5G Edge-XR 中的音频处理
Posted 边缘计算社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5G Edge-XR 中的音频处理相关的知识,希望对你有一定的参考价值。
来源:IBC2021 TECH PAPER
作者:R.G.Oldfield等
论文题目:CLOUD‐BASED AI FOR AUTOMATIC AUDIO PRODUCTION FOR PERSONALISED IMMERSIVE XR EXPERIENCES
内容整理:贾荣立
本文主要介绍了 5G Edge-XR 及其所使用自动声源识别和混音的机器学习方法。利用GPU加速,5G Edge-XR 在云上部署了创新的算法,使得音频内容可以实时自动混合,为观众提供个性化、沉浸式和交互式的体验。
目录
引言
5G Edge-XR 项目概述
基于对象的音频生成
音频对象
音频系统
AI 自动音频生成
音频捕获
音频定位
音频渲染
混音
总结
引言
5G Edge-XR 项目致力于探索如何结合 5G 连接和 GPU 云能力,以提高用户的 XR 体验。该项目特别关注实时体验,观众可以在 AR 头戴设备上自由改变内容视点,实时渲染在云中实时完成,并通过5G网络交付给终端用户。
在传统的 XR 体验中,如果观众的设备没有快速的网络连接速度和强大的GPU能力,以及驱动定制音频和视觉表现的计算能力,就不可能为最终用户提供实时且身临其境的体验。但在 5G Edge-XR 项目中,我们正在探索使用 5G 网络提供高带宽链接发送生活所需 AV 组件,并且基于云 GPU 能力在云上执行计算和渲染,以为网络终端的用户设备提供实时个性化内容。
本文具体结构如下。首先概述5G Edge-XR项目,简单描述其技术特点和架构等,并进一步详细讨论基于对象的音频系统,特别强调 AI 驱动的音源分析、提取和合成引擎,最后对全文进行总结。
5G Edge-XR 项目概述
5G Edge-XR 利用 5G 网络传输加上云上处理,使得用户能够从每个角度观看体育赛事,获得完全身临其境的体验。在不久的将来,用户将在智能手机、平板电脑、AR 和 VR 耳机和电视等设备上获得极好的 XR 体验。
5G Edge-XR项目的体验端到端链如下图1所示。
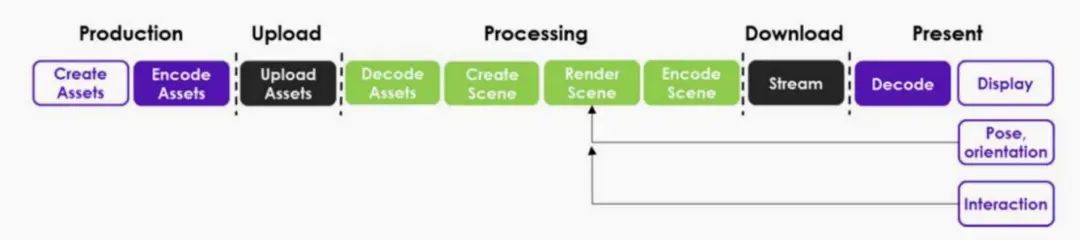
