Python遇上Excel,这20个常用操作也可以轻松操作
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python遇上Excel,这20个常用操作也可以轻松操作相关的知识,希望对你有一定的参考价值。
Excel与Python都是数据分析中常用的工具,本文将使用动态图(Excel)+代码(Python)的方式来演示这两种工具是如何实现数据的读取、生成、计算、修改、统计、抽样、查找、可视化、存储等数据处理中的常用操作!
本文内容较长,喜欢记得关注、点赞、收藏。
【注】文末提供技术交流群
数据读取
说明:读取本地Excel数据
Excel
Excel读取本地数据需要打开目标文件夹选中该文件并打开
Pandas
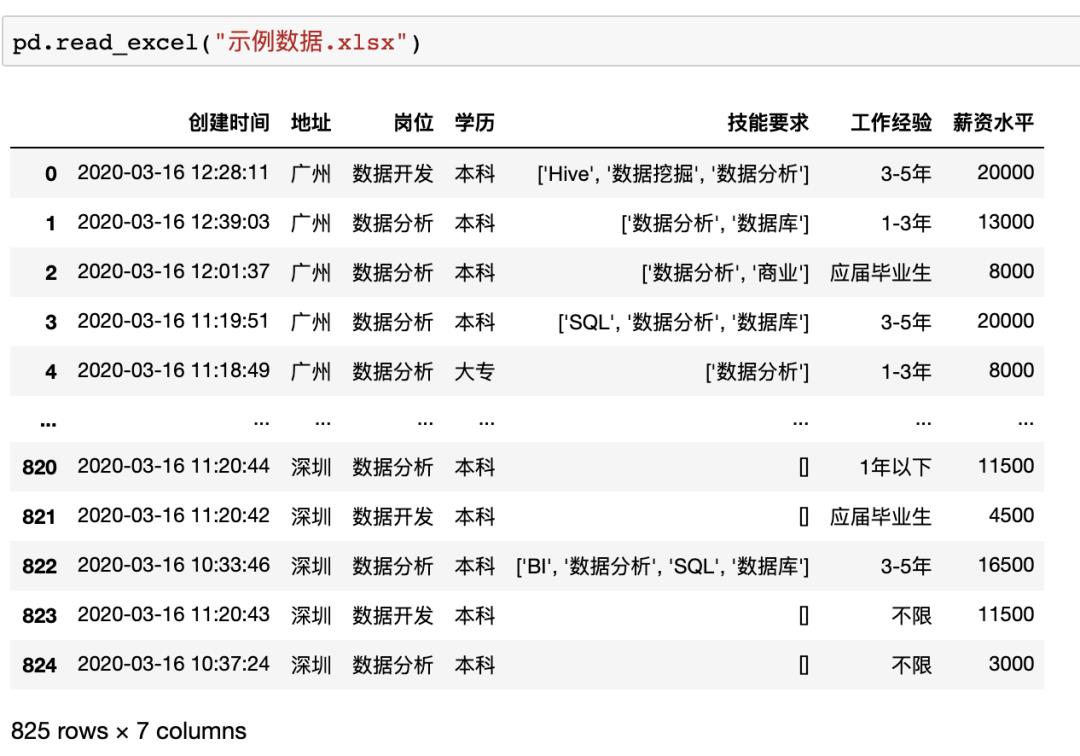
Pandas支持读取本地Excel、txt文件,也支持从网页直接读取表格数据,只用一行代码即可,例如读取上述本地Excel数据可以使用pd.read_excel("示例数据.xlsx")
数据生成
说明:生成指定格式/数量的数据
Excel
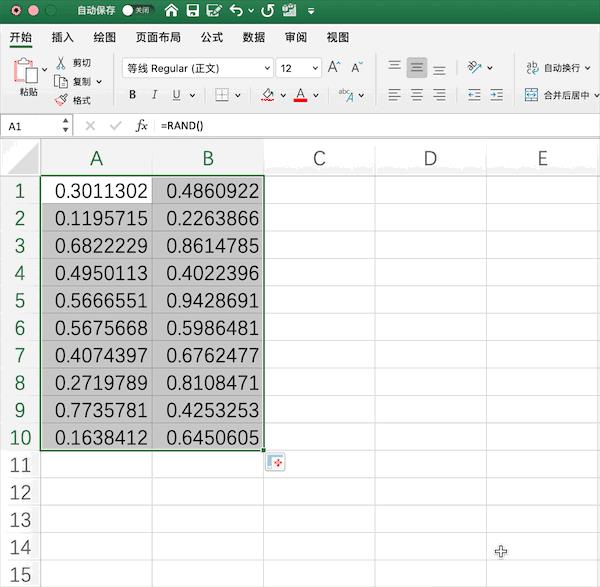
以生成10*2的0—1均匀分布随机数矩阵为例,在Excel中需要使用rand()函数生成随机数,并手动拉取指定范围
Pandas
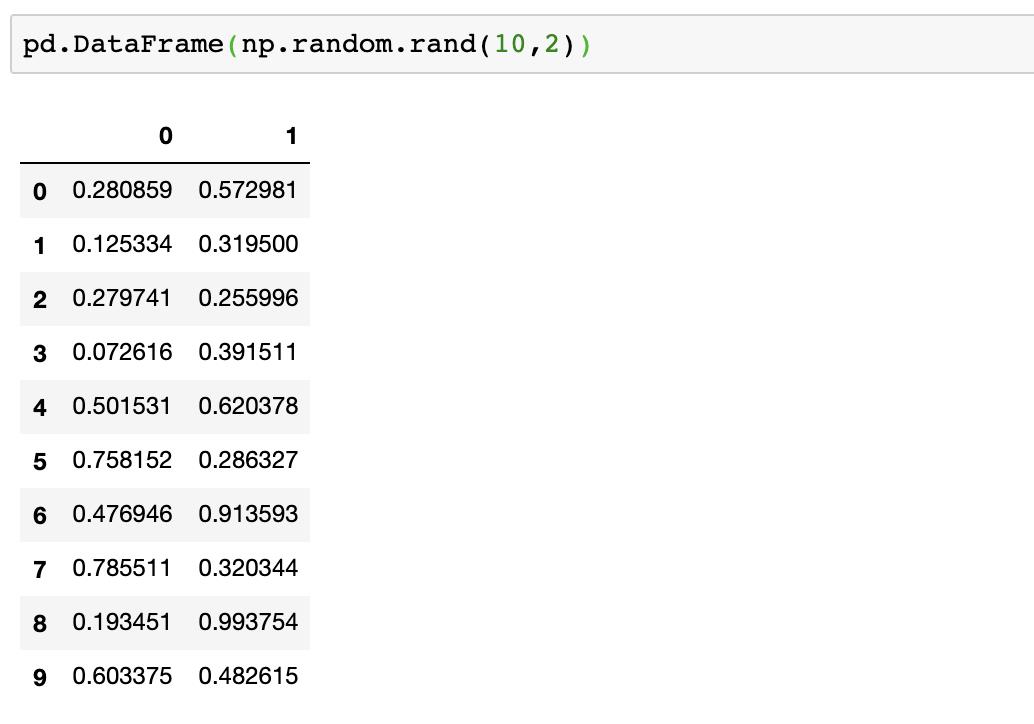
在Pandas中可以结合NumPy生成由指定随机数(均匀分布、正态分布等)生成的矩阵,例如同样生成10*2的0—1均匀分布随机数矩阵为,使用一行代码即可:pd.DataFrame(np.random.rand(10,2))
