Elasticsearch入门 API
Posted 虎鲸不是鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch入门 API相关的知识,希望对你有一定的参考价值。
Elasticsearch入门(二) API
VSCode部署
使用RESTful API操作ES,VSCode是个好工具。
VSCode官网免费的。。。
最好把这两插件也安装好:
Chinese (Simplified) Language Pack for Visual Studio Code
Elasticsearch for VSCode
一个是汉化包,一个是开发ES需要的拓展包。开发ES需要new一个.es或者打开一个已有的.es文件才能编辑。。。如果不小心关闭了连接地址栏,可以右键→命令面板→set host:

输入node1:9200即可连接:

--标准分词
post _analyze
"analyzer":"standard",
"text":"好喜欢数码宝贝"
--IK分词
post _analyze
"analyzer":"ik_max_word",
"text":"好喜欢数码宝贝"
简单测试下,点Run Query就能运行,发现标准分词:
"tokens": [
"token": "好",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
,
"token": "喜",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
,
"token": "欢",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
,
"token": "数",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
,
"token": "码",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
,
"token": "宝",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
,
"token": "贝",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
]
一个字一个字划分的。。。好吧。。。IK分词:
"tokens": [
"token": "好喜欢",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
,
"token": "喜欢",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
,
"token": "数码宝贝",
"start_offset": 3,
"end_offset": 7,
"type": "CN_WORD",
"position": 2
,
"token": "数码",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 3
,
"token": "宝贝",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
]
好家伙,连数码宝贝都能划分出来。。。真强。。。
RESTful API
索引库管理
列举索引
GET _cat/indices
这句类似mysql中的show databases;用于查询当前所有索引库:
[]
当然目前还没有。。。
创建job_idx索引库
PUT /job_idx
"mappings":
"properties" :
"area": "type": "text", "store": true, "analyzer": "ik_max_word",
"exp": "type": "text", "store": true, "analyzer": "ik_max_word",
"edu": "type": "keyword", "store": true,
"salary": "type": "keyword", "store": true,
"job_type": "type": "keyword", "store": true,
"cmp": "type": "text", "store": true, "analyzer": "ik_max_word",
