利用机器学习的排名模型,提升你在英雄联盟的排名!
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用机器学习的排名模型,提升你在英雄联盟的排名!相关的知识,希望对你有一定的参考价值。

作者 | Felicia Kuan 译者 | 弯月
出品 | CSDN
英雄联盟是一款多人在线游戏,拥有百万人休闲与专业玩家。这是一款 5 对 5 展开激烈角逐的游戏,玩家为了夺取对方的基地而战。很显然,如果你选择强势的英雄,那么在同等水平玩家的比赛中获胜的可能性就更大。
如果你希望提升游戏中竞争激烈的排名,那么想不想试试看利用机器学习分析,在下一场游戏中根据统计结果做决定?想不想试试看一边享受自己喜欢的游戏,一边学习科技行业流行的机器学习技术?
在我们看来,机器学习是任何人都可以使用的工具,而不仅仅面向擅长数学及掌握了编程技术的数据科学家。这些知识都不是必需的,你只需要了解排名模型的概念即可。
排名是机器学习的一种应用,它根据参数(比如你在英雄联盟游戏中的输赢)对数据进行排序。我们可以根据数据的排序,预测新数据产生的结果。
换句话说,如果给出一组提莫出场的比赛,并根据输赢对比赛进行排名,那么由于每一场比赛都有提莫,该模型就会认为提莫这个英雄是否出场和比赛输赢之间的关联性很低。这意味着提莫是否出场,对你的输赢几乎没有影响,因为他与赢得比赛之间的关系不大。因此,如果你要求模型预测自己能否赢得此次有提莫出场的比赛,它就会要求你提供更多信息,并且会做出错误的预测。

目标
本文无意抹黑提莫,我们希望通过正确引导你对英雄联盟的兴趣,从而引发你对机器学习的兴趣。如果我们能教会游戏玩家机器学习的概念(比如排名模型是什么),你就能掌握数据驱动分析的力量,并在项目中找到其他应用AI的方法。
因此,在本文中,我们希望通过机器学习排名模型解决下列问题:
哪些英雄能增加我赢得白金或钻石比赛的胜率?换句话说,就我的水平而言,选择哪些英雄能够帮助我提升排名?
哪些因素对于比赛胜负的影响最大?
在十分钟内,使用某个英雄,赢得一场钻石比赛并获得相应金币的概率有多大?
注意:我的数据集采用了较高水平的游戏,因为我希望读者能认真阅读本文。如果你想了解如何使用拳头游戏 API,并生成适合自己水平的数据集以获得更准确的分析结果,可以查看我的 GitHub。
(https://github.com/witchfelicia/LoL-dataset)

数据集
大多数数据科学家都知道,优秀的模型源自强力且适合的数据集。为了撰写这篇指南,我们费了九牛二虎之力解析了拳头游戏 API 返回的结果,并谨慎地选择了一组白金与钻石级别的游戏数据,其中包含 5000 多行 14 列的数据。
关于如何通过公开的英雄联盟排位赛数据,生成这套数据集的详细信息,请参见我的 GitHub。
总的来看,这套数据集包含 5000 多行,每一行数据包含一位玩家在白金或钻石级别参加排位赛的信息。一共 14 列,包括玩家的 KDA、pick和ban的英雄、是否有队友挂机、10分钟内赢得的金币、游戏结束时的金币,以及比赛的胜负。
在收集到这些数据以后,下一步我们需要准备训练模型的数据。