数据存储
说明:将表格中的数据存储至本地
Excel
在Excel中需要点击保存并设置格式/文件名
Pandas
在Pandas中可以使用pd.to_excel("filename.xlsx")来将当前工作表格保存至当前目录下,当然也可以使用to_csv保存为csv等其他格式,也可以使用绝对路径来指定保存位置

数据筛选
说明:按照指定要求筛选数据
Excel
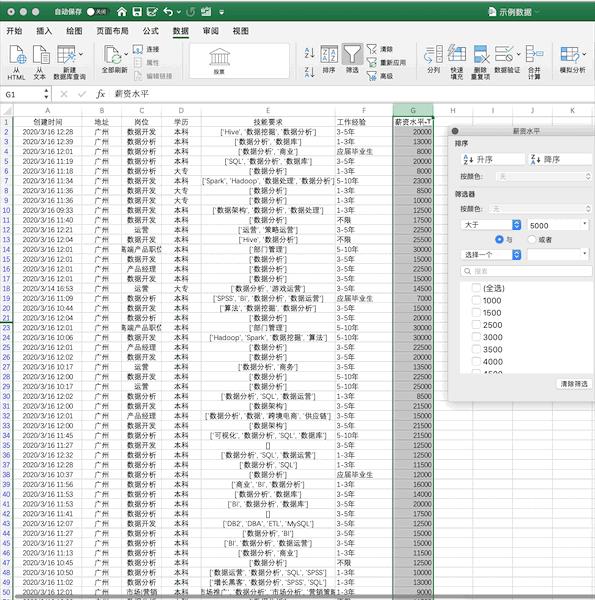
使用我们之前的示例数据,在Excel中筛选出薪资大于5000的数据步骤如下
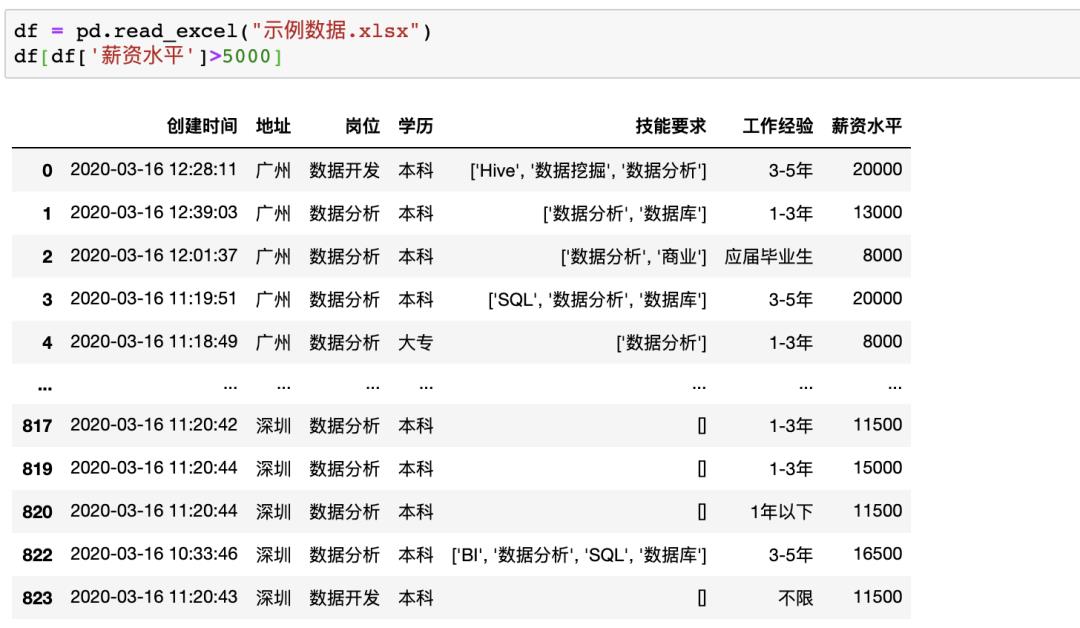
Pandas
在Pandas中,可直接对数据框进行条件筛选,例如同样进行单个条件(薪资大于5000)的筛选可以使用df[df[‘薪资水平’]>5000],如果使用多个条件的筛选只需要使用&(并)与|(或)操作符实现
数据插入
说明:在指定位置插入指定数据
Excel
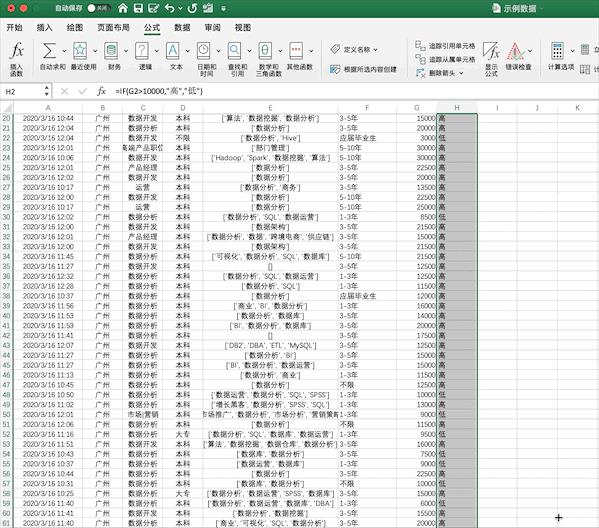
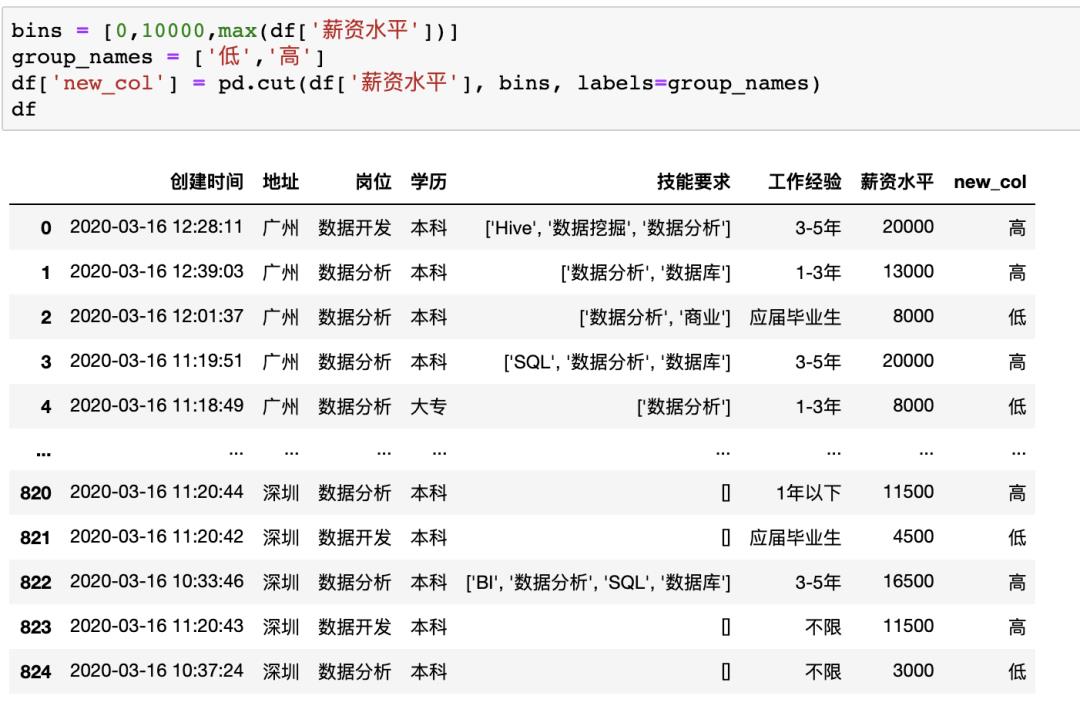
在Excel中我们可以将光标放在指定位置并右键增加一行/列,当然也可以在添加时对数据进行一些计算,比如我们就可以使用IF函数(=IF(G2>10000,"高","低")),将薪资大于10000的设为高,低于10000的设为低,添加一列在最后
Pandas
在pandas中,如果不借助自定义函数的话,我们可以使用cut方法来实现同样操作
