深度上下文编码:DCVC
Posted Dillon2015
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度上下文编码:DCVC相关的知识,希望对你有一定的参考价值。
本文来自NeurIPS 2021论文《Deep Contextual Video Compression》

传统的视频编码方法和最近的基于深度学习的视频编码框架都是采用预测编码的方式,生成预测帧然后和当前帧相减得到残差帧再对残差进行编码。给定预测帧求残差帧是很好的去除时域冗余的方法,但是却不是最优的,因为求残差的操作是一种简单的手工设计的相减的操作,并不能完全去除整个帧的冗余。残差帧的熵大于给定预测帧时当前帧的条件熵 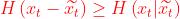 ,其中H(.)是香农熵,
,其中H(.)是香农熵,  是当前帧,
是当前帧,  是预测帧。
是预测帧。
论文提出基于上下文条件的编码,那么什么是条件?如何使用条件?怎么学习条件?严格说,条件是所有能帮助提高当前帧压缩性能的东西。论文使用预测帧作为条件,提供神经网络提取特征来消除预测帧和当前帧间的冗余。论文提出了深度上下文视频压缩DCVC框架,如图1所示。至于怎么学习条件,论文在特征域使用运动估计和运动补偿MEMC来指导模型在哪提取有效的上下文信息。
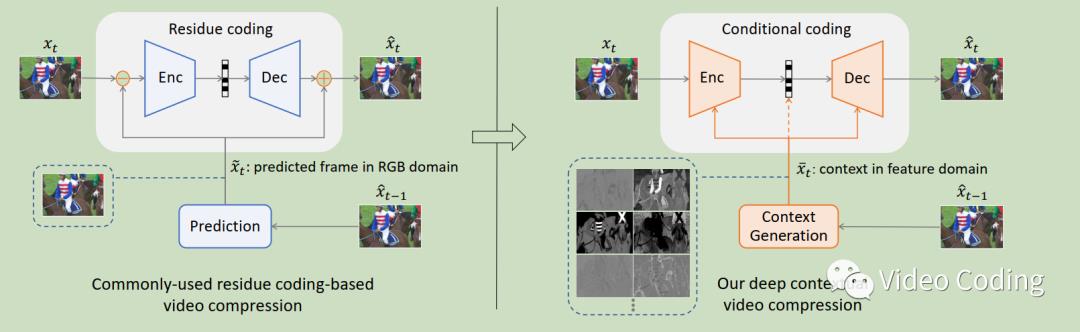
图1 左侧是残差编码框架,右侧是DCVC
DCVC是一个复杂的端到端到端框架,它包括编码、解码和熵编码,此外DCVC还是可扩展的条件编码器,它的条件可以灵活设计。
DCVC框架
传统的视频编码框架,在帧间编码采用残差编码的方式,
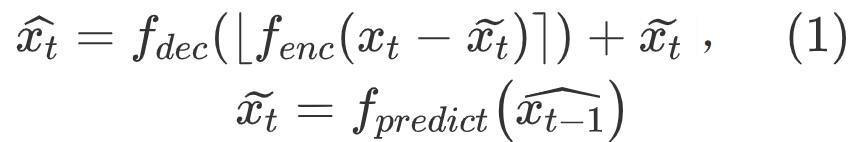
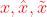 分别表示原始帧、重建帧和预测帧,
分别表示原始帧、重建帧和预测帧,  表示量化操作。
表示量化操作。
论文则使用条件编码的方式,
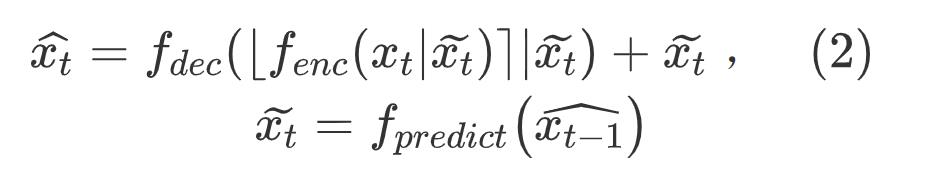
但是上面还是在像素域进行,特征维度很低限制了模型的能力 ,DCVC使用神经网络生成上下文信息,
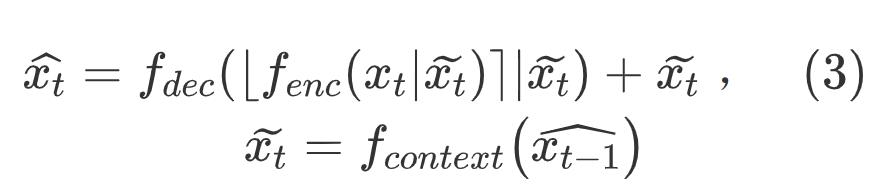
为了获取相关性更高的条件,在特征域中提取高维的上下文,不同维度可以提取不同信息。如图2,右上角是上下文4个通道,可以看见不同通道主要信息不同,例如第3个通道主要包含高频信息,第2和4通道主要包含颜色信息,第2通道主要包含绿色,第4通道是红色。由于丰富的上下文信息,DCVC可以获取更好的重建质量,尤其是对纹理复杂的高频内容而言。图2右下角是和残差编码框架相比的重建误差减少量,无论是前景还是背景的高频区域DCVC都能减少重建误差。