数据清理
下面,我们来一场数据“大清洗”。
数据清理是机器学习流程中的一个步骤,目的是降低数据中的噪声,为训练机器学习模型准备一套整洁、精确的数据。也就是说,大多数时候,原始数据都会包含一些空值、不相干的行或列,如果放任不管,那么模型在学习这些数据产生的结果并分析走向趋势时,就会倍感困惑。
对于数据清理以及下一步(特征工程)的工作来说,最大的难题是没有特定的公式或顺序指导我们完成这项工作,因此许多新手都会被劝退。就像英雄联盟一样,学习曲线非常陡峭,但是相信自己一定能行!
在学习机器学习的各个步骤时,请不断思考这样一个问题:“我们为什么要执行这个操作?”,这样相信很快你就能学会。
下面,介绍一下我们利用拳头游戏 API 收集数据的过程,我们随机选择了一个白金或钻石级别的玩家 A 的数据,并生成他们最近 20 场排位赛的数据。然而,如果A的某一名队友B也是我们的收集对象的25位玩家之一,那么包含玩家A和B的队友及对手的数据就会被收集两次。
重复的数据会导致预测结果出现偏差,因为会给模型留下一种印象:某个事件的发生频率更高。想象一下,如果我们重复记录亚索一招必杀技赢得的比赛,那么模型会如何预测亚索玩家的胜率。
我们可以删除重复的数据,如果玩家 A 和 B 的比赛重叠,那么我们就可以删除相同的数据,即同一批玩家出现在同一场比赛中,而且是同一伙人赢得了胜利。
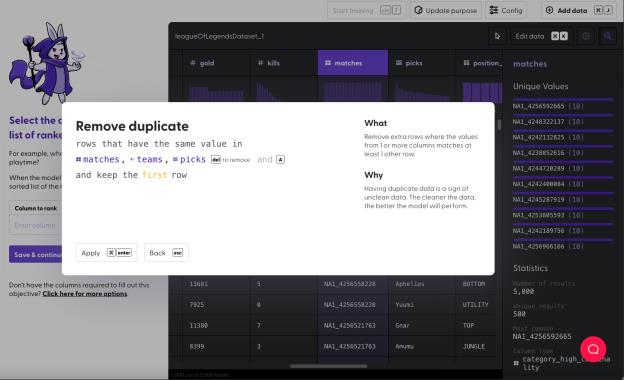
有时,我们并不确定哪些需要清理,遇到这种情况,我们可以看一看每一列,查找包含空值、非法值或错误值的数据,并将它们过滤出去。
举个例子,比赛中有 5 个位置,但是特征“position”(位置)中却包含第 6 个值:Invalid(无效),这是因为拳头游戏 API 无法判断某位玩家打的是哪个位置。
如果我们保留“position”列中的“Invalid”,那么模型就会以为玩家可以选择“Invalid”这个位置。我们当然不希望模型在不准确的值上训练,因为这会降低模型的准确度。
所以,我们使用过滤(filter)操作,确保仅保留玩家位置确定的数据。
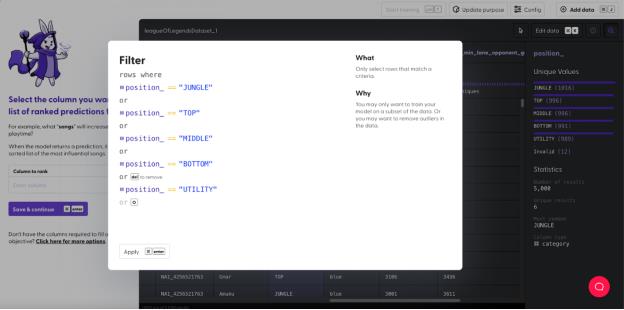
此外,我们还有一列表示玩家在比赛进行到 10 分钟时积攒的金币数量,该列包含 35 个“0”值。不幸的是,这 35 行“ten_min_lane_opponent_gold”列为空值的数据必须过滤掉,因为这些数据不完整,会导致预测结果不准确。
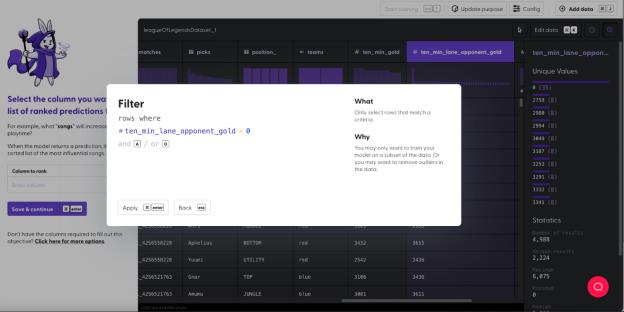
回顾一下我们构建模型的初衷,我们希望找出玩家选择哪个英雄赢得比赛的概率最大。因此,我们必须移除不相关的列。后面我们还会重复这个步骤,因为在提取相关信息时,某些列也会被移除。

