[Elasticsearch] 集群的工作原理 - 第二部分
Posted dm_vincent
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Elasticsearch] 集群的工作原理 - 第二部分相关的知识,希望对你有一定的参考价值。
本文翻译自Elasticsearch官方指南的life inside a cluster一章。
增加故障转移(Failover)功能
只运行一个节点意味着可能存在着单点失败(Single point of failure)的问题 - 因为没有冗余。幸运的是,解决这个问题我们只需要启动另一个节点。
启动第二个节点
为了试验当你添加第二节点时会发生什么,你需要像启动第一个节点那样启动第二个节点(参见运行ES),可以在同一个目录下 - 多个节点能够共享相同的目录。
只要第二个节点也拥有和第一个节点相同的
cluster.name(参见./config/elasticsearch.yml文件),它就能够自动地被识别和添加到第一个节点所在的集群中。如果不是这样的话,检查日志来得到错误信息。错误原因可能是你的网络禁用了多播(Multicast),或者存在防火墙阻止了节点间的通信。
如果我们启动了第二个节点,现在的集群会像下面展示的那样:
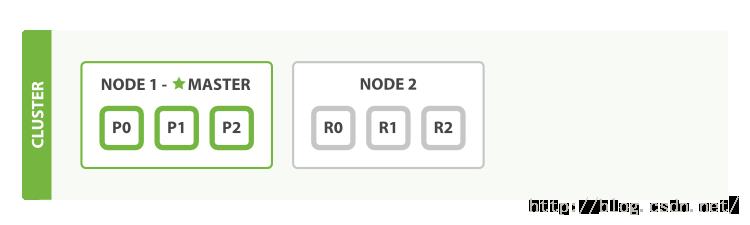
现在第二个节点加入到了集群中,并且三个副本分片也被分配到了该节点上 - 这三个副本分别是三个主分片的副本。这意味着,此时我们如果失去了两个节点中的任何一个,都不会丢失数据。
任何被索引的文档首先都会被保存到主分片上,然后通过并行地方式被拷贝到相关联的副本分片上。这保证了该文档能够通过主分片或者任意一个副本分片获取。
这个时候集群的健康状态会显示为green,表示所有的6个分片(3个主分片和3个副本分片)都是处于活动状态的:
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
此时,我们的集群不仅能够执行正常的功能,也具备了高可用性。
水平扩展(Scale Horizontally)
随着应用的扩展,ES如何对集群进行扩展呢?如果我们启动了第三个节点,那么集群可能会像如下所示的那样重新组织自身的结构:
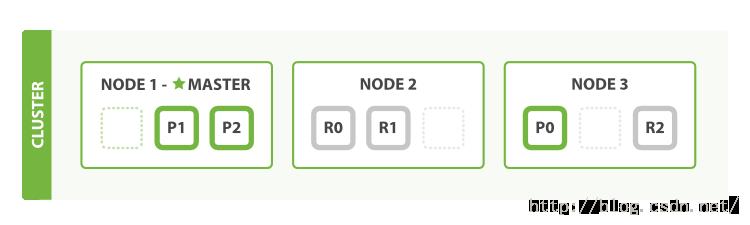
节点1和节点2中各有一个分片现在被移动到了新的节点3中,此时每个节点上都有2个分片,而不是原来的3个。这意味着每个节点上的硬件资源(CPU,RAM,I/O)能够被更少的分片所享有,从而提高每个分片的性能。
每个分片本身就是一个完整的搜索引擎,它能够完全地利用一个节点上的所有资源。因此,在拥有6个分片(3主,3副本)的情况下,我们的集群最多可以扩展到6个节点,此时每个节点上只有1个分片,因此每个分片就能够拥有该节点100%的资源。
如果继续扩展
如果我们想扩展到多于6个节点呢?
