Spark框架-离线数据统计
Posted 那人独钓寒江雪.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark框架-离线数据统计相关的知识,希望对你有一定的参考价值。
数据清洗
任务简介:


第一小问:
第一步:输出日志(使用spark默认的log4j配置文件)
//此方法要放在主程序的首行,靠后对输出日志控制不起作用
Logger.getLogger("org").setLevel(Level.ERROR)
第二步:创建SparkSession对象(关闭严格模式,否则创建静态分区)
val spark=SparkSession
.builder()
.appName("c_dataClear1")
.master("local")
.config("hive.exec.dynamic.partition.mode","nonstrict")//关闭严格模式,否则会有一个静态分区
//hive元数据仓库目录
.config("hive.metastore.warehouse.dir","hdfs://192.168.3.89:9000/user/hive/warehouse")//目录地址
.enableHiveSupport()
.getOrCreate()
第三步:拿出所有的表并进行清洗
val tableArray=List("customer","lineitem","nation","orders","part","partsupp","region","supplier")//所有数据表的名称
tableArray.foreach(table =>
第四步:删除分区并且统计
//2.删除分区并统计
var odsData=spark.sql(s"select * from ods.$table").drop("part_date")//去除原来字段
val num=odsData.count() //查看数据表结构
println(odsData.schema)//查看数据表的结构
第五步:将对于字段的日期改为timestamp类型
- TimeStamp类型为:yyyy-MM-dd HH:mm:ss
//3.将对于字段的日期改为timestamp类型 格式为:yyyy-MM--dd HH:mm:ss