bins = [0,10000,max(df['薪资水平'])]
group_names = ['低','高']
df['new_col'] = pd.cut(df['薪资水平'], bins, labels=group_names)
数据删除
说明:删除指定行/列/单元格
Excel
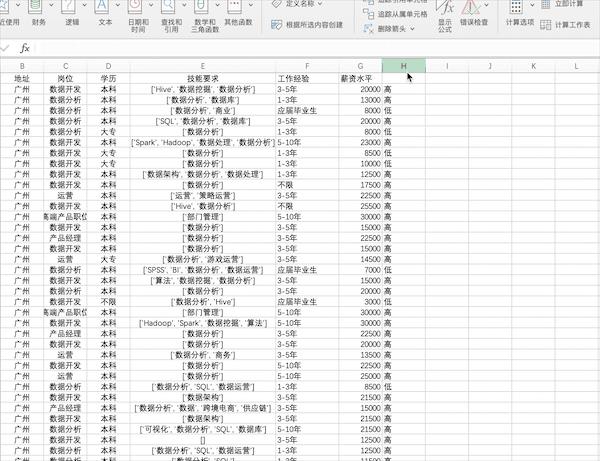
在Excel删除数据十分简单,找到需要删除的数据右键删除即可,比如删除刚刚生成的最后一列
Pandas
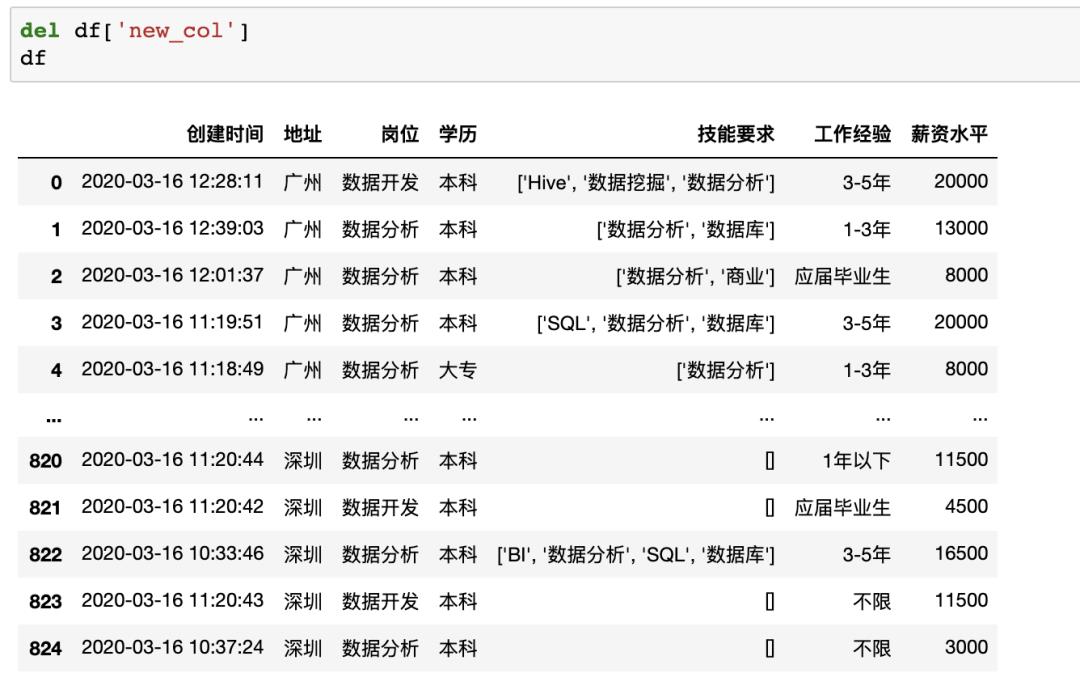
在pandas中删除数据也很简单,比如删除最后一列使用del df['new_col']即可
数据排序
说明:按照指定要求对数据排序
Excel
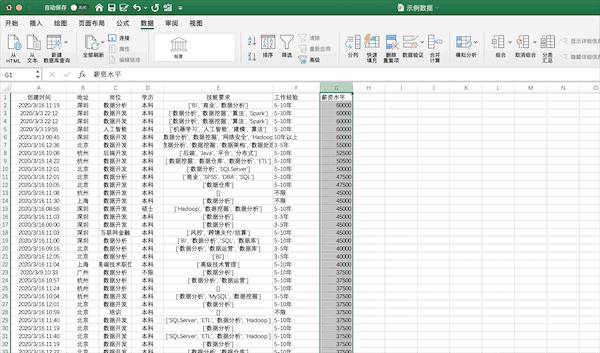
在Excel中可以点击排序按钮进行排序,例如将示例数据按照薪资从高到低进行排序可以按照下面的步骤进行
Pandas
在pandas中可以使用sort_values进行排序,使用ascending来控制升降序,例如将示例数据按照薪资从高到低进行排序可以使用df.sort_values("薪资水平",ascending=False,inplace=True)

缺失值处理
说明:对缺失值(空值)按照指定要求处理
Excel
在Excel中可以按照查找—>定位条件—>空值来快速定位数据中的空值,接着可以自己定义缺失值的填充方式,比如将缺失值用上一个数据进行填充

Pandas
