RDMA技术浅析
Posted yuanyun_elber
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RDMA技术浅析相关的知识,希望对你有一定的参考价值。
本章主要探讨RDMA软件相关的部分。
一、名词解释
首先解释一下几个名词:
- rdma-core
指开源RDMA用户态软件协议栈,包含用户态框架、各厂商用户态驱动、API帮助手册以及开发自测试工具等。
rdma-core在github上维护,我们的用户态Verbs API实际上就是它实现的。https://github.com/linux-rdma/rdma-core
代码目录结构如下:
其中比较重要的几个目录是:
- libibverbs
以ibv为前缀,这里的ib并不代表infiniband协议,Verbs API支持IB/iWARP/RoCE三大RDMA协议,通过统一接口,让同一份RDMA程序程序可以无视底层的硬件和链路差异运行在不同的环境中。之所以有这个前缀,还是因为IB比较早。
Verbs API是一组用于使用RDMA服务的最基本的软件接口,也就是说业界的RDMA应用,要么直接基于这组API编写,要么基于在Verbs API上又封装了一层接口的各种中间件编写。
Verbs API向用户提供了有关RDMA的一切功能,典型的包括:注册MR、创建QP、Post Send、Poll CQ等等。
- librdmacm
以rdma_为前缀,主要分为两个功能:
CMA(Connection Management Abstraction) (cma.c)
在Socket和Verbs API基础上实现的,用于CM建链并交换信息的一组接口。CM建链是在Socket基础上封装为QP实现,从用户的角度来看,是在通过QP交换之后数据交换所需要的QPN,Key等信息。
比如:
rdma_listen()用于监听链路上的CM建链请求。
rdma_connect()用于确认CM连接。
CM VERBS (rdma_verbs.h)
RDMA_CM也可以用于数据交换,相当于在verbs API上又封装了一套数据交换接口。
比如:
rdma_post_send = ibv_post_send(qp,wr.opcode=IBV_WR_SEND,bad_wr)
rdma_post_read = ibv_post_send(qp,wr.opcode=IBV_WR_RDMA_READ ,bad_wr)
rdma_post_write = ibv_post_send(qp,wr.opcode=IBV_WR_RDMA_WRITE,bad_wr) - provider
