[人工智能-综述-9]:科学计算大数据分析人工智能机器学习深度学习全面比较
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-综述-9]:科学计算大数据分析人工智能机器学习深度学习全面比较相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/124245520
目录
第1章 scikit-learn是大数据分析还是人工智能工具?
1.4 Phyton的传统的机器学习库scikit-learn
第1章 scikit-learn是大数据分析还是人工智能工具?
1.1 什么是科学计算
科学计算是指利用计算机再现、预测和发现客观世界运动规律和演化特征的全过程。
科学计算为解决科学和工程中的数学问题利用计算机进行的数值计算。
科学计算即是数值计算,科学计算是指应用计算机处理科学研究和工程技术中所遇到的数学计算。在现代科学和工程技术中,经常会遇到大量、复杂的数学计算问题,这些问题用一般的计算工具来解决非常困难,而用计算机来处理却非常容易。
自然科学规律通常用各种类型的数学方程式表达,科学计算的目的就是寻找这些方程式的数值解。这种计算涉及庞大的运算量,简单的计算工具难以胜任。
在计算机出现之前,科学研究和工程设计主要依靠实验或试验提供数据,计算仅处于辅助地位。
计算机的迅速发展,使越来越多的复杂计算成为可能。利用计算机进行科学计算带来了巨大的经济效益,同时也使科学技术本身发生了根本变化:传统的科学技术只包括理论和试验两个组成部分,使用计算机后,计算已成为同等重要的第三个组成部分。
1.2 计算机科学计算过程:
主要包括建立数学模型、建立求解的计算方法和计算机实现三个阶段。
(1)建立数学模型
就是依据有关学科理论对所研究的对象确立一系列数量关系,即一套数学公式或方程式。复杂模型的合理简化是避免运算量过大的重要措施。
(2)计算方法
数学模型一般包含连续变量,如微分方程、积分方程。它们不能在数字计算机上直接处理。
为此,先把问题离散化,即把问题化为包含有限个未知数的离散形式(如有限代数方程组),然后寻找求解方法。
(3)计算机实现
计算机实现包括编制程序、调试、运算和分析结果等一系列步骤。
软件技术的发展,为科学计算提供了合适的程序语言(如Fortran、ALGOL,Python)和其他软件工具,使工作效率和可靠性大为提高。
计算机科学计算处理的对象是数据,处理的过程是算法,处理的结果是预测结果。
1.3 Python的科学计算库
python提供了大量的用于科学计算的库 ,用于开发基于科学计算相关的应用程序的开发,包括数值运算、符号运算、二维图表、三维数据可视化、三维动画演示、图像处理以及界面设计扥扥。
这些库包括:
(1)NumPy
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。
这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
(2)SciPy
是一个用于数学、科学、工程领域的常用软件包,可以处理最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理、图像处理、常微分方程求解器等。
NumPy 和 SciPy 的协同工作可以高效解决很多问题,在天文学、生物学、气象学和气候科学,以及材料科学等多个学科得到了广泛应用。
(3)SymPy
在实际进行数学运算的时候,其实有两种运算模式,一种是数值运算,一种是符号运算(代数)。而我们日常使用计算机进行数值运算,尤其是比如除、开平方等运算时,往往只能得到其近似值(一般通过扩大精度来缩小误差),最终总会已一定的误差,如果使用符号运算模式,则可以完全避免此种问题,符号运算可极大的避免在需要大量运算过程中,造成的累积性误差问题。
当然,符号计算体系(代数),还可以做比如多项式合并、展开、求极限、求和、多重求和、求导、求积分等等工作,如果能熟练运用,会为工作和计算效率带来极大提升。