在pandas中可以使用data.isnull().sum()来检查缺失值,之后可以使用多种方法来填充或者删除缺失值,比如我们可以使用df = df.fillna(axis=0,method=‘ffill’)来横向/纵向用缺失值前面的值替换缺失值
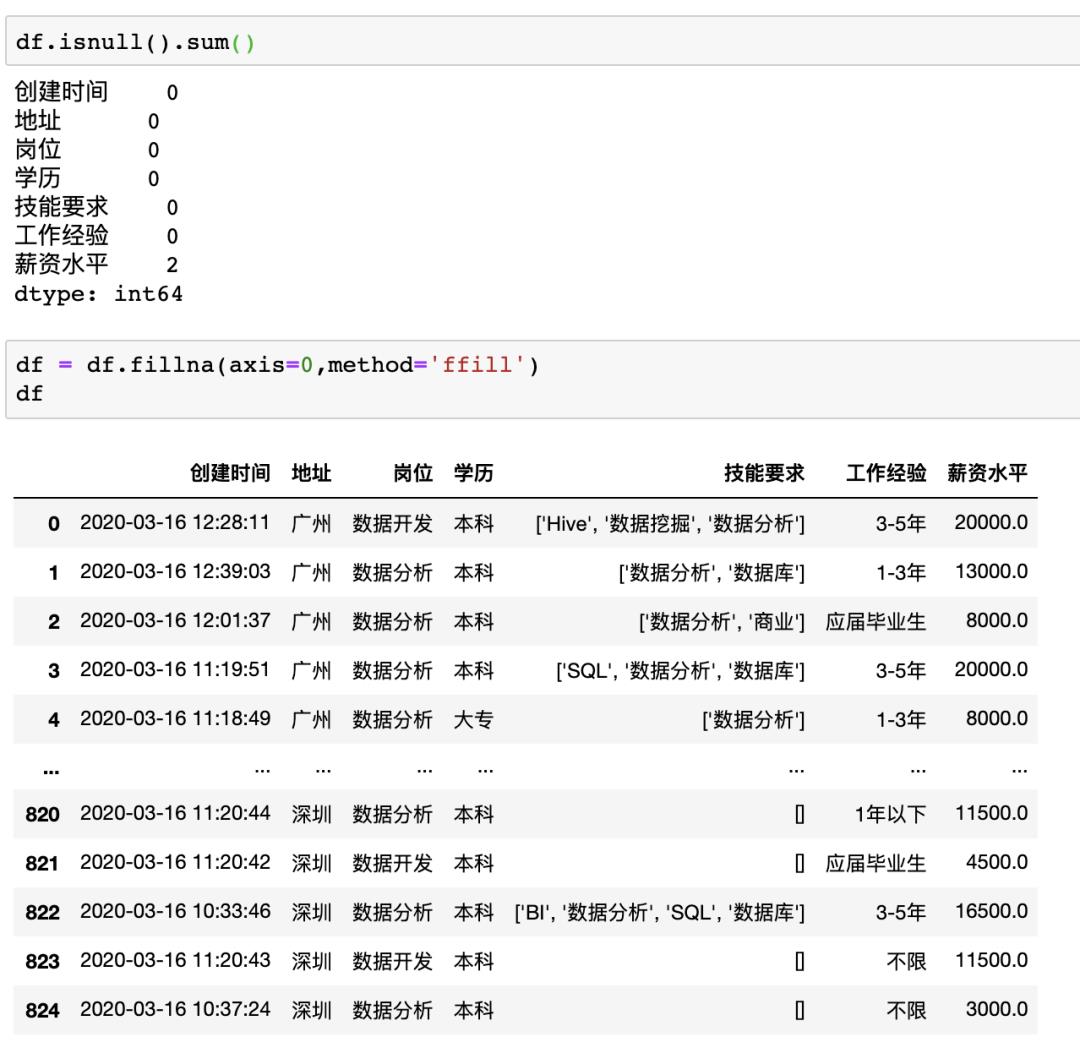
数据去重
说明:对重复值按照指定要求处理
Excel
在Excel中可以通过点击数据—>删除重复值按钮并选择需要去重的列即可,例如对示例数据按照创建时间列进行去重,可以发现去掉了196 个重复值,保留了 629 个唯一值。
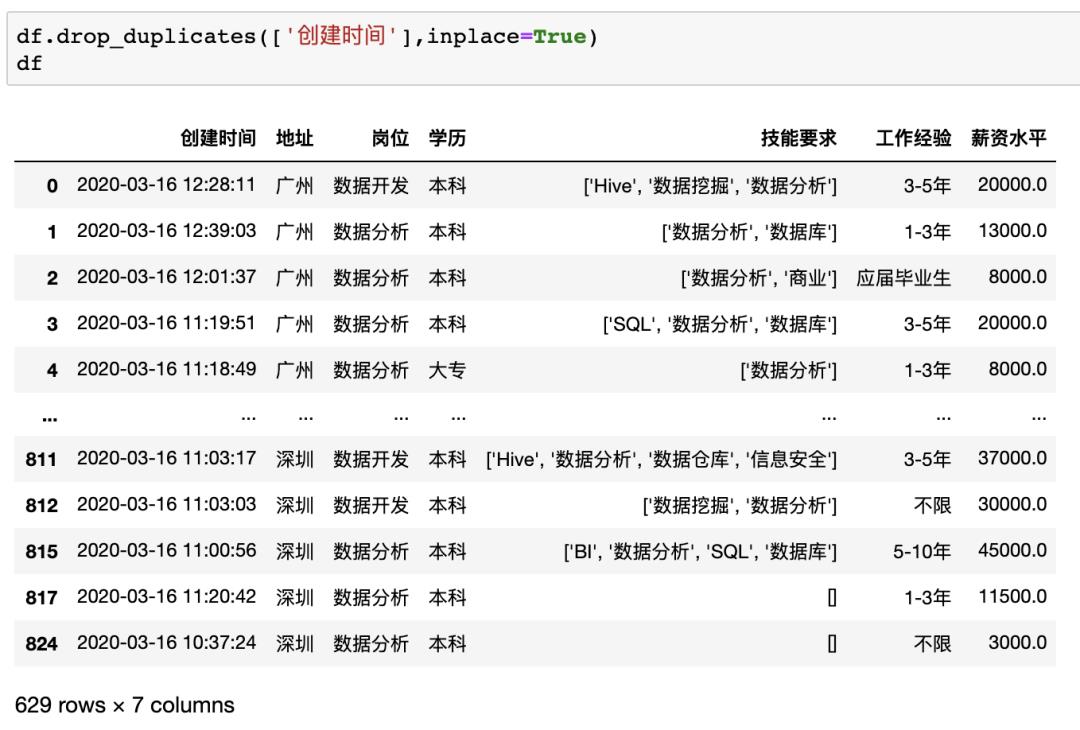
Pandas
在pandas中可以使用drop_duplicates来对数据进行去重,并且可以指定列以及保留顺序,例如对示例数据按照创建时间列进行去重df.drop_duplicates([‘创建时间’],inplace=True),可以发现和Excel处理的结果一致,保留了 629 个唯一值。
格式修改
说明:修改指定数据的格式
Excel
在Excel中可以选中需要转换格式的数据之后右键—>修改单元格格式来选择我们需要的格式
Pandas
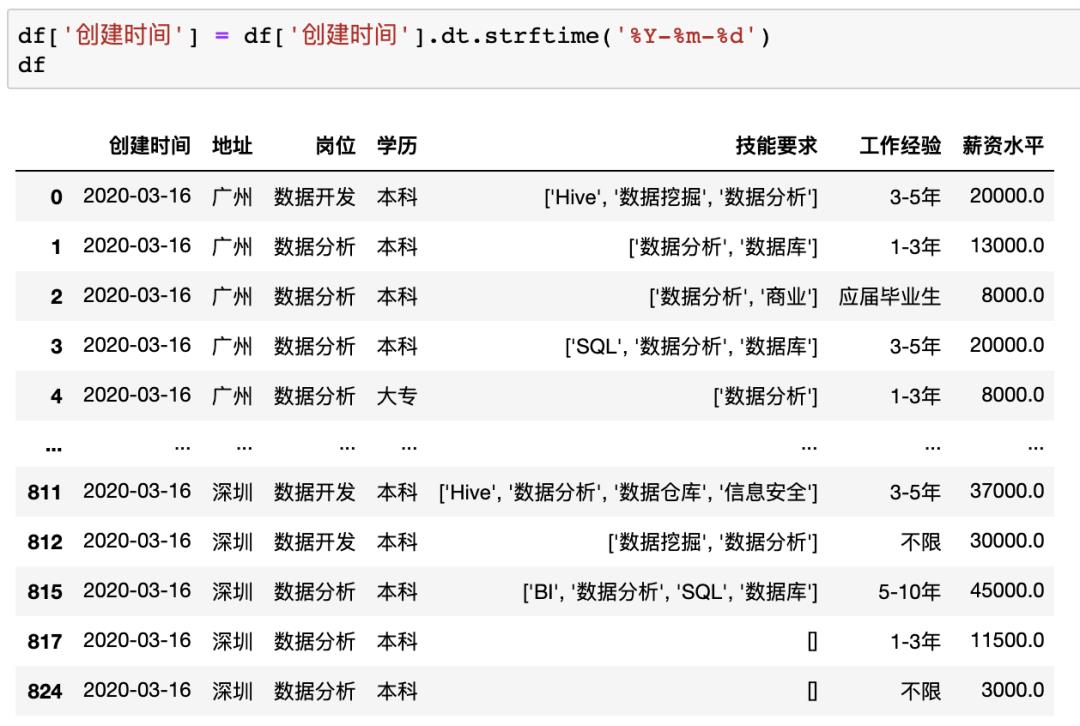
在Pandas中没有一个固定修改格式的方法,不同的数据格式有着不同的修改方法,比如类似Excel中将创建时间修改为年-月-日可以使用df[‘创建时间’] = df[‘创建时间’].dt.strftime(‘%Y-%m-%d’)
数据交换
说明:交换指定数据
Excel
在Excel中交换数据是很常用的操作,以交换示例数据中地址与岗位两列为例,可以选中地址列,按住shift键并拖动边缘至下一列松开即可