各个硬件厂商的驱动代码都在这里
如果要rdma编程,实现一个QP应用,那么关注前两个文件夹就可以了,作为我们硬件厂商来说,要关注provider这个目录下的驱动是怎么实现的。
下面我们会分别介绍这两个方面。
2.kernel RDMA subsystem
指开源的Linux内核中的RDMA子系统,包含RDMA内核框架及各厂商的驱动。
RDMA子系统跟随Linux维护,是内核的的一部分。一方面提供内核态的Verbs API,一方面负责对接用户态的接口。
3.OFED
全称为OpenFabrics Enterprise Distribution,是一个开源软件包集合,其中包含内核框架和驱动、用户框架和驱动、以及各种中间件、测试工具和API文档。
开源OFED由OFA组织负责开发、发布和维护,它会定期从rdma-core和内核的RDMA子系统取软件版本,并对各商用OS发行版进行适配。除了协议栈和驱动外,还包含了perftest等测试工具。
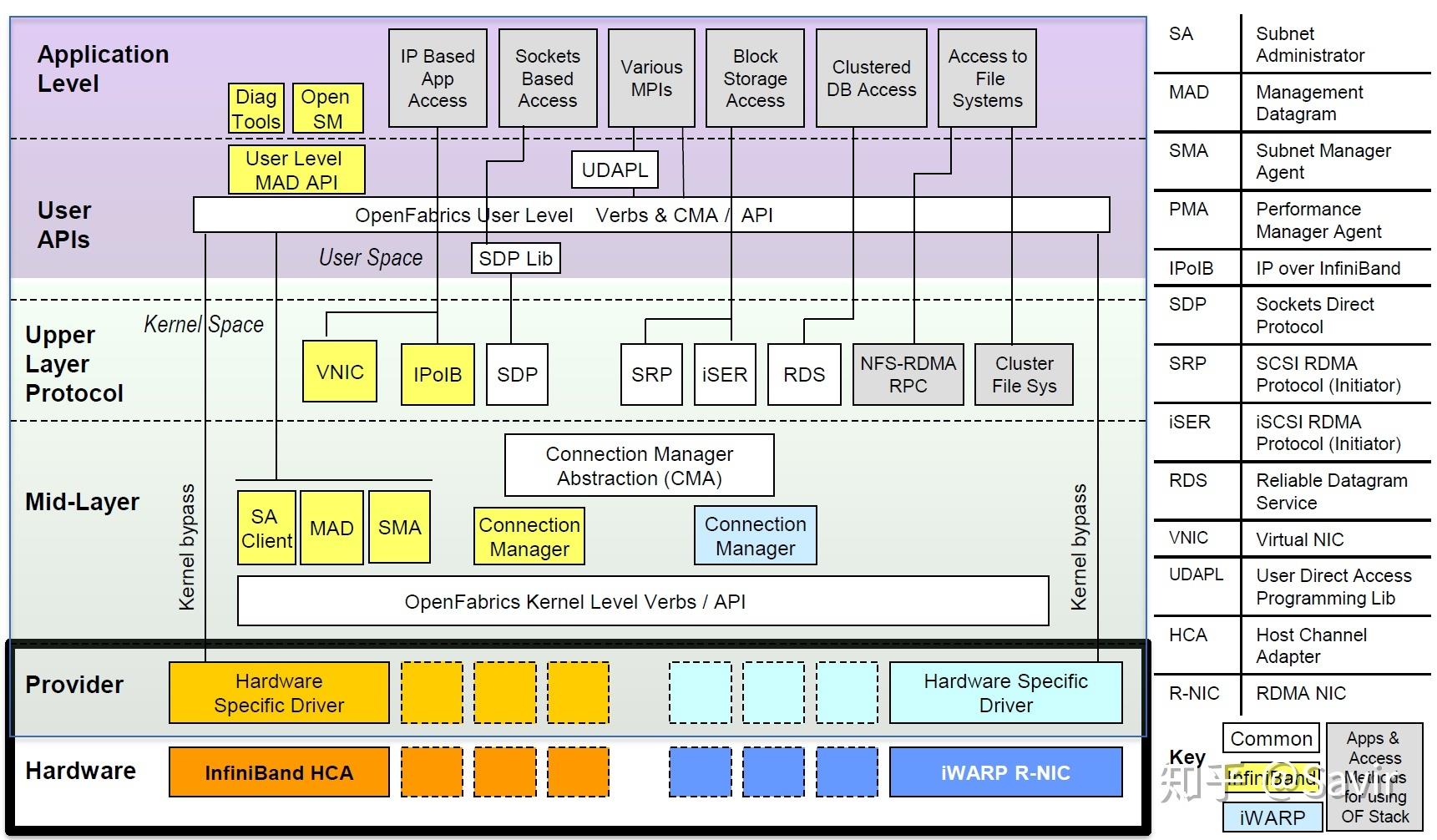
二、 RDMA编程
2.1 基本的通信编程
可以使用上文提到的ibverbs接口或者cma接口都可以
也可以在代码路径的man目录下查看api的说明。
下面附上一个简单的RDMA程序的大致接口调用流程,Client端的程序会发送一个SEND请求给Server端的程序,图中的接口上文中都有简单介绍。
需要注意的是图中的建链过程是为了交换对端的GID(相当于TCP中的IP),QPN(QP序号)等信息,可以通过传统的IBV接口实现,也可以通过本文中介绍的CMA接口实现。
图中特意列出了多次modify QP的流程,一方面是把建链之后交互得到的信息存入QPC中(即QP间建立连接的过程),另一方面是为了(转换状态)使QP处于具备收/发能力状态才能进行下一步的数据交互。
(假设A节点的某个QP要跟B节点的某个QP交换信息,除了要知道B节点的QP序号——QPN之外,还需要GID--(相当于TCP中的IP),在传统TCP-IP协议栈中,使用了家喻户晓的IP地址来标识网络层的每个节点。而IB协议中的这个标识被称为GID(Global Identifier,全局ID)
如果是用cma编程,从函数名上看,更像是socket编程了:
static int run_server(void)
struct rdma_cm_id *listen_id;
int i, ret;
printf("cmatose: starting server\\n");
