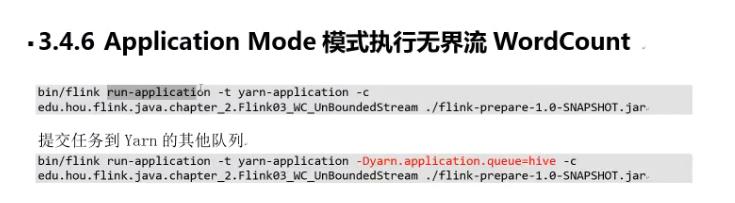

重点
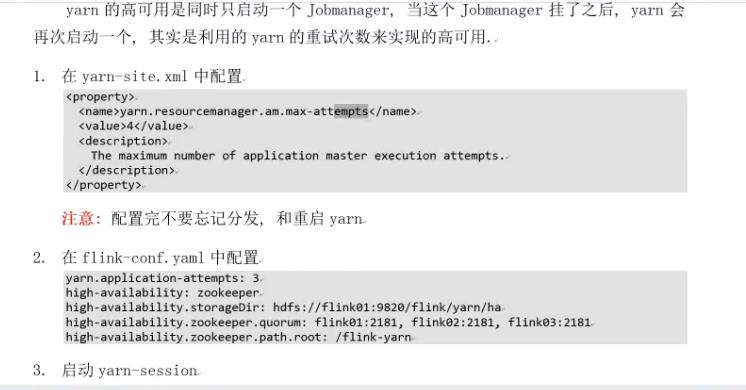
yarn的高可用模式
修改配置文件

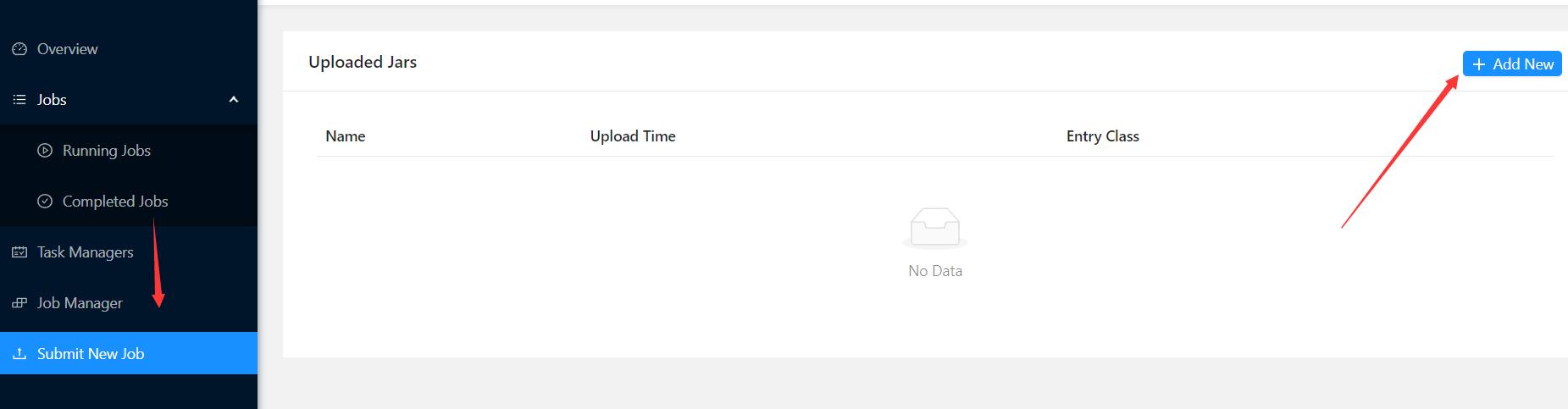
在客户端上直接提交作业
这里我使用的是单机模式的
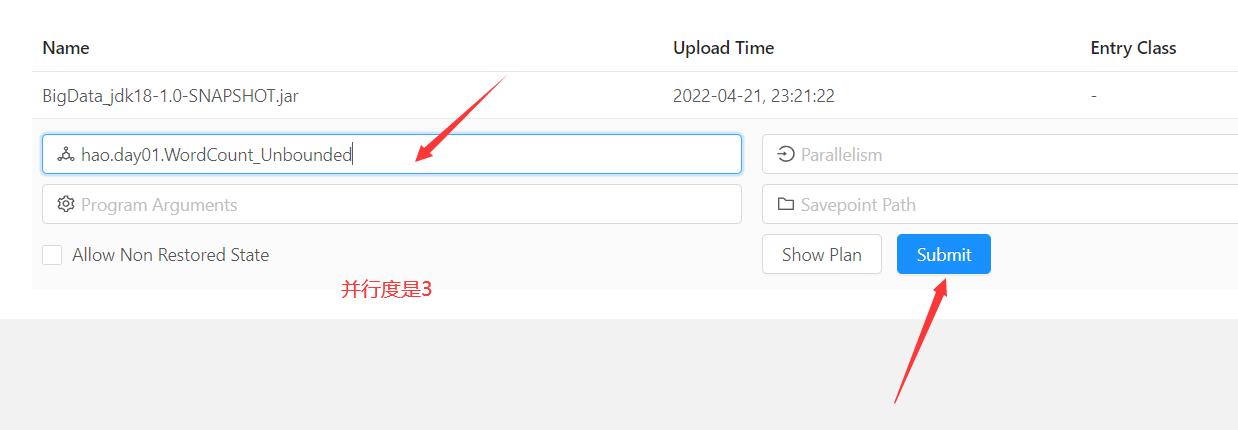
纠正一下:并行度是1
以上是关于Flink部署与实战的主要内容,如果未能解决你的问题,请参考以下文章