Pandas
在pandas中交换两列也有很多方法,以交换示例数据中地址与岗位两列为例,可以通过修改列号来实现
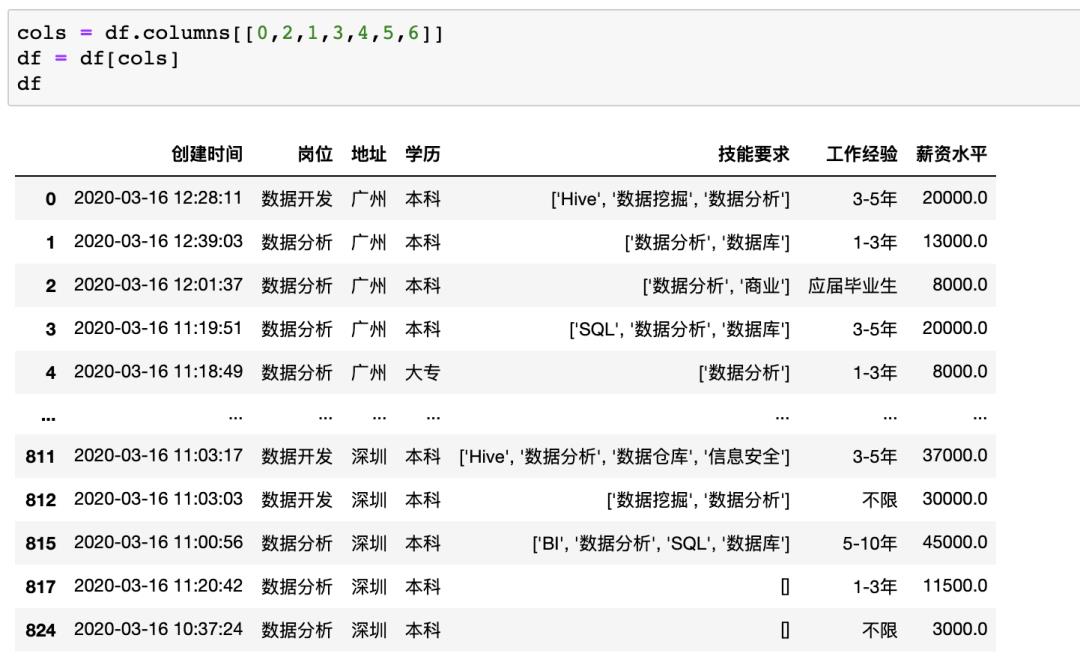
数据合并
说明:将两列或多列数据合并成一列
Excel
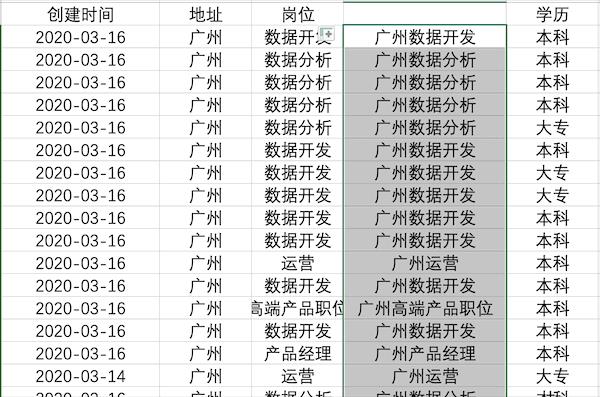
在Excel中可以使用公式也可以使用Ctrl+E快捷键完成多列合并,以公式为例,合并示例数据中的地址+岗位列步骤如下
Pandas
在Pandas中合并多列比较简单,类似于之前的数据插入操作,例如合并示例数据中的地址+岗位列使用df[‘合并列’] = df[‘地址’] + df[‘岗位’]
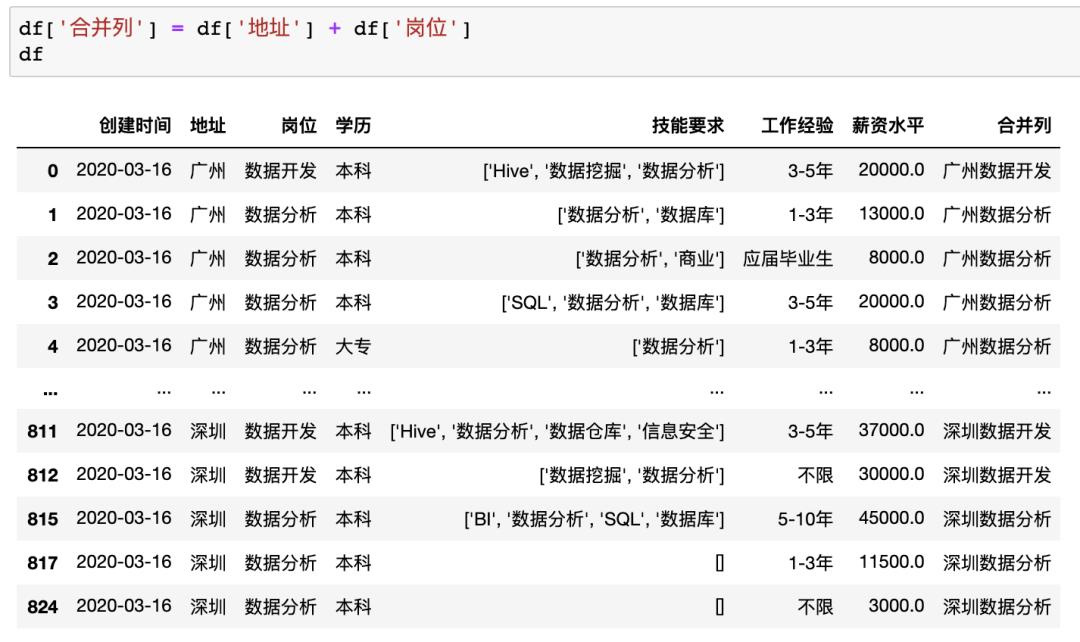
数据拆分
说明:将一列按照规则拆分为多列
Excel
在Excel中可以通过点击数据—>分列并按照提示的选项设置相关参数完成分列,但是由于该列含有[]等特殊字符,所以需要先使用查找替换去掉
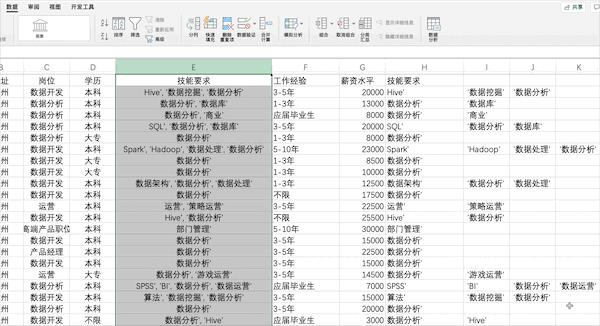
Pandas
在Pandas中可以使用.split来完成分列,但是在分列完毕后需要使用merge来将分列完的数据添加至原DataFrame,对于分列完的数据含有[]字符,我们可以使用正则或者字符串lstrip方法进行处理,但因不是pandas特性,此处不再展开。

数据分组
说明:对数据进行分组计算
Excel
在Excel中对数据进行分组计算需要先对需要分组的字段进行排序,之后可以通过点击分类汇总并设置相关参数完成,比如对示例数据的学历进行分组并求不同学历的平均薪资