图2
如图1,编码和解码都需要依赖条件上下文 ,在论文框架中网络可以自动学习
,在论文框架中网络可以自动学习  间的关系然后去除冗余,比残差编码通过相减的方式去除冗余更高效。从另一个角度来看,论文框架可以自适应使用上下文,对于包含运动物体的视频当物体运动后,原来被物体遮挡的区域露出来,这些区域在参考帧中找不到合适的预测块,对于残差编码来说得到的残差块会很大此时使用帧内编码会更优,而论文模型可以自适应利用上下文信息去学习帧内编码。
间的关系然后去除冗余,比残差编码通过相减的方式去除冗余更高效。从另一个角度来看,论文框架可以自适应使用上下文,对于包含运动物体的视频当物体运动后,原来被物体遮挡的区域露出来,这些区域在参考帧中找不到合适的预测块,对于残差编码来说得到的残差块会很大此时使用帧内编码会更优,而论文模型可以自适应利用上下文信息去学习帧内编码。
熵模型

图3 熵模型
熵模型要学习出码流的概率分布,
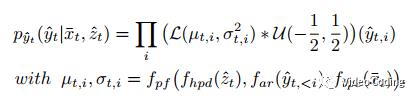
其中hpd模块提取side information,ar模块是自回归模型提取空域信息,tpe模块提取时域信息,Proir fusion模块将这三部分先验信息整合起来。在计算过程中空域先验信息无法并行计算,可以去掉这个模块来加速。
上下文学习
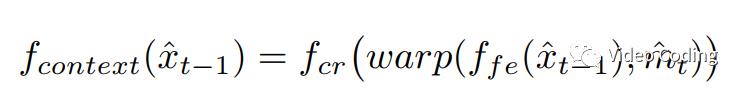
上下文学习过程中借用了MEMC的思想,在特征域使用MEMC。 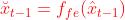 是一个特征提取网络,将参考帧从像素域变为特征域。使用光流估计网络提取运动向量