ret = rdma_create_id(test.channel, &listen_id, &test, hints.ai_port_space);
if (ret)
perror("cmatose: listen request failed");
return ret;
ret = get_rdma_addr(src_addr, dst_addr, port, &hints, &test.rai);
if (ret)
printf("cmatose: getrdmaaddr error: %s\\n", gai_strerror(ret));
goto out;
ret = rdma_bind_addr(listen_id, test.rai->ai_src_addr);
if (ret)
perror("cmatose: bind address failed");
goto out;
ret = rdma_listen(listen_id, 0);
if (ret)
perror("cmatose: failure trying to listen");
goto out;
ret = connect_events();
if (ret)
goto out;2.2 基于消息
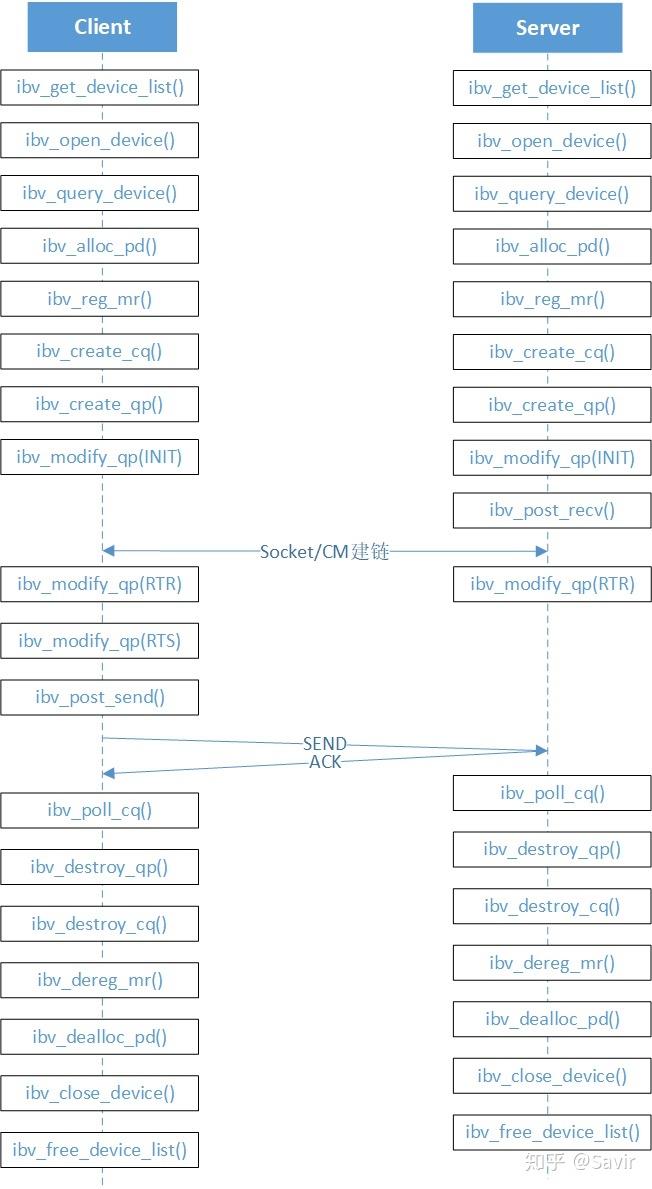
和传统TCP/IP的socket编程还是有区别的,区别在于rdma基于消息,而传统TCP/IP基于流。
从transport modes可知RDMA通信主要有两种方式,分别是对应send/receive的双边模式和对应RDMA write/read的单边模式。
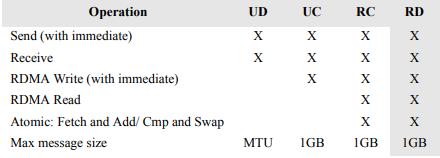
何为双边模式?因为完成一次通信过程需要两端CPU的参与,并且收端需要提前显式的下发WQE。下图是一次SEND-RECV操作的过程示意图。
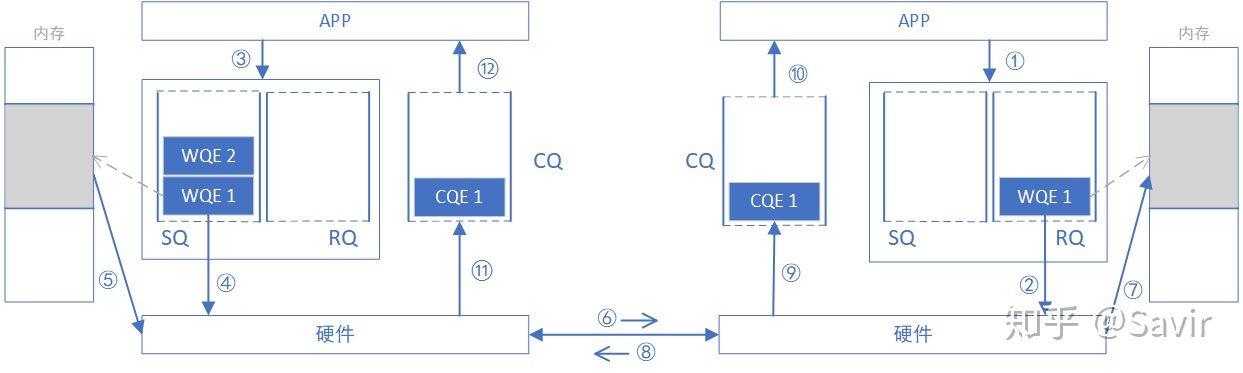
WQE(work queue element),其实类似于传统网卡驱动中的描述符,最终指向内存中的一块buffer。
对于双边操作为例,主机A向主机B(下面简称A、B)发送数据的流程如下:
1. 首先,A和B都要创建并初始化好各自的QP,CQ
2. A和B分别向自己的WQ中注册WQE,对于A,WQ=SQ,WQE描述指向一个等到被发送的数据;对于B,WQ=RQ,WQE描述指向一块用于存储数据的Buffer。