odsData.columns.foreach(tableName =>
val startIndex=tableName.length -4
val endIndex=tableName.length
if (endIndex >=4)
val tamp=tableName.substring(startIndex,endIndex)//查看每个字段中最后四位是否带有date
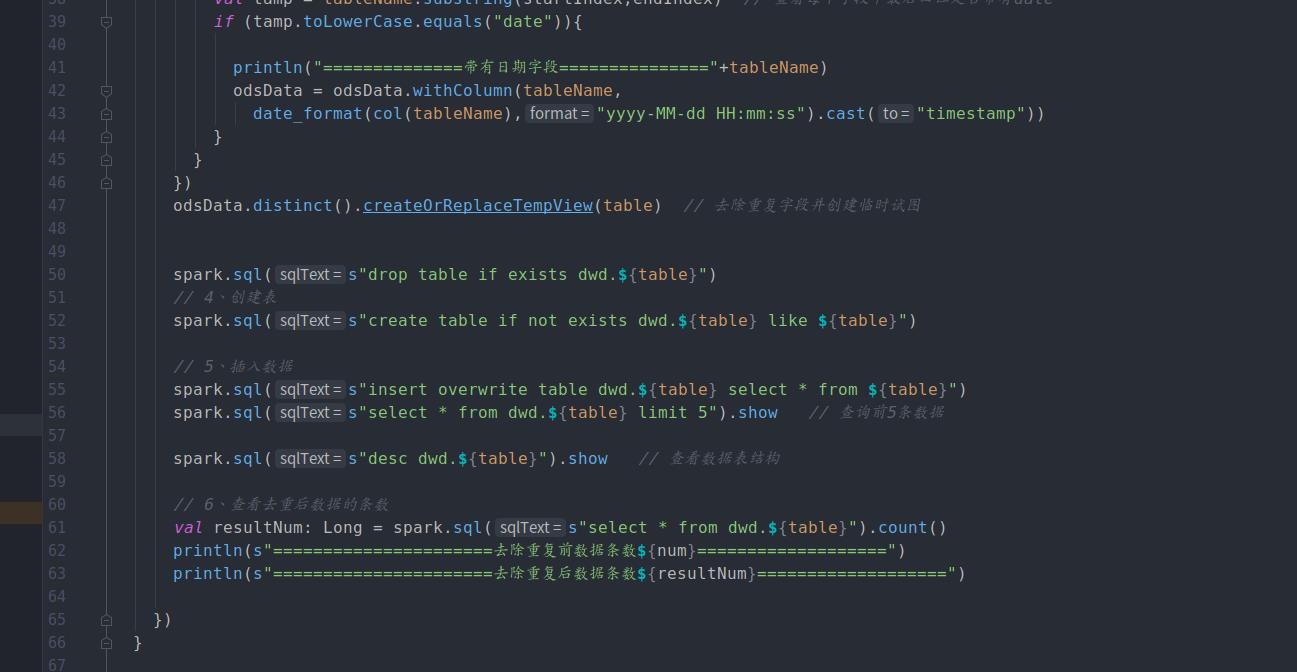
if (tamp.toLowerCase.equals("date"))
println("==================带有日期字段=============="+tableName)
odsData=odsData.withColumn(tableName,
date_format(col(tableName),"yyyy-MM-dd HH:mm:ss").cast("timestamp"))
第六步:去除重复字段并创建临时视图
odsData.distinct().createOrReplaceTempView(table)//去除重复字段并创建临时视图
spark.sql(s"drop table if exists dwd.$table")
//4.创建表
spark.sql(s"create table if not exists dwd.$table like ods.$table")
//5.插入数据
spark.sql(s"insert overwrite table dwd.$table select * from ods.$table")
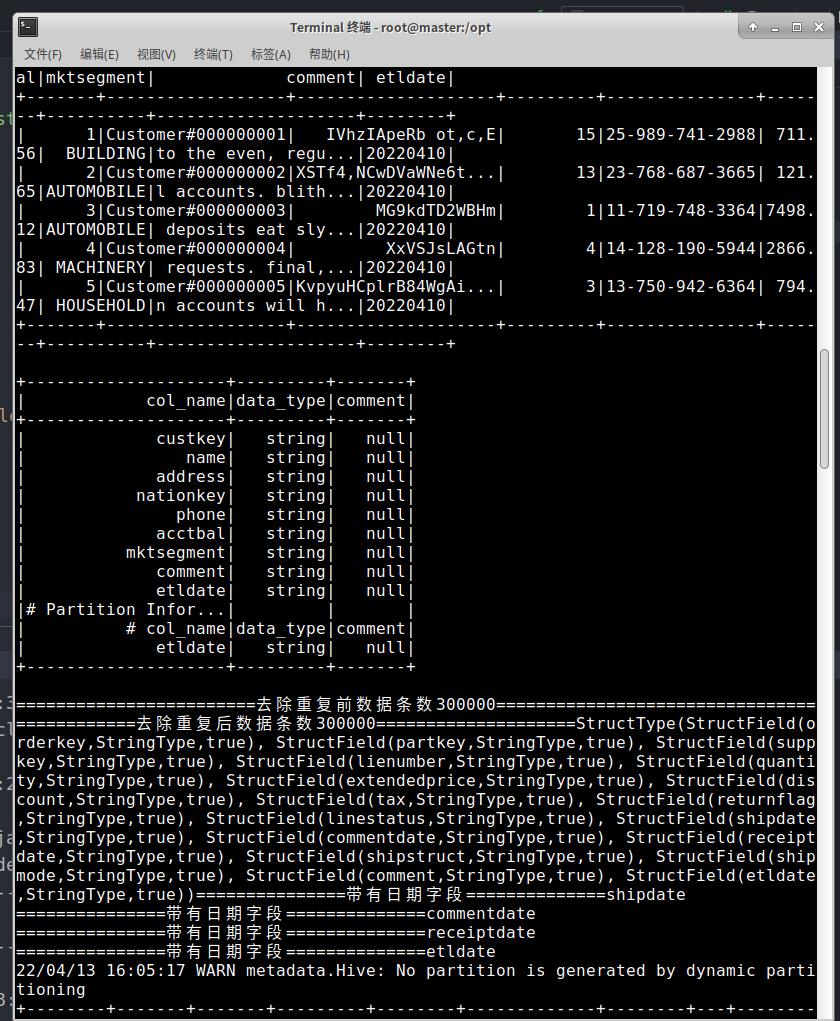
spark.sql(s"select * from dwd.$table limit 5").show //查询前五条数据
spark.sql(s"desc dwd.$table").show//查看数据结构
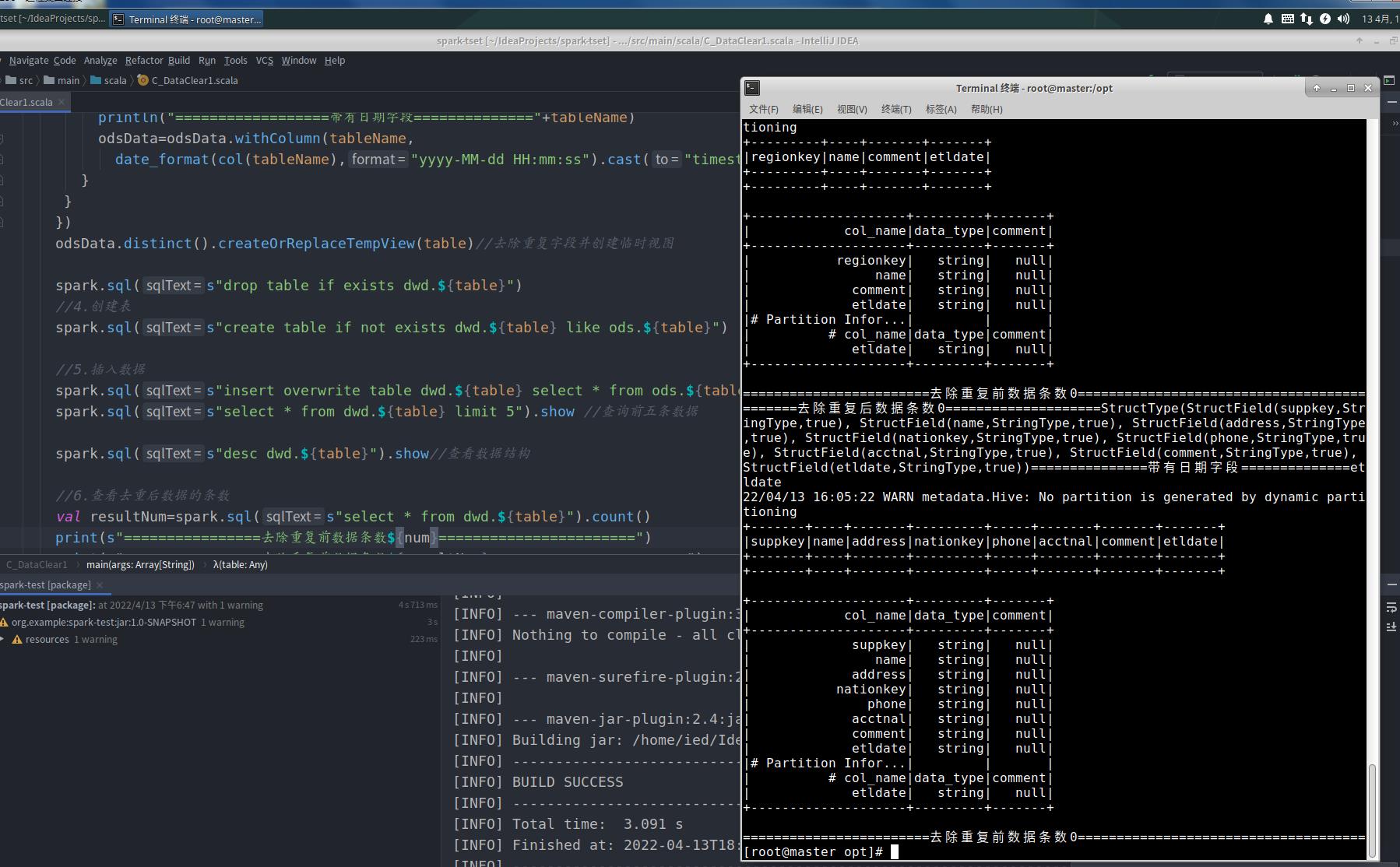
第七步:查看去重启后数据的条数
//6.查看去重后数据的条数
val resultNum=spark.sql(s"select * from dwd.$table").count()