首先是内容生成,视频或者音频资源从摄像机和麦克风实时提取,并被编码和上传到GPU处理系统。处理器将内容呈现到场景中,并使用客户端设备的姿态和方向知识,生成该场景的视图,并呈现视觉和音频流以表示该位置的视图。在这个配置中,客户端设备的要求相对简单——它们需要向GPU处理呈现姿态和方向要求,并能够解码和呈现 AV 信号。通过这样的步骤,客户端就可以自由选择从哪一个视图渲染的场景。
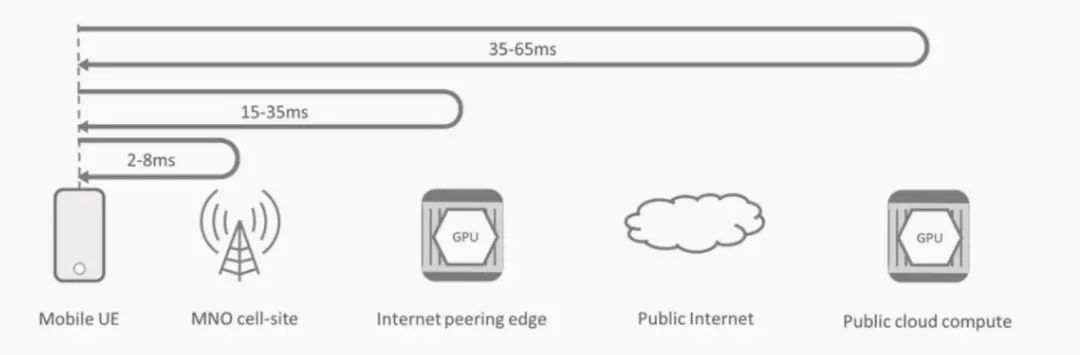
在整个过程中,GPU的逻辑和物理位置影响端到端延迟。基于Internet的云资源通常会增加20-30ms的往返时间。因此,如图2所示,将GPU放置在网络的逻辑边缘,从而产生更好、响应更快的用户体验。
在某些实际场景中,生成的内容可能是体积捕获的近实时渲染。随着技术的发展,捕获的场景大小可能会增加到包括整个剧院舞台、电视演播室、网球场甚至足球或橄榄球场。体积捕获产生大量的数据,从相机和深度传感器,必须分析和编码为点云和纹理传输到GPU集群,逐帧渲染成逼真的全息图。实时的挑战是在渲染的场景中生成一个虚拟摄像机视图,它与场景中放置在相同位置的真实摄像机形成的图像非常相似。要实现这种结构相似性,需要利用 GPU 的复杂计算,包括实时渲染、人工智能和深度学习等技术,以改进编码方法。除了视觉视角的发展,还包括生成与虚拟摄像机的位置和内容相适应的音源背景。
基于对象的音频生成
5G Edge-XR项目和其他类似技术面临的最大挑战之一是,如何在保持良好的广播制作流程的同时,以尽可能多的保存内容的方式捕捉场景。除了捕获音频内容外,还必须从场景中捕获或提取描述内容的大量元数据,以便在用户端实现正确且个性化的渲染。考虑到此,采用基于对象的音频范式能够促进最终个性化音频的生成。
基于对象的范式与传统的基于渠道的方法有着根本的不同,因为音频组件和描述性元数据不是混合目标系统的音频内容,而是作为离散内容通过生产链在用户端进行定制渲染。基于通道的系统使用捕获端可用的音频源,为特定的音频输出格式(立体声,5.1等)混合音频内容。一旦这些内容被混合在一起,就不可能在之后的阶段对其进行分离操作,因为所有的组件都已“融入”到音频内容流中。
基于对象的范式的不同之处在于,单个元素是在捕获端组成的,但通过广播/信号链保持独立,所以在任何时候,所有源元素都可以进行添加、移动或修改等操作,直到最终呈现。这样做有几个优点,一方面是这使得音频渲染与格式无关,另一方面是它允许添加、删除、修改或平移声音等,以实现个性化渲染。