3. A的RNIC异步调度轮到A的WQE,解析到这是一个SEND消息,从Buffer中直接向B发出数据。数据流到达B的RNIC后,B的WQE被消耗,并把数据直接存储到WQE指向的存储位置。
4. AB通信完成后,A的CQ中会产生一个完成消息CQE表示发送完成。与此同时,B的CQ中也会产生一个完成消息表示接收完成。每个WQ中WQE的处理完成都会产生一个CQE。
双边操作与传统网络的底层Buffer Pool类似,收发双方的参与过程并无差别,区别在零拷贝、Kernel Bypass,实际上对于RDMA,这是一种复杂的消息传输模式,多用于传输短的控制消息。
单边操作,顾名思义,只需要一端的CPU操作,另一端CPU是无感的,(除非是个IRDMA_WRITE_WITH_IMM,带立即数的操作),如下图是write操作,read操作类似。
本端在准备阶段通过数据交互,获取了对端某一片可用的内存的地址和“钥匙”,相当于获得了这片远端内存的读写权限。
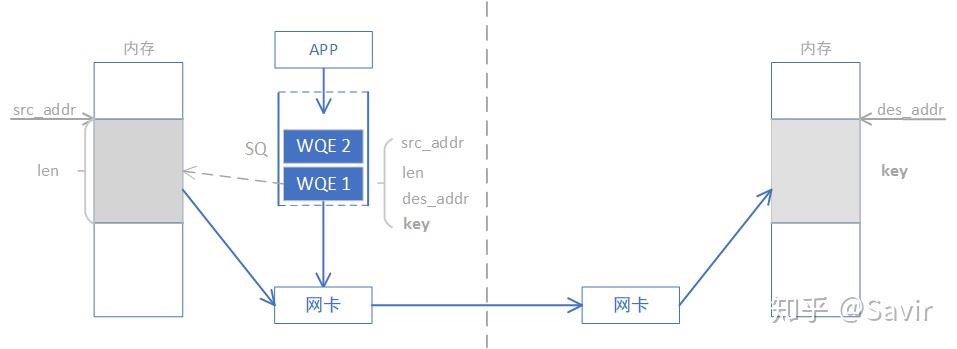
WRITE/READ操作中的目的地址和钥匙是如何获取的呢?通常可以通过我们刚刚讲过的SEND-RECV操作来完成。
2.3 具体的例子
我们可以看一下如下这个例子,看完这个例子,基本就对rdma编程常用的接口有所了解了。
InfiniBand, Verbs, RDMA | The Geek in the Corner
在这个例子中,需要把一个文件发送到对端,其流程如下,前两次双方的双向通信,目的是为了最后的单向通信服务的
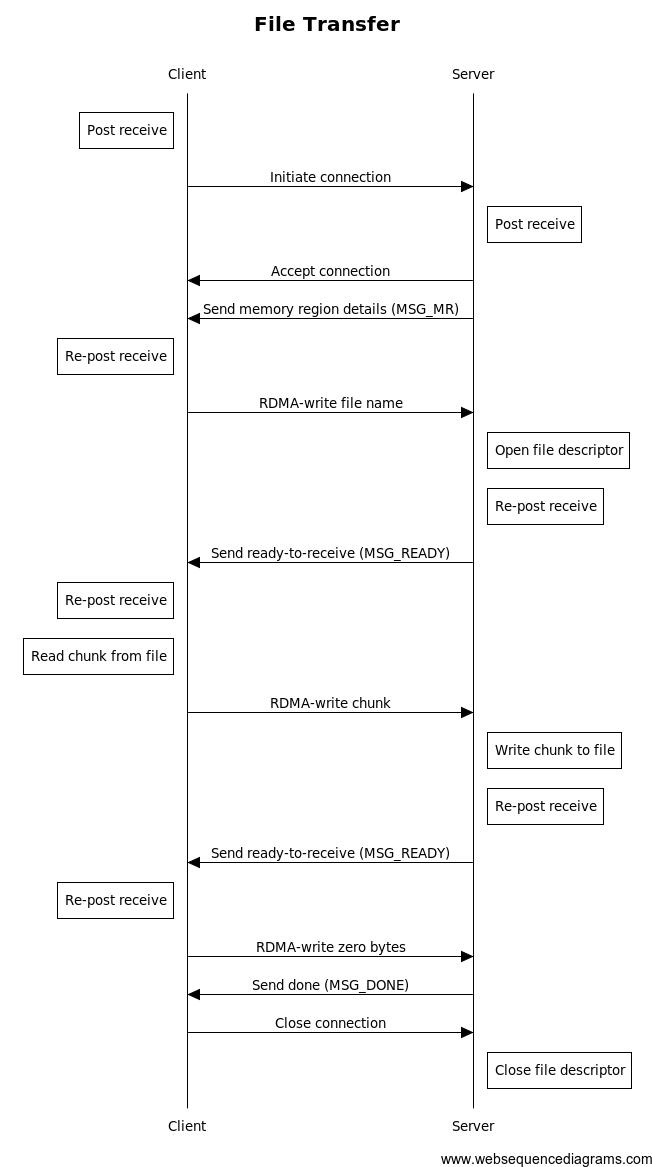
该例子封装了收发消息的函数,本质上收发消息就是上文所述的send、recieve,我们一直说rdma是基于消息的,而tcp是基于流的,就是这个意思。
void send_message(struct connection *conn)
struct ibv_send_wr wr, *bad_wr = NULL;
struct ibv_sge sge;
memset(&wr, 0, sizeof(wr));
wr.wr_id = (uintptr_t)conn;
wr.opcode = IBV_WR_SEND; //注意这个opcode,这个opcode就是传输模式
wr.sg_list = &sge;
wr.num_sge = 1;
wr.send_flags = IBV_SEND_SIGNALED;
sge.addr = (uintptr_t)conn->send_msg;
sge.length = sizeof(struct message);