Sympy是一个符号计算的Python库。它的目标是成为一个全功能的计算机代数系统,同时保持代码简洁、易于理解和扩展。它完全由Python写成,不依赖于外部库。SymPy支持符号计算、高精度计算、模式匹配、绘图、解方程、微积分、组合数学、离散 数学、几何学、概率与统计、物理学等方面的功能。
(4)matplotlib
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
(5)Traits
Python作为一种动态编程语言,它没有变量类型,这种灵活性给快速开发带来了很多便利,不过它也有缺点。Traits库的一个很重要的目的就是为了解决这些缺点所带来的问题。
(6)OpenCV
OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库。
是专用于计算机视觉领域的科学计算机库,它处理的对象是图像的像素,处理的过程就是计算机视觉的算法,处理的结果是处理后的图像和图像中包含的内容。
1.4 Phyton的传统的机器学习库scikit-learn
Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库 ,它是SciPy科学库的在机器学习领域的扩展。
它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
因此,cikit-learn首先是python的科学计算库,其次,它是专用于传统的机器学习领域的科学计算库。
1.5 科学计算在无线通信基站中的应用
(1)物理层的编码与解码(如LDPC)
(2)物理层频域到时域的转换(傅里叶变换与逆变换)
(3)无线信道的评估
第2章 大数据与人工智能的比较
2.1 什么是大数据
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合。大数据首先它是数据,其二是数据规模非常庞大,超出了传统的数据处理的能力。
大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换而言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。
大数据具有鲜明的如下特征:
(1)海量的数据规模:数据的规模高达上亿,远超过人类大脑处理的能力。
(2)快速的数据流转:数据的变化非常快,非常实时,就需要对数据进行快速的及时的收集、处理。
(3)多样的数据类型:数据的类型多样化,包括数值、文本、图像、语音等等。
(4)多样的数据特征:超大维度的数据特征,有些数据的维度高达几十万。
(4)密度低的价值:数据的价值被隐藏在超大规模的数据中,单个数据的价值密度低。
(5)结构化的数据:传统的大数据都是结构化数据,数据的特征,无论维度多大,都是有明确含义的结构化特征,是经过人工结构化的数据。结构化数据是传统大数据和机器学习的重要特征。
2.2 什么是人工智能

(1)什么是人工智能
人工智能的概念最早来自于1956年的计算机达特茅斯会议,其本质是希望机器能够像人类的大脑一样思考,并作出反应。由于极具难度与吸引力,人工智能从诞生至今,吸引了无数的科学家与爱好者投入研究。
(2)搭载人工智能的载体和形态可以是多样的:
- 各种形态的机器人(各种终端机器人)
- 自动驾驶车辆(自动驾驶领域,汽车之身的机器人)
- 部署在云端的智能大脑(互联网大厂主要在这个领域)
(3)智能水平
根据人工智能实现的水平,我们可以进一步分为3种人工智能:
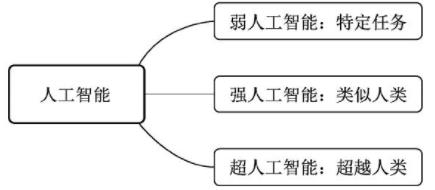
- 弱人工智能(Artificial Narrow Intelligence,ANI):
擅长某个特定任务的智能。例如自然语言处理领域的谷歌翻译,让该系统去判断一张图片中是猫还是狗,就无能无力了。再比如垃圾邮件的自动分类、自动驾驶车辆、手机上的人脸识别等,当前的人工智能大多是弱人工智能。
- 强人工智能(这是我个人的梦想)
在人工智能概念诞生之初,人们期望能够通过打造复杂的计算机,实现与人一样的复杂智能,这被称做强人工智能,也可以称之为通用人工智能(Artificial General Intelligence,AGI)。
