python爬虫篇:为了追个漫画我居然用上爬虫,别人说我不讲武德
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫篇:为了追个漫画我居然用上爬虫,别人说我不讲武德相关的知识,希望对你有一定的参考价值。
目录
1.前言
大家好,我是辣条,只能看不能吃的辣条~
最近在追xx动漫,但是没看几章你们懂的,就弹出来一个让我成为尊贵的氪金客户,不然就没法接着往下看了,于是乎我就开始琢磨出来了这个玩意,重点来了,看看就可以了,我的目的是让你们学到技术可不是钻空子哈,毕竟这个是的真的刑啊,懂的都懂~
再次重申:当前文章只限于技术分享,严禁用作其他用途!!!!
2.采集目标
XX漫客

3.工具准备
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests、csv
4.效果展示
5.项目思路解析
爬虫基本四个步骤:
-
获取到目标资源地址
-
选取到自己想看的漫画,这里辣条就选取的斗破苍穹,最近有在追这个动漫,特效啥的确实到位,就是更新速度太慢了,去把动漫也刷一遍(大老婆,二老婆镇楼)

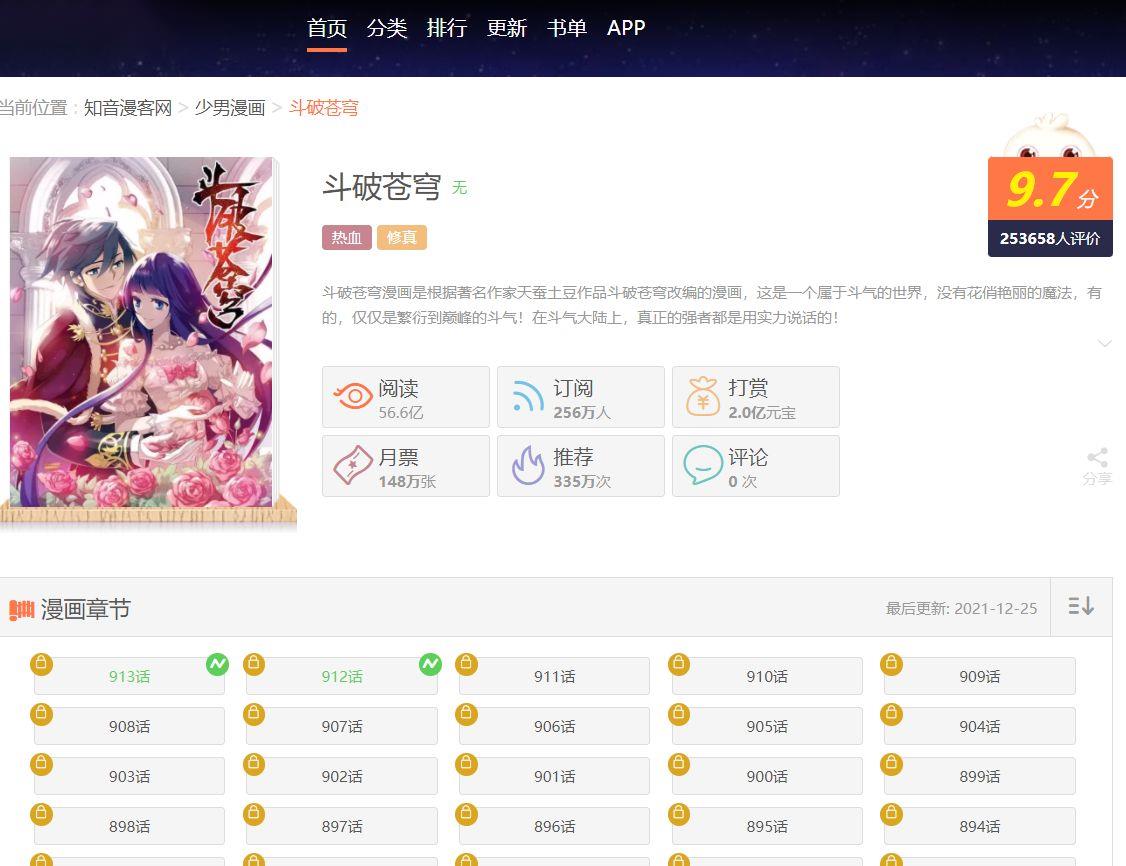
当前页面是整个漫画的章节页面,需要提取出全部的章节数据信息,当前的是页面数据,但是我们的数据是需要进入到详情页面的图片信息,但是这个网址的数据是需要星钻的,我们先去解析试看的漫画,进入详情页面抓取到加载的数据信息文件
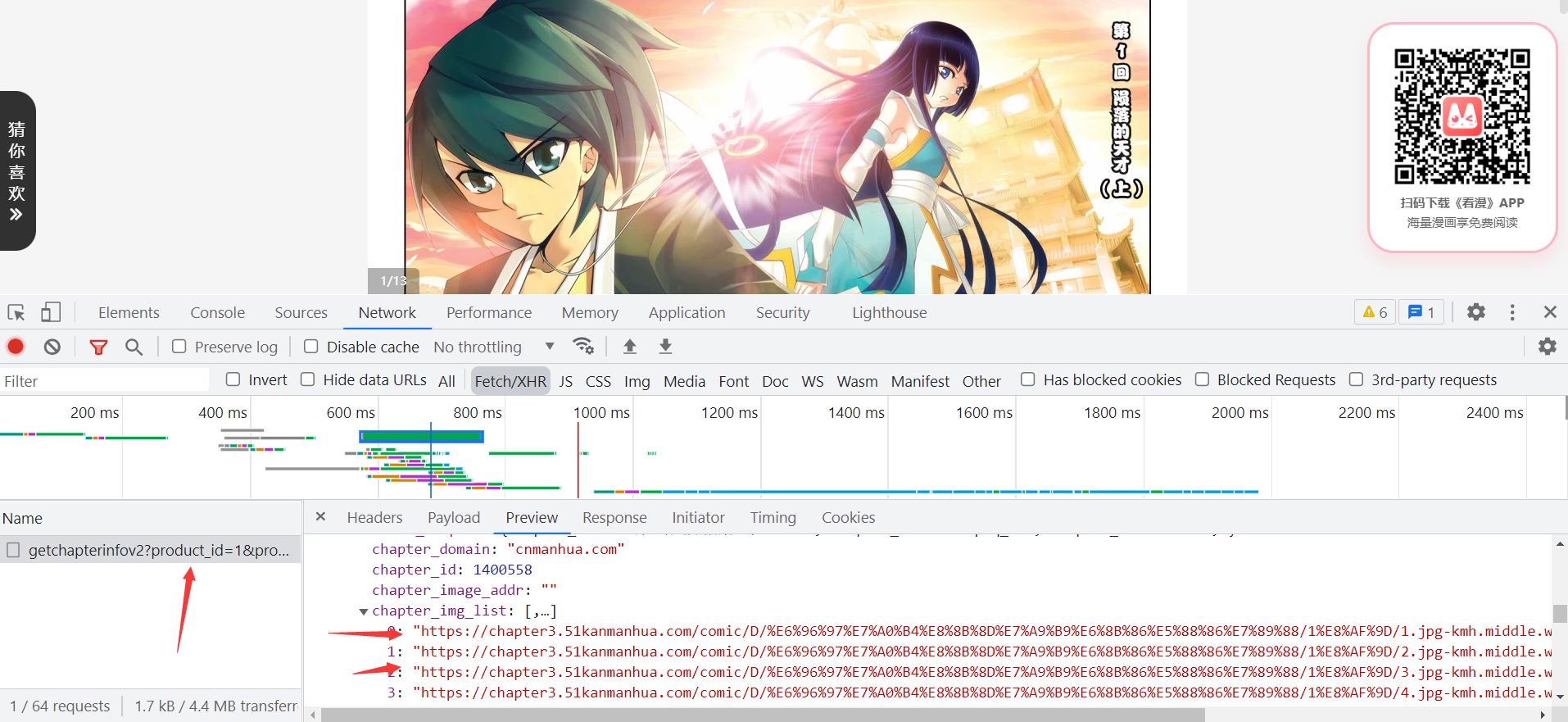 **这个数据是我们想要的漫画图片的地址,现在分析网址的加载方式:**https://www.kanman.com/api/getchapterinfov2?product_id=1&productname=kmh&platformname=pc&comic_id=25934&chapter_newid=dpcq_1h&isWebp=1&quality=middle
**这个数据是我们想要的漫画图片的地址,现在分析网址的加载方式:**https://www.kanman.com/api/getchapterinfov2?product_id=1&productname=kmh&platformname=pc&comic_id=25934&chapter_newid=dpcq_1h&isWebp=1&quality=middle
可以看出来数据的页面转换是通过chapter_newid来进行跟换的,要是需要第二页直接修改就行,那后面需要星钻的章节也迎刃而解,这里避免敏感信息就不强调了
-
-
发送网络请求,获取数据
- 发送请求,爬虫有个核心的技巧,他更多的是在模仿客户端发送网络请求,Python请求库用的比较多的是requests,想要用框架scrapy比较合适,在发送请求时带上请求头,将爬虫伪装成浏览器
-
提取数据