sge.lkey = conn->send_mr->lkey;
while (!conn->connected);
TEST_NZ(ibv_post_send(conn->qp, &wr, &bad_wr));
void on_completion(struct ibv_wc *wc) //CQ收到消息说明收发队列上有数据需要处理,cpu介入,调用此回调函数
struct connection *conn = (struct connection *)(uintptr_t)wc->wr_id;
//可以看出这个函数是深度定制的,根据状态机、消息的opcode、typde等等有着不同处理loop
if (wc->status != IBV_WC_SUCCESS)
die("on_completion: status is not IBV_WC_SUCCESS.");
if (wc->opcode & IBV_WC_RECV)
conn->recv_state++;
if (conn->recv_msg->type == MSG_MR) //MSG_MR是此程序定制的消息类型,顾名思义就是为了传输内存信息的
memcpy(&conn->peer_mr, &conn->recv_msg->data.mr, sizeof(conn->peer_mr));
post_receives(conn); /* only rearm for MSG_MR */
if (conn->send_state == SS_INIT) /* received peer's MR before sending ours, so send ours back */
send_mr(conn);
else
conn->send_state++;
printf("send completed successfully.\\n");
if (conn->send_state == SS_MR_SENT && conn->recv_state == RS_MR_RECV)
struct ibv_send_wr wr, *bad_wr = NULL;
struct ibv_sge sge;
if (s_mode == M_WRITE)
printf("received MSG_MR. writing message to remote memory...\\n");
else
printf("received MSG_MR. reading message from remote memory...\\n");
memset(&wr, 0, sizeof(wr));