特征工程
该步骤的重点是将现有信息转化成明确的有效特征,因此我们来添加一些列,告诉模型决定排名赛中的优秀玩家的因素有哪些。除此之外,该步骤会进一步过滤数据,并移除不相关的列。
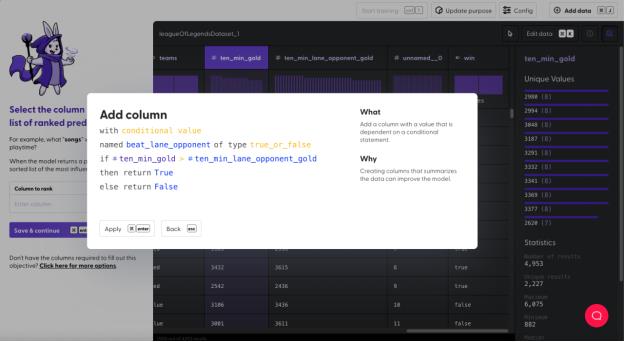
判断某位玩家的表现是否优异的一种方法是,观察他们能否在 10 分钟内击败自己的对线对手,这是比赛的关键转折点。虽然这并不能保证他们一定能赢,但为他们带来了优势,因为接下来他们就能够利用自己的力量辅助队友,并向敌人施压,而这些都能影响他们的成败。
由于团队合作很难界定和测量,所以我们简单地加一个标签(列“beat_lane_opponent”),表示玩家是否击败了自己的对线对手并占据了优势(布尔值)。
接下来,我们将列“ten_min_gold”(十分钟内获得的金币)换成一个布尔值列,这样就可以将金币数量(范围为2,223~6,075,非常精确的数值)简化成“True”或“False”,以表明这位玩家是否超过了对手。对于模型来说,这个值更容易理解,而且也有助于决定哪些因素会影响到最终的结果。
最后,我们再加一个比较列,比较一下两个列,如果超过了对手就返回“True”。
可能有些人非常熟悉 API 与 JSON,我们知道有时我们会收到 JSON 数据,需要编写代码挖掘相关的数据。如果你想知道为何人们以这种格式存储数据,可以了解一下 JSON 数据在存储辅助信息方面的实际用途。
在本文中,我们感兴趣的是列“challenges”中包含的哪些数据能够帮助我们实现目标。下面的例子展示了一行 JSON 数据所包含的信息:

由于我们希望预测某个英雄是否强大,而且有出众的表现,所以我们只关心“teamDamagePercentage”(团队伤害比例)。
下面,我们需要一些数学演算。主要的评估因素是与团队成员相比,你的金币贡献率是多少,我们称之为“gold percentage”(金币比例),计算公式如下:
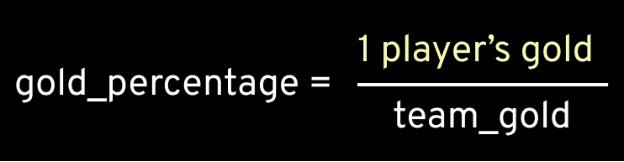
为了计算这个值,首先我们需要聚合(即针对一组数据执行操作)比赛与团队,求出团队获得的金币总数。这个操作称为聚合总和,详情请参见这里(https://www.mage.ai/blog/feature-engineering-total-sum)。
我们通过对列“gold”执行聚合操作,求出团队的总金币数“team_gold”。
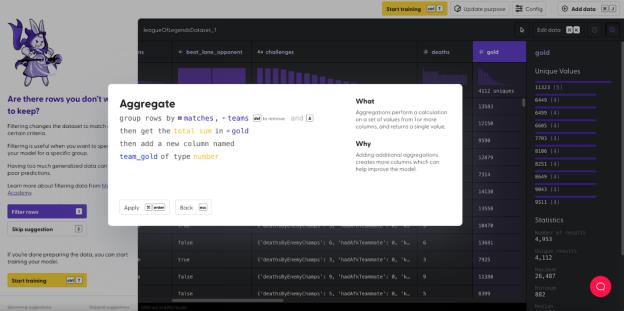
下面,我们通过相同的操作,求出列“ten_min_gold”(十分钟内获取的金币)的总和,并保存到列“team_ten_min_gold”(十分钟内团队获取的金币)中。
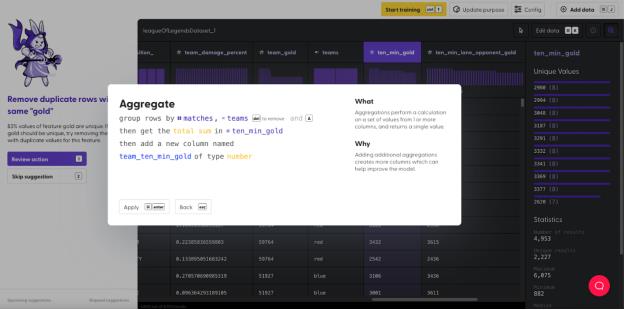
每位玩家获得的金币数除以团队总金币数,就可以求出“gold percentage”(金币比例)。
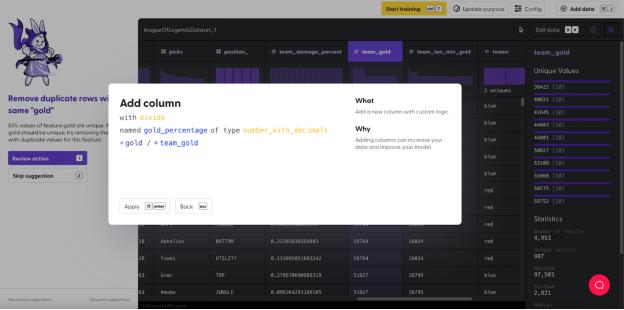
与之类似,“ten_min_gold”(十分钟内获取的金币)除以“team_ten_min_gold”(十分钟内团队获取的金币),就可以求出每位玩家在 10 分钟内贡献金币的比例,即“gold_ten_min_percentage”(10 分钟内的金币比例)。
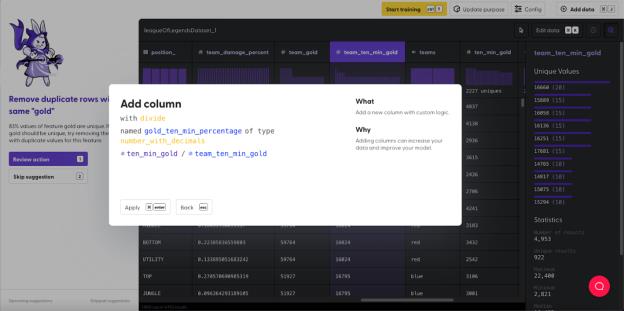
最后,我们利用“gold percentage”(金币比例)来观察某位玩家在比赛的过程中做出的贡献是否在增长。如果某位玩家在 10 分钟内为金币比例做出了巨大贡献,那么他们是否利用这笔资金帮助队友取得了胜利?或者这笔资金“打了水漂”?
为了观察玩家贡献的金币比例增长了还是下降了,我们求“gold_ten_min_percentage”(10 分钟内的金币比例)与“gold percentage”(金币比例)之差,我称这个特征为“scalability”(成长性)。
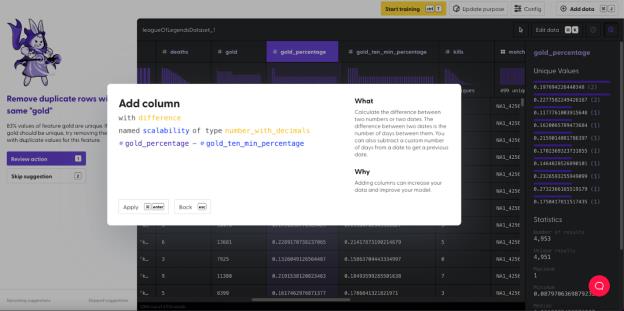
在前面的介绍中,我们曾提及在提取完信息后,我们会移除一些列,也会为了更好地汇总数据而添加一些列。
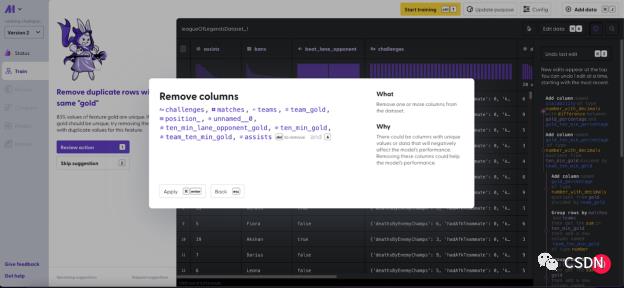
最终,我们一共有 11 列,分别如下:
● bans:禁用的英雄
● beat_lane_opponent:是否击败对线对手
● deaths:死亡次数
● gold:金币数量
● gold_percentage:金币比例
● gold_ten_min_percentage:10 分钟内的金币比例
● kills:击杀数量
● picks:选择的英雄
● scalability:成长性
● team_damage_percentage:团队伤害比例
● win:输赢
到此为止,数据的准备工作就完成了,下面我们开始训练模型。