"pv": "type": "keyword", "store": true,
"title": "type": "text", "store": true, "analyzer": "ik_max_word",
"jd": "type": "text", "store": true, "analyzer": "ik_max_word"
,
"settings" :
"number_of_shards":5,
"number_of_replicas" : 1
其中:
mappings:用于做列的定义
type:类型
store:存储原始数据
analyzer:分词器的类型
index:是否对这列构建索引,默认为true
settings:集群配置管理
"number_of_shards":5,:这个索引库有5个分区
"number_of_replicas" : 1:副本个数为1
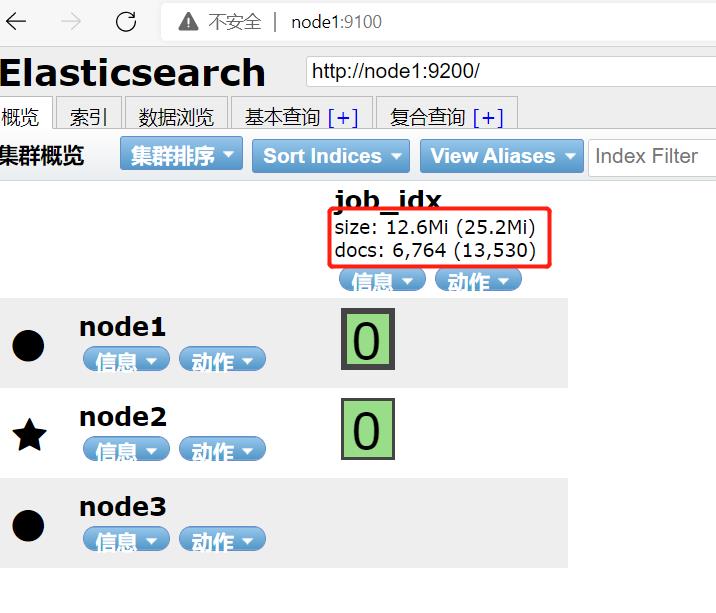
运行后,在浏览器node1:9200:
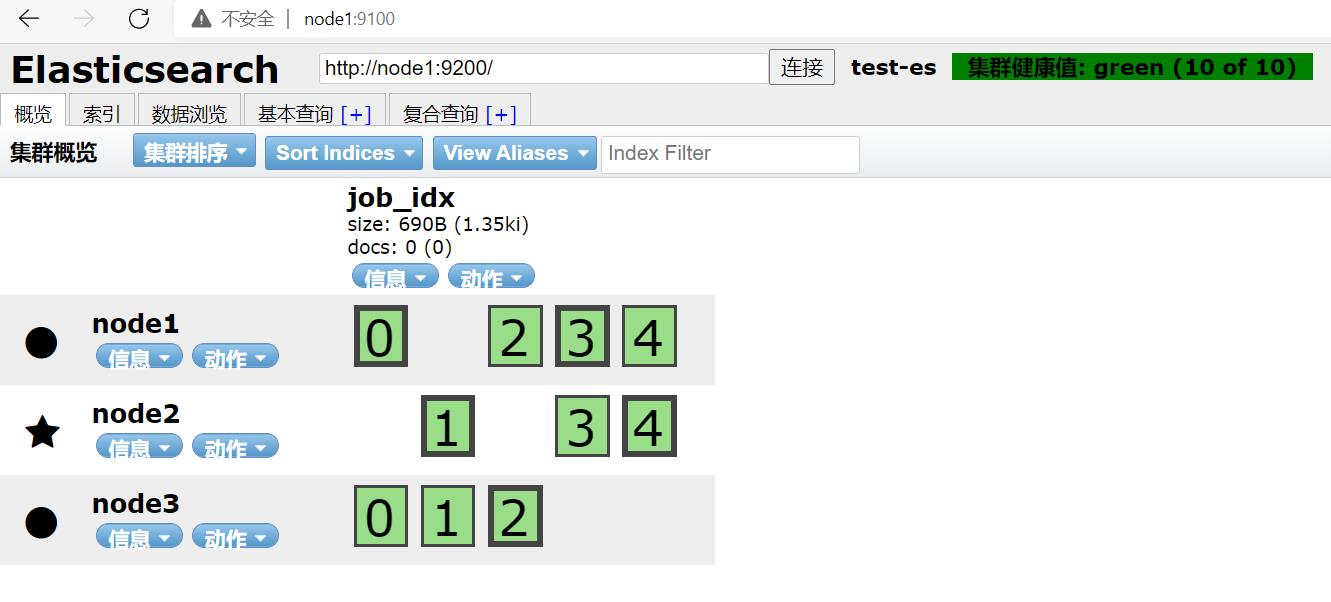
(边框加粗的是Leader分区,边框细的是Follower分区)
5个分区和1倍数的备份。。。和预期一致。。。
查看索引
GET /job_idx/_mapping
GET /job_idx/_settings
也可以在网页端:
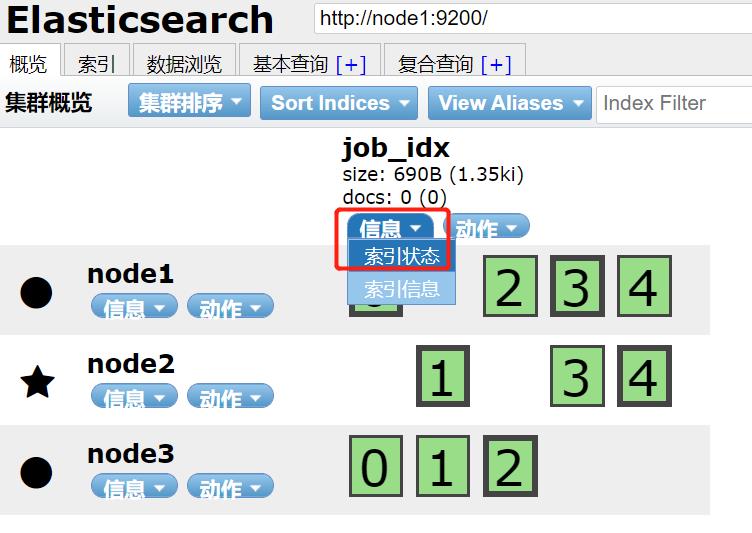
信息→索引状态/索引信息查看。
删除索引
delete /job_idx
执行后网页端刷新,不再有内容。
数据管理
数据插入
按照这种套路:
put /index/_doc/doc_id
JSON:每一列的数据
可以插入数据。例如:
PUT /job_idx/_doc/29097
"area": "深圳-南山区",
"exp": "1年经验",
"edu": "大专以上",
"salary": "6-8千/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "61.6万人浏览过 / 14人评价 / 113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "薪酬待遇】 本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,善思考: 热衷于用户心理研究,善于从用户数据中提炼用户需求,利用个性化、精细化运营手段,提升用户体验。 【岗位要求】 1.18-26周岁,自考大专以上学历; 2.具有良好的亲和力、理解能力、逻辑协调和沟通能力; 3.积极乐观开朗,为人诚实守信,工作积极主动,注重团队合作; 4.愿意服务于高端客户,并且通过与高端客户面对面沟通有意愿提升自己的综合能力; 5.愿意参加公益活动,具有爱心和感恩之心。 【培养路径】 1.上千堂课程;房产知识、营销知识、交易知识、法律法规、客户维护、目标管理、谈判技巧、心理学、经济学; 2.成长陪伴:一对一的师徒辅导 3.线上自主学习平台:乐有家学院,专业团队制作,每周大咖分享 4.储备及管理课堂: 干部训练营、月度/季度管理培训会 【晋升发展】 营销【精英】发展规划:A1置业顾问-A6资深置业专家 营销【管理】发展规划:(入职次月后就可竞聘) 置业顾问-置业经理-店长-营销副总经理-营销副总裁-营销总裁 内部【竞聘】公司职能岗位:如市场、渠道拓展中心、法务部、按揭经理等都是内部竞聘 【联系人】 黄媚主任15017903212(微信同号)"
执行后result.json显示内容为:
"_index": "job_idx",
"_type": "_doc",
"_id": "29097",
"_version": 1,
"result": "created",
"_shards":
"total": 2,
"successful": 2,
"failed": 0
,
"_seq_no": 0,
"_primary_term": 1
在网页端刷新后在数据浏览分栏看到:
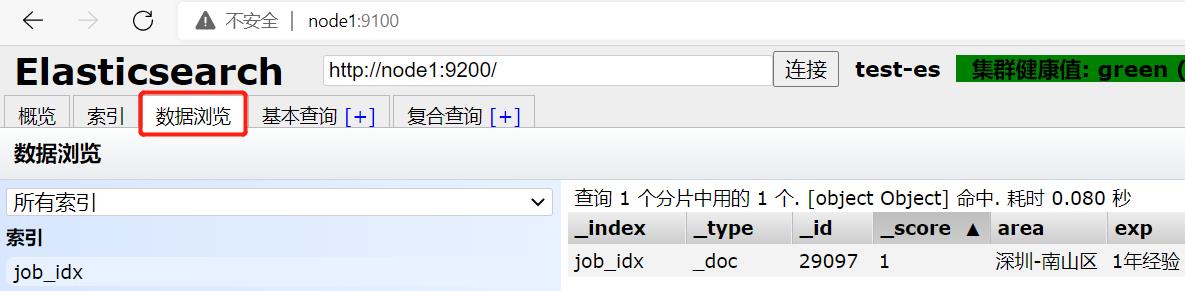
数据更新
可以这样:
POST /job_idx/_update/29097
"doc":
"salary": "15-20千/月"
删除数据
DELETE /job_idx/_doc/29097
右侧的result.json会显示:
"_index": "job_idx",
"_type": "_doc",
"_id": "29097",
"_version": 2,
"result": "deleted",
"_shards":
"total": 2,
"successful": 2,
"failed": 0
,
"_seq_no": 1,
"_primary_term": 1
显然记录了版本号及删除的信息。
BulkLoad
curl -H "Content-Type: application/json" -XPOST "node1:9200/job_idx/_bulk?pretty&refresh" --data-binary "@job_info.json"
这种方式先将文件上传到Linux再批量加载文件:
数据查询
doc_id查询
类似MySQL根据主键查询。例如:
GET /job_idx/_search
"query":
"ids":
"values": ["46313"]
查询器
GET /job_idx/_search
"query":
"match":
"jd": "销售"
,
"size":"100"
默认值显示10条,使用size标签可以显示多条。
或者使用multi_match实现多列字符串匹配查询器:
GET /job_idx/_search
"query":
"multi_match":
"query": "销售",
"fields": ["title", "jd"]
或者分页查询:
GET /job_idx/_search
"from": 0,
"size": 5,
"query":
"multi_match":
"query": "销售",
"fields": ["title", "jd"]
这种浅分页类似MySQL的limit M,N。from是开始条目的偏移量(第一条为0),size是每页显示的条目数。
自然还有深分页:
第一次查询,会将整个所有数据放在内存中,从第二次开始就从内存中来自动遍历每页的数据。scroll = 1m :做深分页,将查询的结果保存在内存中1分钟。size:每一页显示多少条(能够自动进行翻页)。
例如:
第一次:
GET /job_idx/_search?scroll=1m
"query":
"multi_match":
"query": "销售",
"fields": ["title", "jd"]
,
"size": 100
在result.json中抓取到:
"_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAIWdmVueGpVeHRRd09hX3pWMU1uRUxwQQ==",
之后使用该_scroll_id就可以实现连续翻页:
GET _search/scroll?scroll=1m
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAAnFlJfaWNiQzhvU3YydTJpMUV1OUpIZlEAAAAAAAAAIhZBTEhIaW9WS1NBT3d4X3lKWXNIREN3AAAAAAAAACgWUl9pY2JDOG9TdjJ1MmkxRXU5SkhmUQAAAAAAAAAkFmlfMXlVOHB0VGYtbUFMMUdUd1JFWVEAAAAAAAAAIxZpXzF5VThwdFRmLW1BTDFHVHdSRVlR"
Java API
准备工作
代码太多。。。使用//region和//endregion折叠。。。
导入Maven依赖
pom.xml中:
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
</configuration>
</plugin>
</plugins>
</build>
封装Java Bean对象
package com.aa.esClient.bean;
import com.alibaba.fastjson.annotation.JSONField;
public class JobDetail
//region 封装数据
//无需将id序列化为文档
@JSONField(serialize = false)
private long id; // 唯一标识
private String area; // 职位所在区域
private String exp; // 岗位要求的工作经验
private String edu; // 学历要求