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DfdJA1vg-1649206633925)(https://mmbiz.qpic.cn/mmbiz_gif/2GcSFhuAFlAO80zYzLTWVQo91jw9eMAUNV0PoLnRrJ4NDkMFYtRmzWDncicn4ic3ktgRmicC5vfocn2V1BeQz9DdA/640?wx_fmt=gif)]
Pandas
在Pandas中对数据进行分组计算可以使用groupby轻松搞定,比如使用df.groupby(“学历”).mean()一行代码即可对示例数据的学历进行分组并求不同学历的平均薪资,结果与Excel一致

数据计算
说明:对数据进行一些计算
Excel
在Excel中有很多计算相关的公式,比如可以使用COUNTIFS来统计薪资大于10000的岗位数量有518个
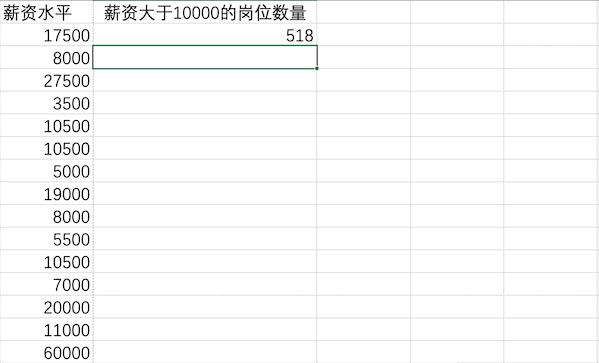
Pandas
在Pandas中可以直接使用类似数据筛选的方法来统计薪资大于10000的岗位数量len(df[df[“薪资水平”]>10000])

数据统计
说明:对数据进行一些统计计算
Excel
在Excel中有很多统计相关的公式,也有现成的分析工具,比如对薪资水平列进行描述性统计分析,可以通过添加工具库之后点击数据分析按钮并设置相关参数
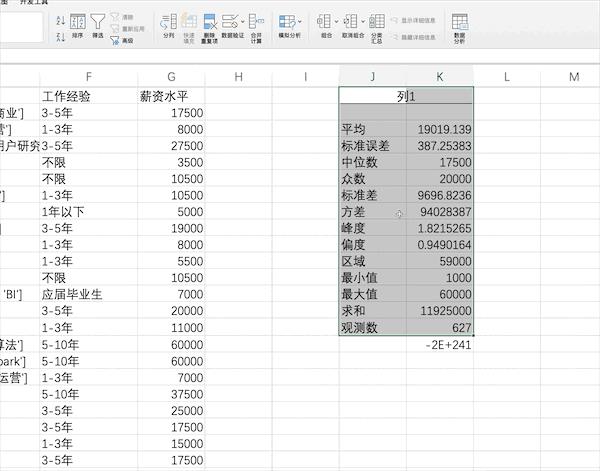
Pandas