模型训练
回顾一下,排名模型需要完成的工作:
● 评估的是哪个英雄(列“picks”);
● 在白金和钻石级别的比赛中获胜的最大概率;
● 按照获胜的概率从大到小排列数据,根据每位英雄获胜的次数,给他们打分;
● 根据排序列表中每位英雄的相对位置,预测选择某个英雄能否赢得一场排名比赛。
上述内容看起来可能有点不太好理解,我们创建了一个可视化工具,帮助你熟悉排名及其过程:
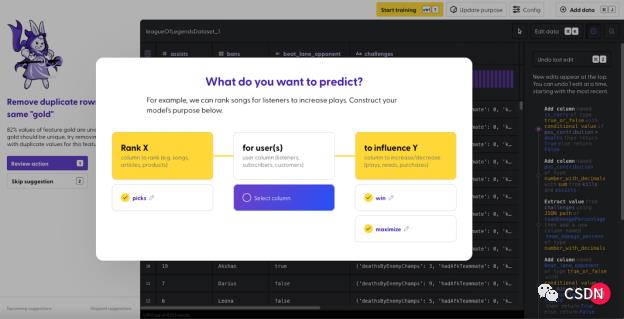
训练模型指的是,模型接收我们精心加工过的数据,然后分割出一批数据,学习如何预测当玩家选择某个英雄并达成特定目标后能否赢得比赛。
为了公平地计算该模型的准确度,我们使用90%的数据来教模型如何预测哪些英雄能赢得比赛,而其余的10%则用于测试模型的预测是否正确。