private String salary; // 薪资范围
private String job_type; // 职位类型(全职/兼职)
private String cmp; // 公司名
private String pv; // 浏览量
private String title; // 岗位名称
private String jd; // 职位描述
//endregion
//region get&set
public long getId()
return id;
public void setId(long id)
this.id = id;
public String getArea()
return area;
public void setArea(String area)
this.area = area;
public String getExp()
return exp;
public void setExp(String exp)
this.exp = exp;
public String getEdu()
return edu;
public void setEdu(String edu)
this.edu = edu;
public String getSalary()
return salary;
public void setSalary(String salary)
this.salary = salary;
public String getJob_type()
return job_type;
public void setJob_type(String job_type)
this.job_type = job_type;
public String getCmp()
return cmp;
public void setCmp(String cmp)
this.cmp = cmp;
public String getPv()
return pv;
public void setPv(String pv)
this.pv = pv;
public String getTitle()
return title;
public void setTitle(String title)
this.title = title;
public String getJd()
return jd;
public void setJd(String jd)
this.jd = jd;
//endregion
//region 重写toString方法
@Override
public String toString()
return "JobDetail" +
"id=" + id +
", area='" + area + '\\'' +
", exp='" + exp + '\\'' +
", edu='" + edu + '\\'' +
", salary='" + salary + '\\'' +
", job_type='" + job_type + '\\'' +
", cmp='" + cmp + '\\'' +
", pv='" + pv + '\\'' +
", title='" + title + '\\'' +
", jd='" + jd + '\\'' +
'';
//endregion
封装接口
package com.aa.esClient.service;
import com.aa.esClient.bean.JobDetail;
import java.io.IOException;
import java.util.List;
import java.util.Map;
public interface JobFullTextService
//region 封装方法
//添加一个职位数据
void add(JobDetail jobDetail);
// 修改职位薪资
void update(JobDetail jobDetail) throws IOException;
// 根据ID删除指定位置数据
void deleteById(long id) throws IOException;
// 根据ID检索指定职位数据
JobDetail findById(long id) throws IOException;
以上是关于Elasticsearch入门 API的主要内容,如果未能解决你的问题,请参考以下文章