因此,为了实现5G Edge-XR项目的自适应和个性化渲染,基于对象的范式至关重要。基于对象的系统的基础是“音频对象”,我们在此将其定义为场景中的离散声音,通常呈现在空间中的特定点,以及构成沉浸式背景声音的环境音。
音频对象
在任何音频场景中,都会有许多离散的声源,它们可以被描述为来自特定位置,并具有特定的音频特征。这样的“点”类型源可以被定义为音频对象。
“音频对象”这一术语也用于描述任何可以添加或删除声音场景/合成的音频内容。例如网球比赛直播中网球中拍子击打的声音,裁判、解说员的麦克风信号等。
音频对象通常是离散的音频源,伴随着描述其位置、类型、持续时间和其他属性/信号统计数据的元数据。
以这种方式描述音频场景和保持内容分离直到终端,意味着终端用户可以完全控制他们的音频混合和重新定位。
音频系统
在过去,由于带宽的限制,云上的实时音频处理一直很困难。虽然可以通过压缩音频技术减少对于带宽的需求,但是许多压缩技术会降低音频质量。5G网络极大地提高了可用带宽的数量,从而使将多通道未压缩音频传输到云端成为可能。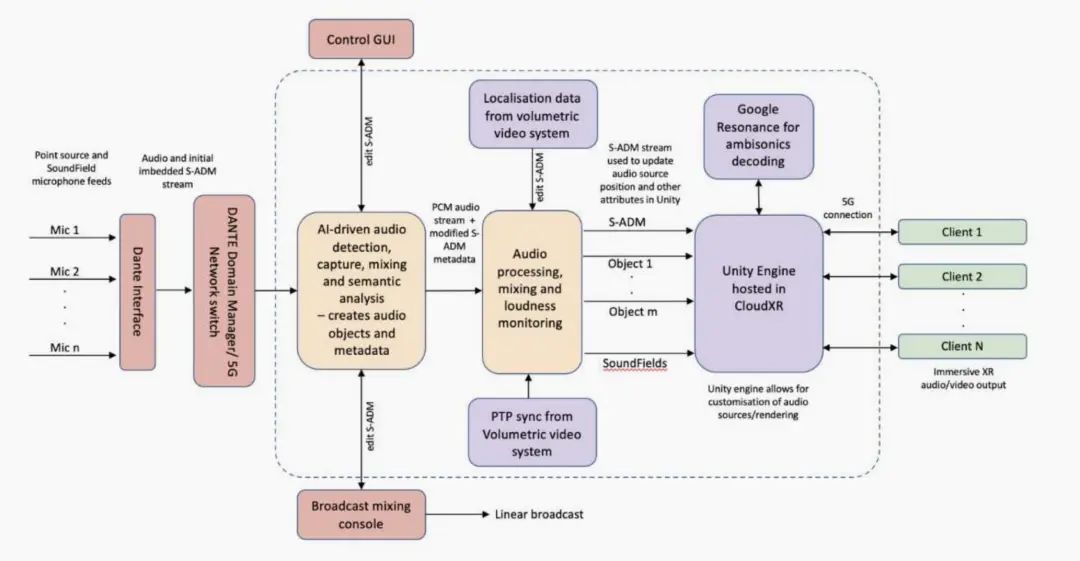
5G Edge-XR 音频系统架构如 图3 所示。在活动中提取原始的麦克风音源,并通过 DANTE 网络上传到云。通过 Dante 虚拟声卡,这些音源输入到音频事件提取器和语义分析引擎中。元数据流和音频混合可以通过远程 GUI 和广播混合控制台进行操作。此外,我们还对一些音频流进行语义分析,以生成更多的元数据,这些元数据可以在稍后的信号传输中用于提高最终用户体验。
AI 自动音频生成
在传统的音频传输中,音频混合将在传输前提前完成。在5G Edge-XR项目中,Aldriven混合引擎已经从本地移植到云端。在云中运行音频分析、处理和混合的好处之一是,GPU加速可以大大提高处理器能力,这增加了音频分析的功能,并能够实现更复杂的处理任务,如实时音频对象提取、本地化和传入流的语义分析。
音频捕获
我们的音频捕获和提取方法的概述如 图4 所示。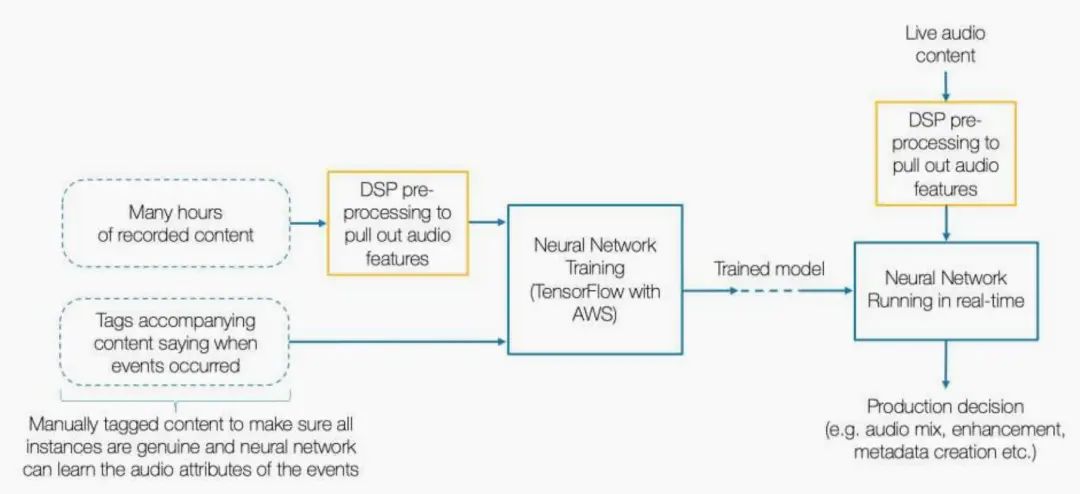
音频模板是基于当前背景下的显著声源的感知模型推导出来的,而基于来自相同背景的内容训练的神经网络能够非常精确地实时检测和分类感兴趣的音频事件。如果几个麦克风捕获了相同的音频事件,则使用一种高效的优化算法对信号进行三角化,创建位置元数据,以帮助自动促进空间和沉浸式混合。