wr.wr_id = (uintptr_t)conn;
wr.opcode = (s_mode == M_WRITE) ? IBV_WR_RDMA_WRITE : IBV_WR_RDMA_READ;
wr.sg_list = &sge;
wr.num_sge = 1;
wr.send_flags = IBV_SEND_SIGNALED;
wr.wr.rdma.remote_addr = (uintptr_t)conn->peer_mr.addr;
wr.wr.rdma.rkey = conn->peer_mr.rkey;
sge.addr = (uintptr_t)conn->rdma_local_region;
sge.length = RDMA_BUFFER_SIZE;
sge.lkey = conn->rdma_local_mr->lkey;
TEST_NZ(ibv_post_send(conn->qp, &wr, &bad_wr)); //这个分支就是write、read的post了,后面不需要cpu参与了
conn->send_msg->type = MSG_DONE;
send_message(conn);
else if (conn->send_state == SS_DONE_SENT && conn->recv_state == RS_DONE_RECV)
printf("remote buffer: %s\\n", get_peer_message_region(conn));
rdma_disconnect(conn->id);
三、 RDMA和硬件接口
其实作为网卡芯片厂商,我们更为关注的还是provider文件夹下面的设备驱动部分。也就是rdma core如何把wqe下发到网卡,让网卡执行dma操作的。
以发送为例,数据面是下面这个函数
ibv_post_send(qp, wr)
QP下发一个Send WR,参数wr是一个结构体,包含了WR的所有信息。包括wr_id、sge数量、操作码(SEND/WRITE/READ等以及更细分的类型)。
WR经由驱动进一步处理后,会转化成WQE下发给硬件。流程图如下:
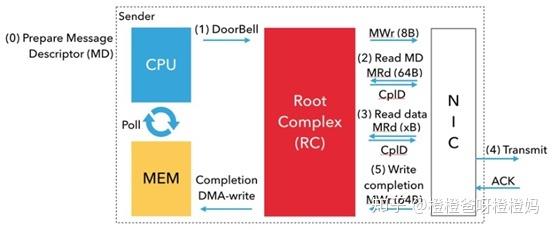
以mlx5为例,mlx5发送的回调函数如下:
static inline int _mlx5_post_send(struct ibv_qp *ibqp, struct ibv_send_wr *wr,struct ibv_send_wr **bad_wr)
...