如果你想了解如何分割训练数据与测试数据,请参见“K折交叉验证”的相关课程。

评估
到此为止,我们的模型已经训练好了,而且我们能够解释模型给出的结果。一般我们会使用准确率、精确率和召回率来评估某个模型的预测结果是否准确。然而,由于这些指标是通用的,所以我们还会使用 SHAP 值来分析每一列对最后结果的影响。
这一切都是为了在下一个再训练步骤中理解模型,并提升模型的性能。
我们的模型的性能评估结果如下:
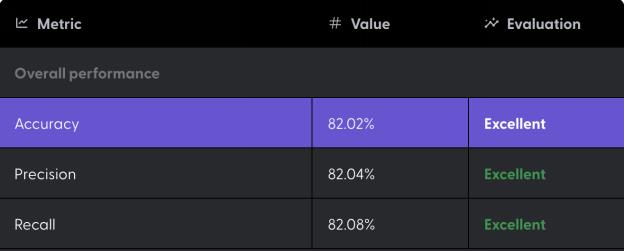
接下来,我们需要进行一系列的测试。在测试阶段,我们需要通过以下测试样本来评估上述指标:
● 在我们的测试中,玩家选择了瑟雷西,最后准确率为 82%,这意味着该模型正确预测瑟雷西玩家结果的成功率为 82%。包括他们输掉的游戏。
● 精确率指的是模型正确预测瑟雷西玩家获胜的概率。
● 召回率为 80%,指的是在我们的测试数据中,如果有 5 次瑟雷西玩家获胜,则模型可以识别出其中 4 次。
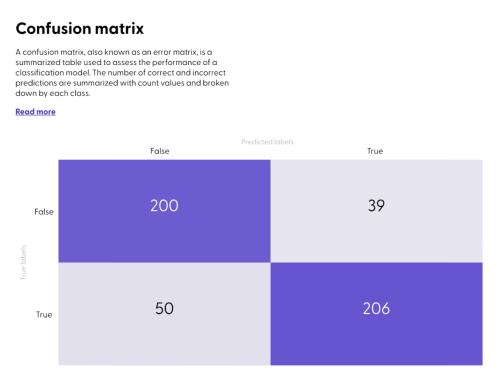
此外,通常我们会利用这三个指标构建一个混淆矩阵。
虽然上述矩阵有点难以理解,但我敢肯定数学科学家一定能看懂。
为了确定哪些列对预测结果的影响最大,我们在页面“Top features”(顶级特征)上展示了各个列与预测结果之间的关系。
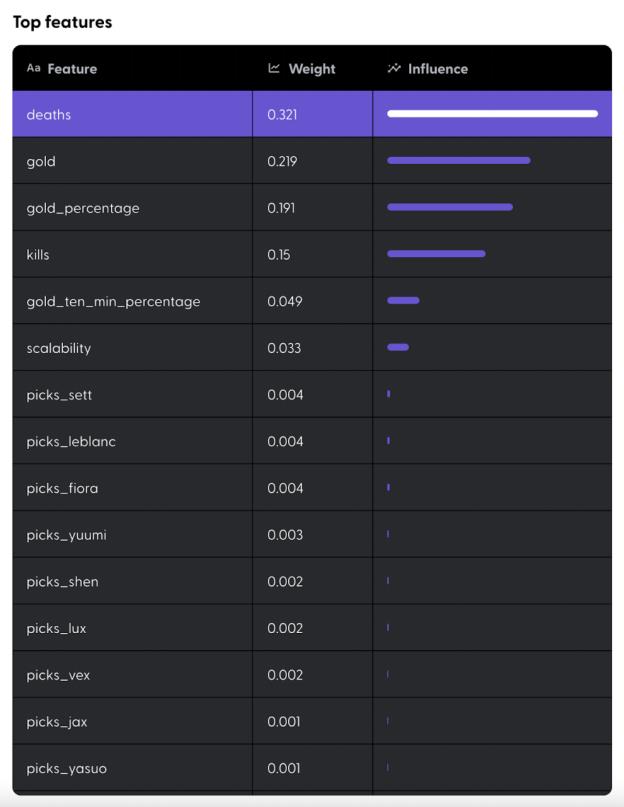
从上述列表中,我们可以看出:
● 玩家是否能够击败对线对手对比赛的结果并没有实质性的影响,因为列“beat_lane_opponent”(击败对线对手)并没有出现在该列表中。
● 对比赛结果影响最大的列实际上是“deaths”(死亡次数),表明减少自己的死亡次数就可以增加获胜的机率,这甚至超出了升级技能。
● 在我们的测试集中,每个英雄只有1~2个预测结果,这说明 5000 行的数据不足以预测英雄联盟 140 多位英雄。
通过顶级特征列表,我们还可以看出哪些列对预测结果基本没有影响。既然“bans”(禁用英雄)、“beat_lane_opponent”(击败对线对手)和“team_damage_percentage”(团队伤害比例)并没有出现在上述列表中,我们可以在重新训练的时候排除这些列,从而改进我们的排名模型。