print(s"================去除重复前数据条数$num=======================")
print(s"================去除重复前数据条数$resultNum=======================")
第七步:打包集群
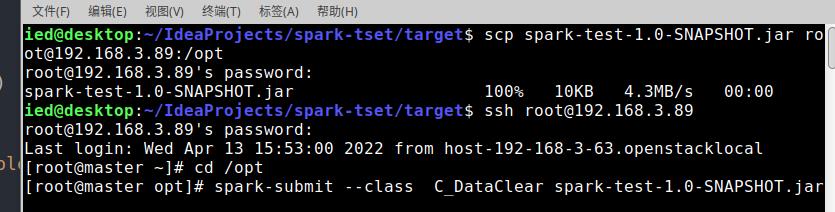
第八步:进入环境并运行
第九步:代码结果

第十步:代码源码
import org.apache.log4j.Level, Logger
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col,date_format
object C_DataClear1
def main(args: Array[String]): Unit =
Logger.getLogger("org").setLevel(Level.ERROR)
//1:输出日志:使用spark默认的log4j配置文件设置日志输出级别 此方法要放在主程序的首行,靠后对输出日志控制不起作用
//2.准备sparkSession对象
val spark=SparkSession
.builder()
.appName("c_dataClear1")
.master("local")
.config("hive.exec.dynamic.partition.mode","nonstrict")//关闭严格模式,否则会有一个静态分区
//hive元数据仓库目录
.config("hive.metastore.warehouse.dir","hdfs://192.168.3.89:9000/user/hive/warehouse")//目录地址
.enableHiveSupport()
.getOrCreate()
//拿出所有的表进行清洗
val tableArray=List("customer","lineitem","nation","orders","part","partsupp","region","supplier")//所有数据表的名称
tableArray.foreach(table =>
//2.删除分区并统计
var odsData=spark.sql(s"select * from ods.$table").drop("part_date")//去除原来字段