是一个特征提取网络,将参考帧从像素域变为特征域。使用光流估计网络提取运动向量  ,将运动向量编码再解码,解码后为
,将运动向量编码再解码,解码后为 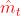 。运动向量指导网络提取上下文信息,
。运动向量指导网络提取上下文信息,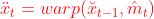 。warp可能会引起空域不连续,所以还需要一个上下文修正网络来计算最终的上下文
。warp可能会引起空域不连续,所以还需要一个上下文修正网络来计算最终的上下文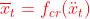 。
。
训练
训练的损失函数为:
L=lambda*D+R
D使用MSE或MS-SSIM计算,R使用真实的和估计的码流概率分布的交叉熵计算。初始学习率是le-4,微调阶段是le-5,batch size=4。训练了4个模型lambda:MSE: 256, 512, 1024, 2048; MS-SSIM: 8, 16, 32, 64
实验
-
训练集:Vimeo-90k
-
测试集:HEVC标准测试集Class B、C、D、E和MCL-JCV及UVG中的1080p视频。
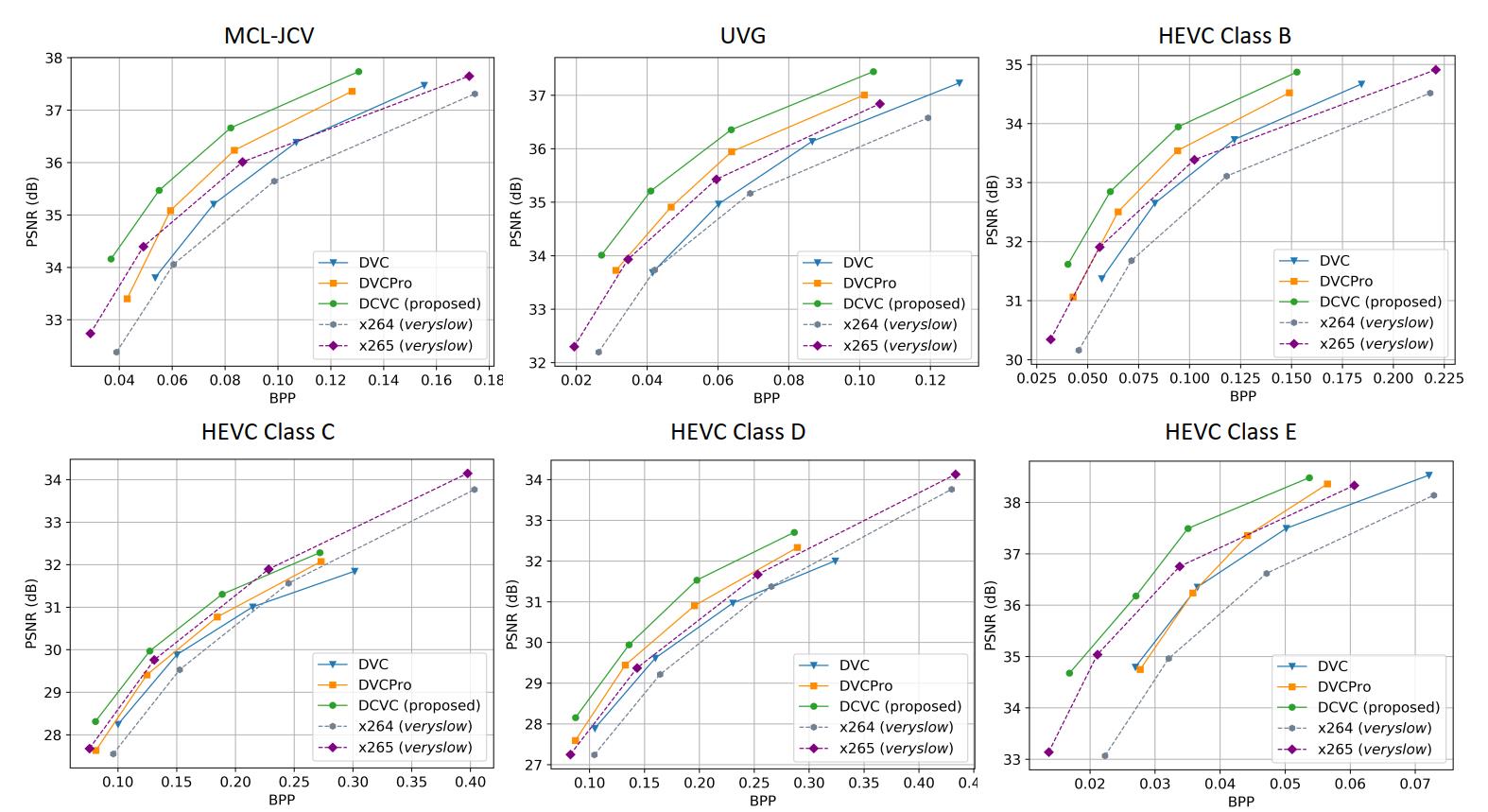
各测试集的RD曲线和BD-Rate结果如下所示:

感兴趣的请关注微信公众号Video Coding

 与50位技术专家面对面
与50位技术专家面对面
 20年技术见证,附赠技术全景图
20年技术见证,附赠技术全景图
以上是关于深度上下文编码:DCVC的主要内容,如果未能解决你的问题,请参考以下文章