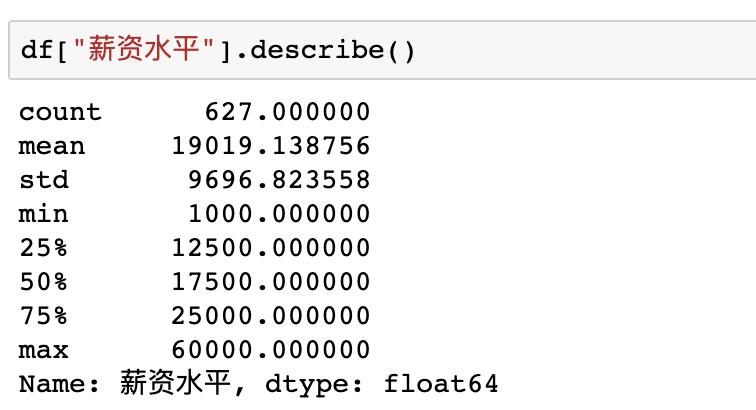
在pandas中也有现成的函数describe快速完成对数据的描述性统计,比如使用df[“薪资水平”].describe()即可得到薪资列的描述性统计结果
数据可视化
说明:对数据进行可视化
Excel
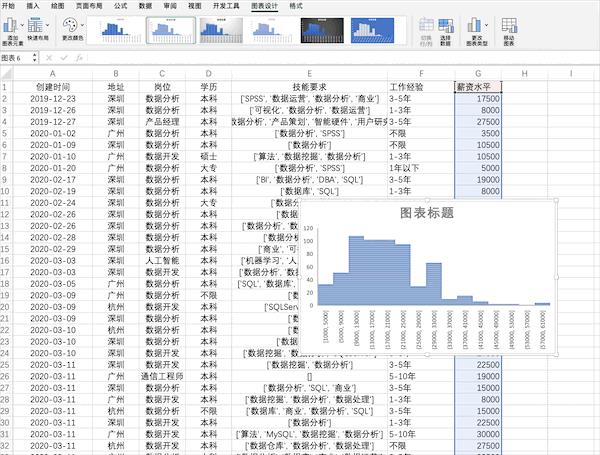
在Excel中可以通过点击插入并选择图表来快速完成对数据的可视化,比如制作薪资的直方图,并且有很多样式可以直接使用
Pandas
在Pandas中也支持直接对数据绘制不同可视化图表,例如直方图,可以使用plot或者直接使用hist来制作df[“薪资水平”].hist()

数据抽样
说明:对数据按要求采样
Excel
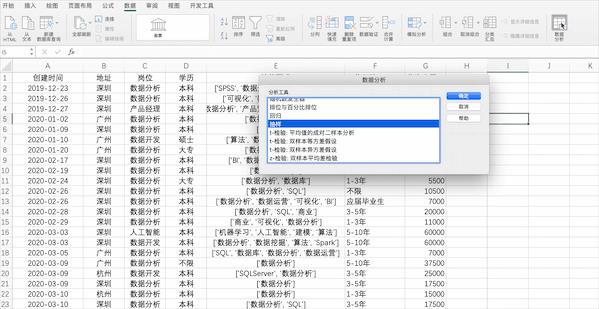
在Excel中抽样可以使用公式也可以使用分析工具库中的抽样,但是仅支持对数值型的列抽样,比如随机抽20个示例数据中薪资的样本
Pandas
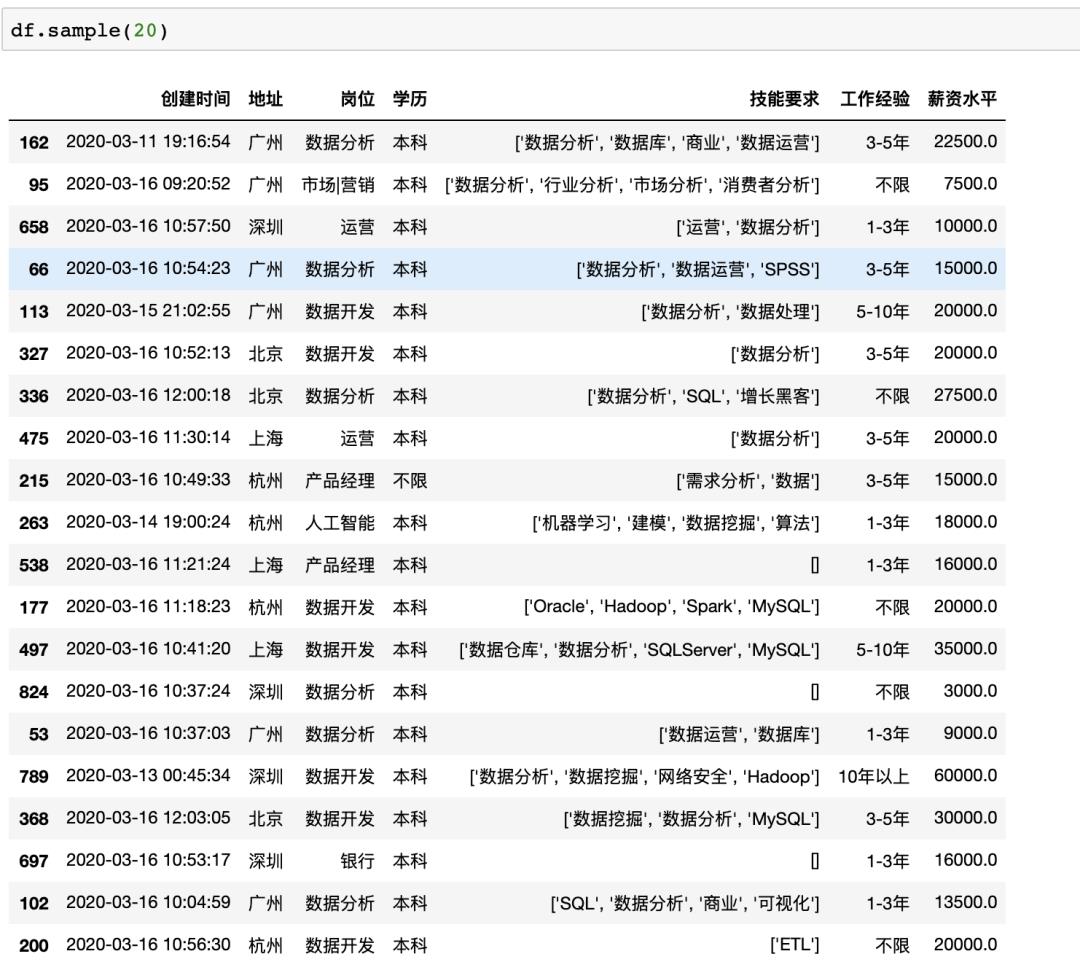
在pandas中有抽样函数sample可以直接抽样,并且支持任意格式的数据抽样,可以按照数量/比例抽样,比如随机抽20个示例数据中的样本
数据透视表
说明:制作数据透视表
Excel
数据透视表是一个非常强大的工具,在Excel中有现成的工具,只需要选中数据—>点击插入—>数据透视表即可生成,并且支持字段的拖取实现不同的透视表,非常方便,比如制作地址、学历、薪资的透视表
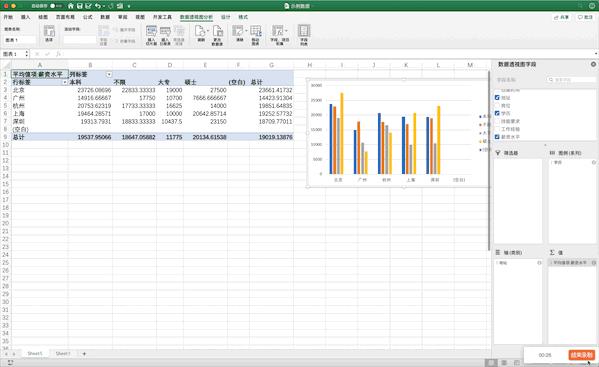