在建立索引的时候,主分片的数量就被固定下来了。实际上,这个数量决定了该索引中能够存储的最大数据量。(实际数量取决于你的数据特征和你的硬件)。但是,对于读请求 - 搜索或者获取文档 - 能够被主分片或者副本分片处理,因此当数据有越多的副本,也就意味着搜索的吞吐量能够更高。
副本分片的数量能够在一个活动的集群上动态修改,这就允许我们能够根据需要进行集群规模的调整。让我们将当前的副本分片数量从1调整到2:
PUT /blogs/_settings
"number_of_replicas" : 2
调整后的组织如下所示:
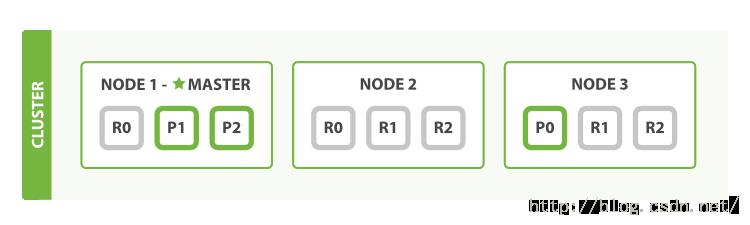
现在blogs索引中就存在9个分片了:3个主分片和6个副本分片。这意味着现在我们可以最多扩展到9个节点,每个节点中只有一个分片。这能够让搜索性能相比原来的3个节点,提升3倍。
NOTE 当然,仅增加副本分片的数量而不增加节点的数量是不会对性能有任何提高的。这是因为在该情况下,每个分片只会得到其所在节点的一部分资源。你需要增加硬件资源来提高吞吐量。
但是这些新添加的副本无疑增加了数据的冗余:像上图那样配置的话,我们现在能够做到即便丢失了两个节点也不会丢失数据。
应对失败
我们说过ES能够应对节点失败的情况,所以让我们试一试。如果我们杀死了第一个节点,那么此时的节点会变成这样:
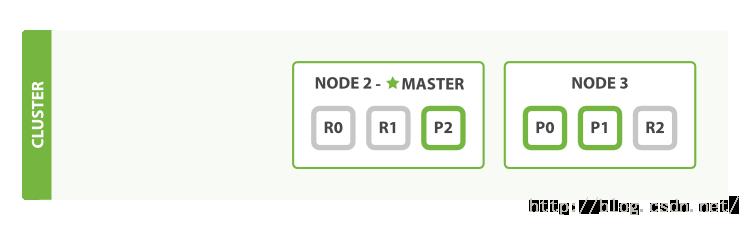
被杀死的节点是主节点(Master Node)。一个集群中必须有一个主节点来保证集群能够正常工作,所以第一件事就是剩下的节点会选出一个新的主节点:比方说节点2。
当我们杀死节点1的时候,同时也丢失了主分片1和主分片2,当缺少了主分片的时候索引是不能正常工作的。此时如果检查集群的健康状态,我们会毫无疑问的得到一个red:不是所有的主分片都处于活动状态!
幸运的是,丢失的两个主分片的副本分片完好无损的存在于其它的节点上,所以被选为主节点的节点2首先需要做的就是提升节点2和节点3中的相应副本分片,让它们成为主分片。此时集群的状态就会变成yellow:所有的主分片又处于活动状态了。对于分片的提升是会立即启动的,就像扳动开关那样。
那么我们的集群为什么是yellow,而不是green?我们有3个主分片,但是我们指定了每个主分片需要有2个副本分片,但是当前我们只能分配1个副本分片(译注:因为此时我们只有两个节点,相同数据不能同时存储于一个节点上)。这导致了集群的状态变为green,但是这里我们并不需要过分担心:假设我们杀死了节点2,应用还是能够在不丢失数据的情况下继续运行,因为节点3还是保存了每个分片的拷贝。
如果我们重启节点1,此时集群又能够对尚未分配的副本分片进行分配了,因此就恢复到了类似下图这种组织结构:
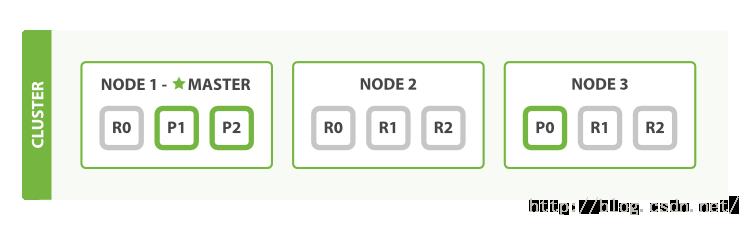
如果节点1中仍然存在之前的分片,那么它会尝试继续使用它们,只不过需要从对应的主分片中将最新的变化数据拷贝回来。
现在你应该对ES如何利用分片来实现水平扩展和如何保证数据安全有所了解了。在后面我们还会介绍关于分片的更多细节。
以上是关于[Elasticsearch] 集群的工作原理 - 第二部分的主要内容,如果未能解决你的问题,请参考以下文章