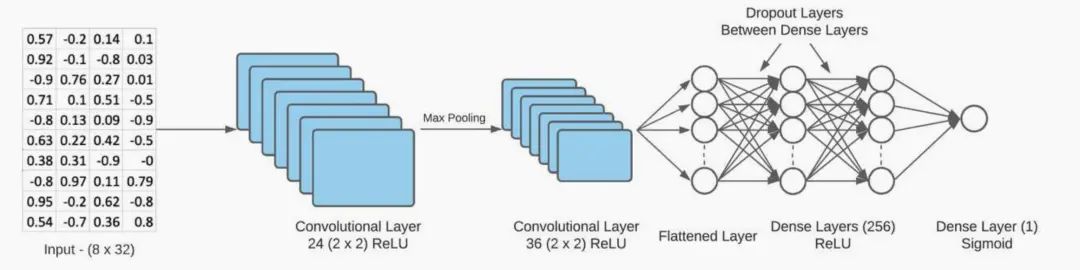
图5 展示了用于检测高瞬态音频事件的卷积神经网络模型,例如拳击比赛中的出拳。
在内容分析和在提取过程中,会自动创建可以用于混合决策的内容标志或触发预录的内容来增强广播音频。
音频定位
当创建音频对象时,很重要的一点就是要对音源进行定位,这意味着,当观看者在内容上导航他们的视觉视角时,可以正确地移动声源,使其与视觉源的位置相匹配。
为了方便起见,采用了三角测量方法。三角测量方法因捕获装置的不同而不同,但通常是利用不同麦克风对信号之间的到达时间差 (TDOA) 来实现的。知道这些麦克风的位置,可以将源定位在两个麦克风之间的双曲线路径上。如果在其他麦克风中接收到相同的信号源,就会出现额外的双曲线,而产生的曲线之间的重叠使信号源的准确定位/三角定位成为可能。由于实时事件的高背景噪声,使用传统算法(如互相关联)来确定TDOAs会出现一些问题,因此我们使用我们的Al来提取每个麦克风中源检测的时间戳来确定TDOAs,以使得音源定位更加的准确。
音频渲染
混音
当渲染端需要多种个性化混合时,系统架构中必须有一个自动混合阶段。自动混合可以根据音频内容,外部位置/跟踪数据和任何个人观看数据,编译沉浸式和个性化的混合。
在场景中添加和删除各种对象/源时,需要自动管理各种组件的相对平衡,并正确监控和缩放输出的响度。在信号链的输出阶段,根据EBU R128和ITU BS.1770-3对信号响度进行测量和操作。该处理的参数是可编辑的,因此可以实现不同平台的不同响度标准。
总结
本文重点介绍了5G Edge-XR 及其所使用自动声源识别和混音的方法,描述了如何通过在云中使用 Al 来实时创建和渲染音频对象。基于对象的系统允许对沉浸式内容进行个性化处理,以匹配在云中执行的内容的可视化渲染,从而提高用户的使用体验。
最后附上演讲视频:
感谢阅读,欢迎扩散传播!感谢!
边缘计算社区:促进边缘计算领域知识传播,中立,客观,如果您关注边缘计算、5G、物联网、云原生等领域请关注我们。
 《新程序员》:云原生和全面数字化实践
《新程序员》:云原生和全面数字化实践
 50位技术专家共同创作,文字、视频、音频交互阅读
50位技术专家共同创作,文字、视频、音频交互阅读
以上是关于5G Edge-XR 中的音频处理的主要内容,如果未能解决你的问题,请参考以下文章
HMS Core音频编辑服务音源分离与空间音频渲染,助力快速进入3D音频的世界