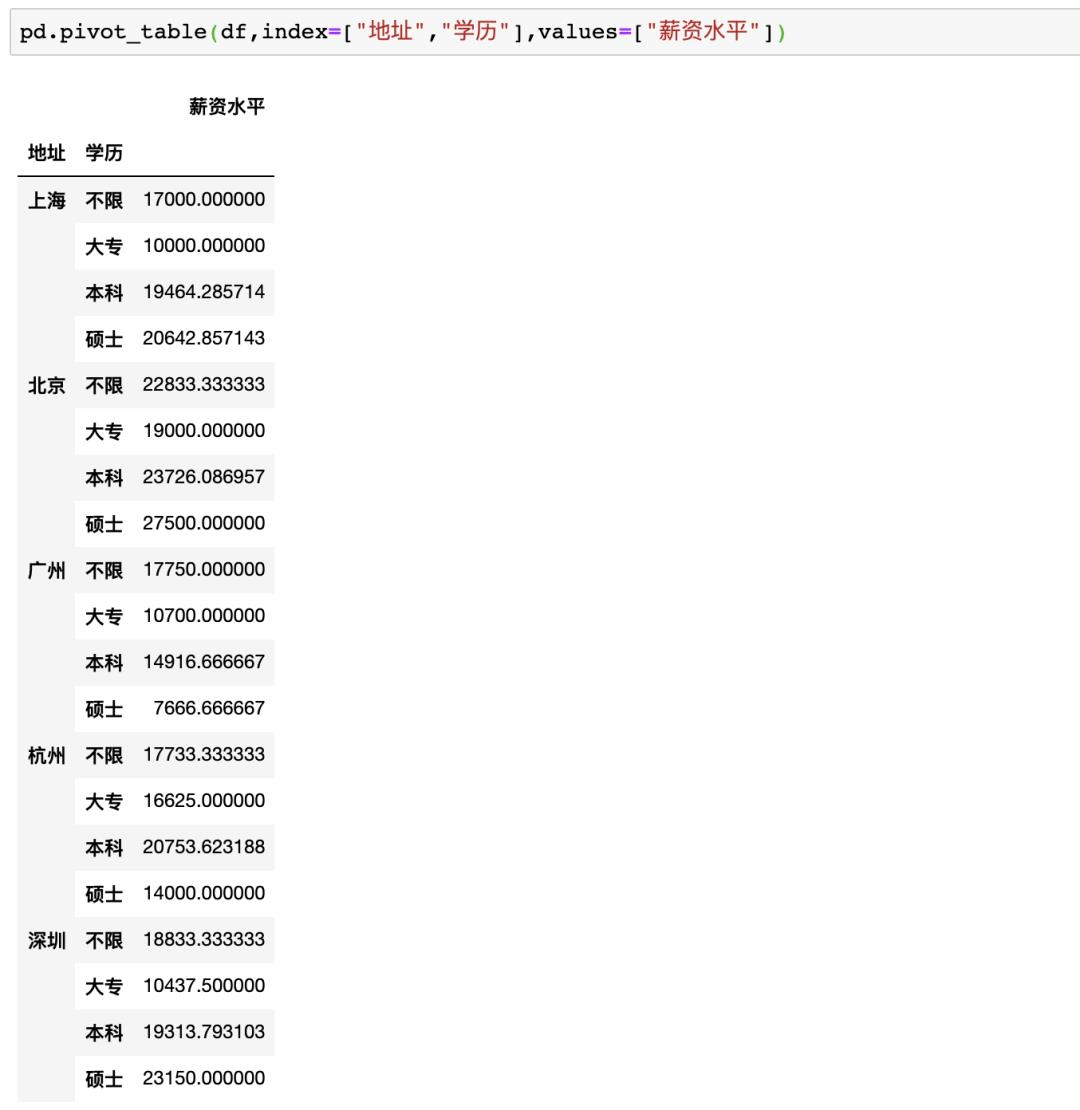
Pandas
在Pandas中制作数据透视表可以使用pivot_table函数,例如制作地址、学历、薪资的透视表pd.pivot_table(df,index=[“地址”,“学历”],values=[“薪资水平”]),虽然结果一样,但是并没有Excel一样方便调整与多样
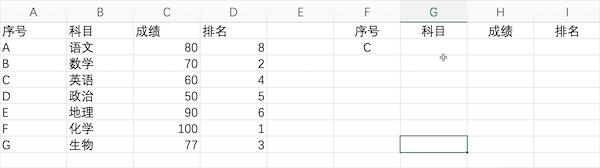
vlookup
说明:利用VLOOKUP查找数据
Excel
VLOOKUP算是EXCEL中最核心的功能之一了,我们用一个简单的数据来进行示例
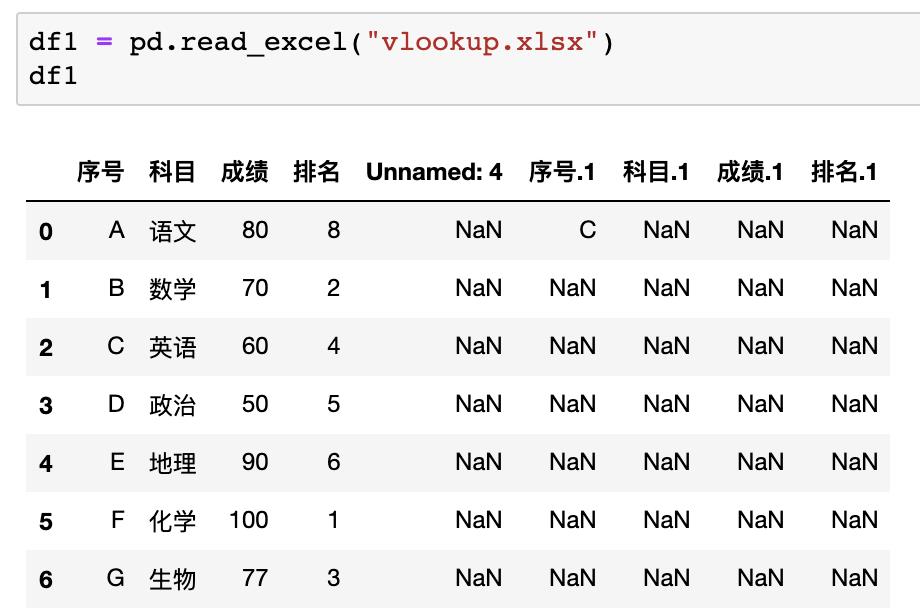
Pandas
在Pandas中没有现成的vlookup函数,所以实现匹配查找需要一些步骤,首先我们读取该表格
接着将该dataframe切分为两个

最后修改索引并使用update进行两表的匹配

结束语
以上就是使用Pandas来演示如何实现Excel中的常用操作的全部过程,其实可以发现Excel的优点就是大多由交互式的点击完成数据处理,而Pandas则完全依赖于代码,对于有些操作比如数据透视表,用Excel制作更加方便,而有些操作比如数据的分组、计算等,因Pandas可以与NumPy等其他优秀的Python库结合而显得更加强大,所以我们在处理数据时也需要正确选择使用的工具!
推荐文章
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于Python遇上Excel,这20个常用操作也可以轻松操作的主要内容,如果未能解决你的问题,请参考以下文章