部署 API
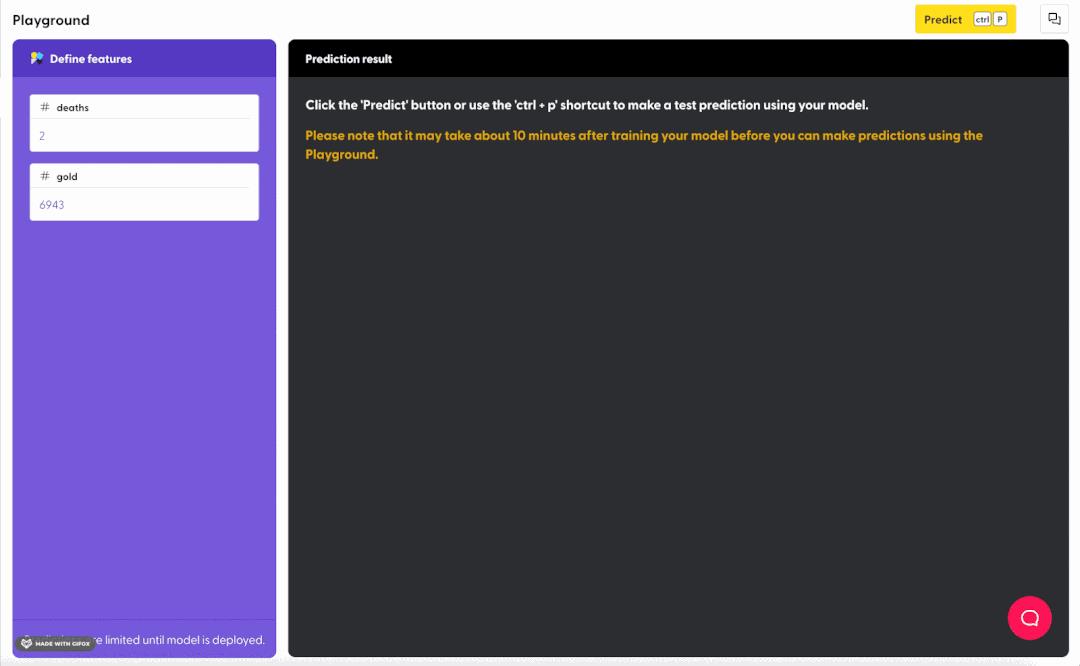
如果你很好奇一定的金币数量和死亡次数是否会影响获取机率,可以尝试在页面“Predict > Playground”中部署这个 API,并自定义预测。
在下方的动图中,我们输入了“4次死亡”和“7000 金币”,然后想看一看哪个英雄最有可能取胜的列表。如你所见,在这个死亡次数和金币数量下,英雄巴德、诺提勒斯、阿利斯塔可以提升你获胜的机率。

总结
你觉得在经过预处理、训练和评估后,我们的排名模型能够回答本文开头提出的问题了吗?
问题:哪些英雄能提升我赢得白金或钻石比赛的机率?
答案:尽管我们没有足够的数据,还无法自信地给出结果,但根据1~2个测试结果,我们姑且可以认为:
● 选择赛特、勒布朗、菲奥娜、拉克丝、慎和贾克斯能够提高获胜的机率;
● 选择悠米、薇可丝和亚索获胜的机率偏低。
问题:哪些因素对于比赛胜负的影响最大?
答案:死亡次数和金币数量对获胜的影响最大,所以如果你想赢得钻石或白金级别的游戏,那么就不要送人头,还要多赚金币。
问题:在十分钟内,使用某个英雄,赢得一场钻石比赛并获得相应金币的概率有多大?
答案:尽管我们无法根据英雄的“picks”做出预测,但你可以通过上述页面“Predict > Playground”,尝试不同的输入(如击杀次数、金币数和死亡次数),看看在这些统计数据下哪些英雄获胜的机率最高。
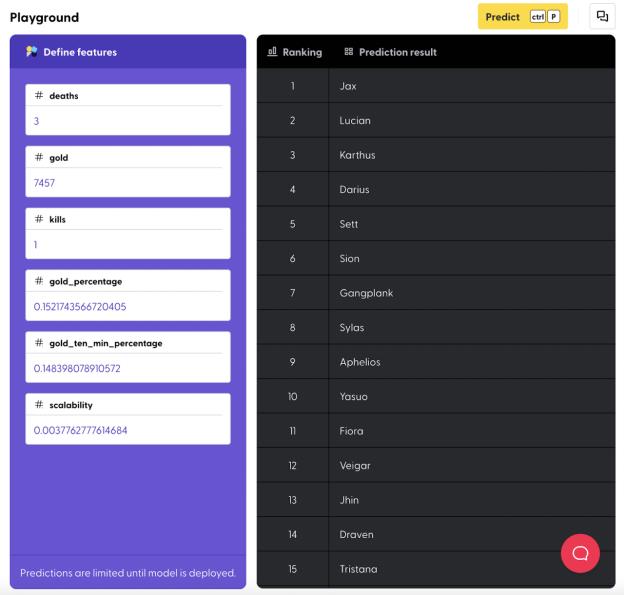
例如,根据上述结果,在 3 次死亡、7000 金币会 1 次击杀的情况下,最有可能取胜的英雄为:贾克斯、路西恩、卡尔萨斯。
原文链接:https://www.mage.ai/blog/league-of-legends-ranking-guide

往
期
回
顾
技术
资讯
技术
技术

分享

点收藏

点点赞

点在看
以上是关于利用机器学习的排名模型,提升你在英雄联盟的排名!的主要内容,如果未能解决你的问题,请参考以下文章