val num=odsData.count() //查看数据表结构
println(odsData.schema)//查看数据表的结构
//3.将对于字段的日期改为timestamp类型 格式为:yyyy-MM--dd HH:mm:ss
odsData.columns.foreach(tableName =>
val startIndex=tableName.length -4
val endIndex=tableName.length
if (endIndex >=4)
val tamp=tableName.substring(startIndex,endIndex)//查看每个字段中最后四位是否带有date
if (tamp.toLowerCase.equals("date"))
println("==================带有日期字段=============="+tableName)
odsData=odsData.withColumn(tableName,
date_format(col(tableName),"yyyy-MM-dd HH:mm:ss").cast("timestamp"))
)
odsData.distinct().createOrReplaceTempView(table)//去除重复字段并创建临时视图
spark.sql(s"drop table if exists dwd.$table")
//4.创建表
spark.sql(s"create table if not exists dwd.$table like ods.$table")
//5.插入数据
spark.sql(s"insert overwrite table dwd.$table select * from ods.$table")
spark.sql(s"select * from dwd.$table limit 5").show //查询前五条数据
spark.sql(s"desc dwd.$table").show//查看数据结构
//6.查看去重后数据的条数
val resultNum=spark.sql(s"select * from dwd.$table").count()
print(s"================去除重复前数据条数$num=======================")