switch (ibqp->qp_type) //根据服务类型qp_type进行不同的处理,WR的结构会根据服务类型和操作类型有所差异
case IBV_QPT_XRC_SEND:
if (unlikely(wr->opcode != IBV_WR_BIND_MW &&
wr->opcode != IBV_WR_LOCAL_INV))
xrc = seg;
xrc->xrc_srqn = htobe32(wr->qp_type.xrc.remote_srqn);
seg += sizeof(*xrc);
size += sizeof(*xrc) / 16;
/* fall through */
case IBV_QPT_RC:
switch (wr->opcode)
case IBV_WR_RDMA_READ: //根据opcode进行不同处理
case IBV_WR_RDMA_WRITE:
case IBV_WR_RDMA_WRITE_WITH_IMM:
set_raddr_seg(seg, wr->wr.rdma.remote_addr, //比如RC服务的WRITE和READ操作的WR会包含远端内存地址和R_Key
case IBV_QPT_XRC_SEND :
wr->wr.rdma.rkey);
seg += sizeof(struct mlx5_wqe_raddr_seg);
size += sizeof(struct mlx5_wqe_raddr_seg) / 16;
break;
....
if (wr->send_flags & IBV_SEND_INLINE && wr->num_sge) //根据wr转化成wqe,准备下发硬件
int uninitialized_var(sz);
err = set_data_inl_seg(qp, wr, seg, &sz, &sg_copy_ptr);
if (unlikely(err))
*bad_wr = wr;
mlx5_dbg(fp, MLX5_DBG_QP_SEND,
"inline layout failed, err %d\\n", err);
goto out;
inl = 1;
size += sz;
else
dpseg = seg;
for (i = sg_copy_ptr.index; i < wr->num_sge; ++i)
if (unlikely(dpseg == qend))
seg = mlx5_get_send_wqe(qp, 0);
dpseg = seg;
if (likely(wr->sg_list[i].length))
if (unlikely(wr->opcode ==
IBV_WR_ATOMIC_CMP_AND_SWP ||
wr->opcode ==
IBV_WR_ATOMIC_FETCH_AND_ADD))
set_data_ptr_seg_atomic(dpseg, wr->sg_list + i);
else
if (unlikely(wr->opcode == IBV_WR_TSO))
if (max_tso < wr->sg_list[i].length)
err = EINVAL;
*bad_wr = wr;
goto out;
max_tso -= wr->sg_list[i].length;
set_data_ptr_seg(dpseg, wr->sg_list + i,
sg_copy_ptr.offset);
sg_copy_ptr.offset = 0;
++dpseg;
size += sizeof(struct mlx5_wqe_data_seg) / 16;
...
post_send_db(qp, bf, nreq, inl, size, ctrl); //doorbell通知硬件步骤0:用户首先将MD排队到TxQ中。然后,网络驱动程序准备设备特定的MD,该MD包含NIC的报头和指向有效负载的指针。
步骤1:使用8字节的原子写入内存映射位置,CPU(网络驱动程序)通知NIC消息已准备好发送。这叫做按门铃。RC使用MWr PCIe事务执行门铃。我们这里要介绍一下门铃机制, 在大多数HCA中,这是映射到进程地址空间的设备内存地址。我们在这份文件中称这个地址为“门铃”。
步骤2:门铃响后,网卡通过DMA读取MD。MRd PCIe事务执行DMA读取。
步骤3:NIC将使用另一个DMA读取(另一个MRd TLP)从注册的内存区域获取有效负载。请注意,在NIC可以执行DMA读取之前,必须将虚拟地址转换为物理地址。
下面两步,rdma write/read是不需要的。
步骤4:一旦网卡接收到有效载荷,它就会通过网络传输读取的数据。成功传输后,目标NIC接收确认(ACK)。
步骤5:接收到ACK后,NIC将DMA写入(使用MWr TLP)一个完成队列条目(CQE;动词中称为cookie;Mellanox InfiniBand中为64字节)到与TxQ关联的CQ。然后CPU将轮询此完成情况以取得进展。
接收和发送方向相反,不再赘述。
以上是关于RDMA技术浅析的主要内容,如果未能解决你的问题,请参考以下文章