- 目前我们获取的数据是json数据,可以直接将数据转成字典的数据类型通过键值对进行数据的提取就行
-
保存数据
- 数据保存我们直接保存到当前的文件夹,单独的一个章节保存成一个单独的文件(或者各位看官可以自己考虑)
当前文章只限于技术分享,严禁用作其他用途!!!!
6.简易源码分享
import requests
import json
import time
import os
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
def parse(url):
print(url)
res = requests.get(url, headers=headers).json()
print(res)
chapter_name = res['data']['current_chapter']['chapter_name']
chapter_img_url = res['data']['current_chapter']['chapter_img_list']
print(chapter_name, chapter_img_url)
path = '斗破苍穹/' + chapter_name
if not os.path.exists(path):
os.mkdir(path)
download(chapter_img_url, path) # 每次下载漫画时,需要传入相关的参数
def download(img_url_list, path):
i = 0
for img_url in img_url_list:
res = requests.get(img_url, headers=headers)
print(res.content)
filename = path + "/" + str(i) + '.jpg'
with open(filename, 'wb') as f:
f.write(res.content)
i += 1
print(f'正在下载:path第str(i)张')
time.sleep(0.5)
if __name__ == '__main__':
for i in range(1, 20):
url = 'https://www.kanman.com/api/getchapterinfov2?product_id=1&productname=kmh&platformname=pc&comic_id=25934&chapter_newid=dpcq_h&isWebp=1&quality=middle'.format(i)
parse(url)
7.总结
再次重申重点在看知识点,不要去乱尝试,我可不想看你们从入门到“坐牢”
其次详细版源码可以看底下我的个人小卡片,还有我之前的30个游戏的源码包,还有python学习路线等等都可以有的~
以上是关于python爬虫篇:为了追个漫画我居然用上爬虫,别人说我不讲武德的主要内容,如果未能解决你的问题,请参考以下文章