这种智能要求机器像人一样,听、说、读、写样样精通。目前的发展技术尚未达到通用人工智能的水平,但已经有众多研究机构展开了研究。
- 超人工智能(Artificial Super Intelligence,ASI):
在强人工智能之上,是超人工智能,其定义是在几乎所有领域都比人类大脑聪明的智能,包括创新、社交、思维等。
人工智能科学家Aaron Saenz曾有一个有趣的比喻,现在的弱人工智能就好比地球早期的氨基酸,可能突然之间就会产生生命。超人工智能不会永远停留在想象之中。
(4)人工智能的本质
人工智能的本质是科学计算,即用科学计算的方法为特定的人工智能的应用场合(如视觉、听觉)建立数学模型,并对采集到数据进行科学计算,获得数据中包含的信息的过程。
2.3 什么是机器学习
学习能力是人的大脑一个极其重要的能力,人工智能也需要让机器具备类似人类这样的能力。
机器学习是实现人工智能的重要途径,也是最早发展起来的人工智能算法。与传统的基于规则设计的算法不同,机器学习的关键在于:从大量的数据中找出规律,自动地学习出算法所需的参数。(与大数据有着某种内在的相似性)
机器学习最早可见于1783年的贝叶斯定理中。贝叶斯定理是机器学习的一种,根据类似事件的历史数据得出发生的可能性。在1997年,IBM开发的深蓝(DeepBlue)象棋电脑程序击败了世界冠军。当然,最令人振奋的成就还当属2016年打败李世石的AlphaGo。
机器学习算法中最重要的就是数据,根据使用的数据形式:
可以分为三大类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)与强化学习(Reinforcement Learning)。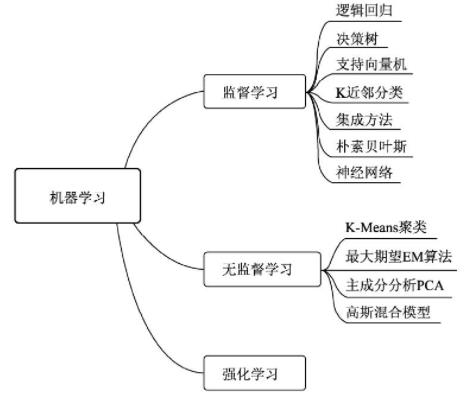
(1)监督学习:有标签、有答案的数据
通常包括训练与预测阶段。
在训练时利用带有人工标注标签的数据对模型进行训练,在预测时则根据训练好的模型对输入进行预测。
监督学习是相对成熟的机器学习算法。
监督学习通常分为分类与回归两个问题,常见算法有决策树(Decision Tree,DT)、支持向量机(Support Vector Machine,SVM)和神经网络等。
(2)无监督学习:没有标签、没有答案的数据
输入的数据没有标签信息,也就无法对模型进行明确的惩罚。
无监督学习常见的思路是采用某种形式的回报来激励模型做出一定的决策,常见的法有K-Means与主成分分析(Principall Component Analysis,PCA)。
(3)强化学习:具有奖罚机制的机器学习
让模型在一定的环境中学习,每次行动会有对应的奖励,目标是使奖励最大化,被认为是走向通用人工智能的学习方法。常见的强化学习有基于价值、策略与模型3种方法。
2.4 什么是深度学习
深度学习是机器学习的技术分支之一,主要是通过计算机的方法,模拟人的大脑,通过搭建深层的人工神经网络(Artificial Neural Network)来进行知识的学习,输入数据通常较为复杂、规模大、维度高。深度学习可以说是机器学习问世以来最大的突破之一。
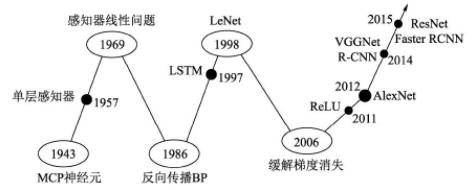
最早的神经网络可以追溯到1943年的MCP(McCulloch and Pitts)人工神经元网络,希望使用简单的加权求和与激活函数来模拟人类的神经元过程。
在此基础上,1958年的感知器(Perception)模型使用了梯度下降算法来学习多维的训练数据,成功地实现了二分类问题,也掀起了深度学习的第一次热潮。
下图代表了一个最简单的单层感知器,输入有3个量,通过简单的权重相加,再作用于一个激活函数,最后得到了输出y。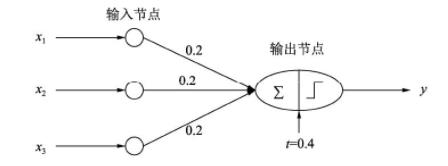
然而,1969年,Minsky证明了感知器仅仅是一种线性模型,对简单的亦或判断都无能为力,而生活中的大部分问题都是非线性的,这直接让学者研究神经网络的热情难以持续,造成了深度学习长达20年的停滞不前。