print(s"================去除重复前数据条数$resultNum=======================")
)
第二小问:
第一步:创建SparkSession对象
val spark=SparkSession
.builder()
.master("local")
.appName("c1_dataClear")
.config("hive.metastore.warehouse.dir","hdfs://192.168.3.89:9000/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
第二步:输入SQL语句
spark.sql("show databases").show
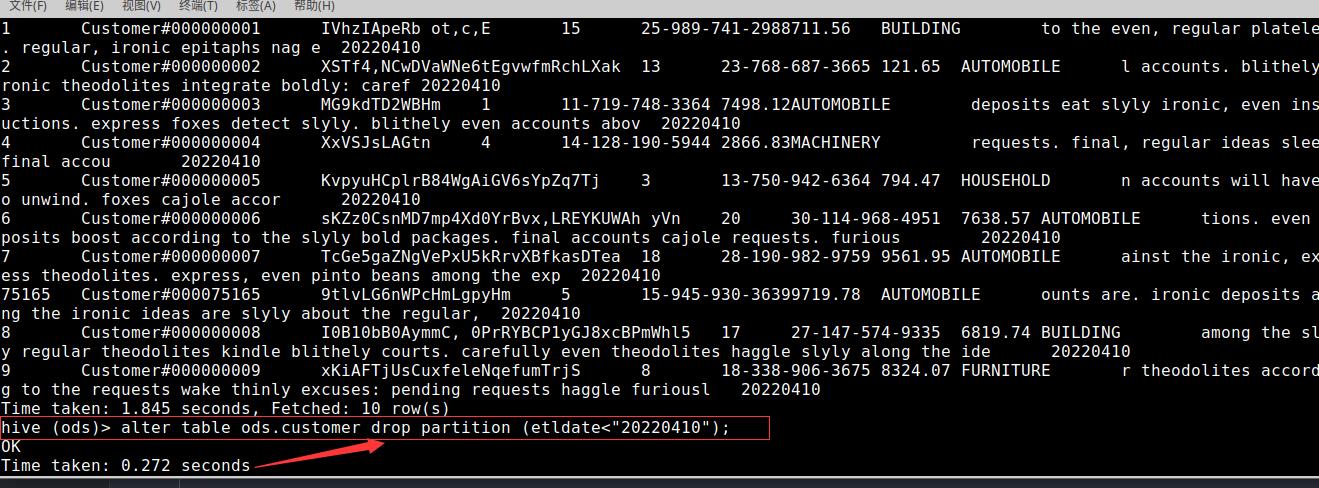
spark.sql("alter table ods.customer drop partition (part_date<'20220410')")//保留三天内的数据
整体代码如下:
import org.apache.spark.sql.SparkSession
object C1_DataClear
def main(args: Array[String]): Unit =
val spark=SparkSession
.builder()
.master("local")
.appName("c1_dataClear")
.config("hive.metastore.warehouse.dir","hdfs://192.168.3.89:9000/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show
spark.sql("alter table ods.customer drop partition (part_date<'20220410')")//保留三天内的数据
第三步:打包集群
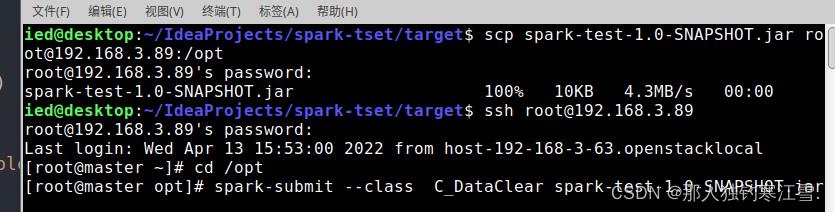
第四步:进入hive集群并且查看前十条数据

第五步:输入(SQL条件)并查看结果
以上是关于Spark框架-离线数据统计的主要内容,如果未能解决你的问题,请参考以下文章