1986年,深度学习领域“三驾马车”之一的Geoffrey Hinton创造性地将非线性的Sigmoid函数应用到了多层感知器中,并利用反向传播(Back propagation)算法进行模型学习,使得模型能够有效地处理非线性问题。1998年,“三驾马车”中的卷积神经网络之父Yann LeCun发明了卷积神经网络LeNet模型,可有效解决图像数字识别问题,被认为是卷积神经网络的鼻祖。
然而在此之后的多年时间里,深度学习并没有代表性的算法问世,并且神经网络存在两个致命问题:一是Sigmoid在函数两端具有饱和效应,会带来梯度消失问题;另一个是随着神经网络的加深,训练时参数容易陷入局部最优解。这两个弊端导致深度学习陷入了第二次低谷。在这段时间内,反倒是传统的机器学习算法,如支持向量机、随机森林等算法获得了快速的发展。
2006年,Hinton提出了利用无监督的初始化与有监督的微调缓解了局部最优解问题,再次挽救了深度学习,这一年也被称为深度学习元年。2011年诞生的ReLU激活函数有效地缓解了梯度消失现象。
真正让深度学习迎来爆式发展的当属2012年的AlexNet网络,其在lmageNet图像分类任务中以“碾压”第二名算法的姿态取得了冠军。深度学习从此一发不可收拾,VGGNet、ResNe等优秀的网络接连问世,并且在分类、物体检测、图像分割等领域渐渐地展现出深度学习的实力,大大超过了传统算法的水平。
2.5 深度学习的本质
深度学习的发展离不开大数据、GPU及模型这3个因素,如图所示。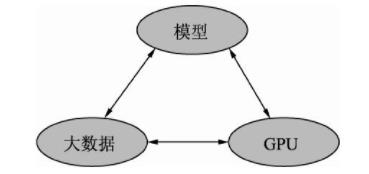
(1)大数据(输入)
当前大部分的深度学习模型是有监督学习,依赖于数据的有效标注。例如,要做一个高性能的物体检测模型,通常需要使用上万甚至是几十万的标注数据。数据的积累也是一个公司深度学习能力雄厚的标志之一,没有数据,再优秀的模型也会面对无米之炊的尴尬。
在处理非结构化的大数据时,传统机器学习算法已经无法应对时,深度学习的价值就凸显出来了。
(2)GPU(并行计算的硬件)
深度学习如此“火热”的一个很重要的原因就是硬件的发展,尤其是GPU为深度学习模型的快速训练提供了可能。
深度学习模型通常有数以千万计的参数,存在大规模的并行计算,传统的以逻辑运算能力著称的CPU面对这种并行计算会异常缓慢,GPU以及CUDA计算库专注于数据的并行计算,为模型训练提供了强有力的工具。
(3)模型(算法)
在大数据与GPU的强有力支撑下,无数研究学者的奇思妙想,催生出了VGGNet、ResNet和FPN等一系列优秀的深度学习模型,并且在学习任务的精度、速度等指标上取得了显著的进步。
因此,深度学习的本质还是科学计算,是大数据和GPU并行计算下的科学计算!!!
2.6 机器学习与深度学习异同
(1)相同点
- 都是人工智能
- 都是机器学习
- 都是科学计算
(2)不同点
- 模型:机器学习的模型是专用的算法,深度学习是通用的深度神经网络。
- 数据:机器学习是结构化数据,深度学习是非结构化数据。
- 特征:机器学习是人为确定数据的特征,深度学习是神经网络自动发现数据的特征(特征提取网络)
2.7 大数据与人工智能的相同点
(1)都是科学计算
(2)都是以数学为根基
(3)都是从一堆数据中发现规律
(4)都需要建立数学模型
(5)都是让机器辅助人脑解决现实问题。
2.8 大数据与人工智能的不同点
(1)关注的重点不同
大数据的核心是“大数据”,从海量的数据中发现数据的规律;
人工智能重在机器的“智能”,不一定需要大数据。
(2)替代人大脑的部件不同
大数据主要替代大脑的数学计算。
人工智能主要模拟大脑的视觉、听觉、知觉、认知系统,即五官。
(3)数据集
大数据通常处理的机构化数据,这是样本的数量、规模,特征的数量和规模比较庞大而已,都终极都是结构化数据。
而人工智能中的深度学习,这处理的是非结构化数据,深度神经网络自己发现隐藏在数据内部的特征。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/124245520
以上是关于[人工智能-综述-9]:科学计算大数据分析人工智能机器学习深度学习全面比较的主要内容,如果未能解决你的问题,请参考以下文章