KDD Cup大赛Baseline&思路开源了!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KDD Cup大赛Baseline&思路开源了!相关的知识,希望对你有一定的参考价值。
赛题名称
Baidu KDD CUP 2022
赛题链接
https://aistudio.baidu.com/aistudio/competition/detail/152/0/introduction
赛题背景
1
目标
预测风力涡轮机未来42小时的功率
2
数据
每 15 分钟采样一次数据。
数据包括:
时间信息;
气候信息:风速、风向、温度;
涡轮机信息:涡轮转子速度、发电机温度、轮毂温度;
地理位置信息:涡轮机空间分布矩阵。
3
评价指标
RMSE(均方根误差)和 MAE(平均绝对误差)的平均值。
赛题解析-数据预处理

1. 数据标签(发电机功率)中发现有负数,似乎不符合逻辑,需要进一步和主办方确认。
2. 对于标签为连续型变量的场景,可以尝试对标签先进行变换,预测获得结果后再重新逆操作回来,例如先取log1p,预测获得结果后再取expm1(注意log操作只能对大于0的数进行)。
3. 时序预测场景需要考虑训练集的时间范围。假设主办方给了半年的数据,可能只用最近一个月的数据来构造训练集,效果比全量数据好。
赛题解析-特征工程
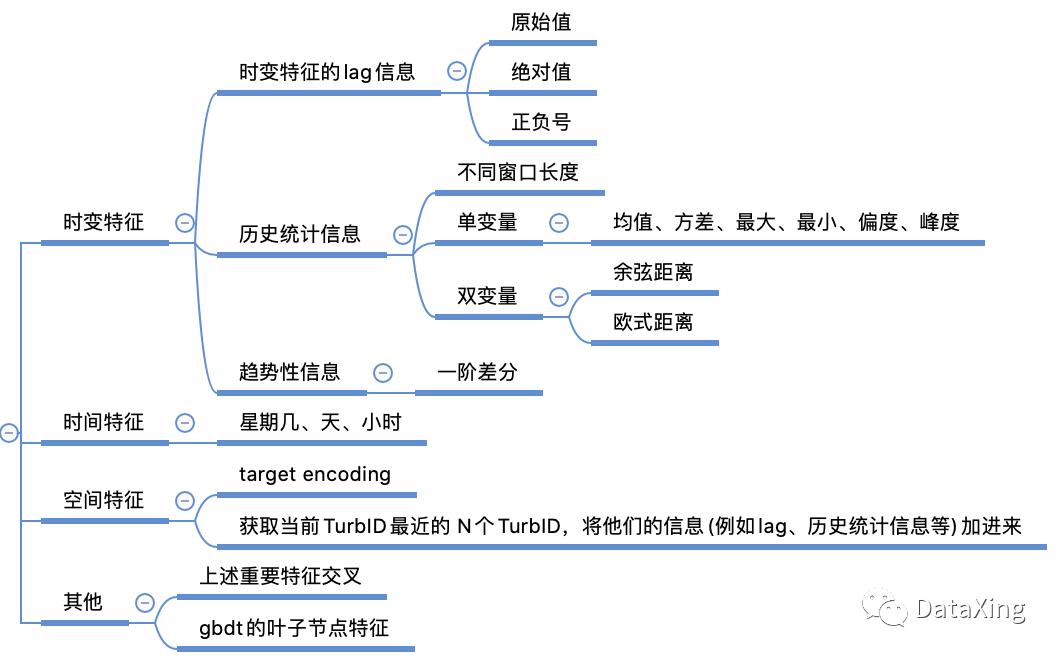
特征工程主要包括四大块。
对于时变的特征,例如赛题里的涡轮机功率,温度等,可以构造的特征包括lag信息,历史窗口内的统计特征,一阶差分等。
时间特征方面,包括星期几、小时等。
空间特征主要是和TurbID相关的信息,可以考虑把target encoding加进来,以及当前TurbID相邻的涡轮机信息。
其他特征例如做特征交叉,gbdt特征等。
赛题解析-模型
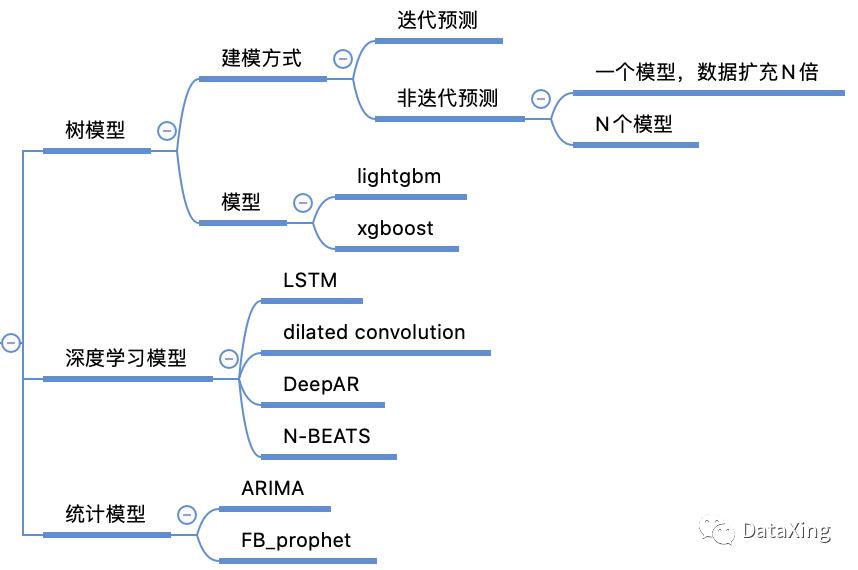
模型包括三大类。
树模型可以使用light和xgboost,这里常用的有两种建模方式。第一种是迭代预测,每次往前预测一步,然后把预测结果纳入进来构造特征,不断地往前迭代,达到预测多步的目的。第二种是非迭代预测,非迭代预测中也有两种建模方式:一是对数据扩充N倍(N表示多步预测的预测步长,本赛题N为168),这种方法可以在数据构造时加上一列,表示往前预测多少步;二是训练N个模型,每个模型各自负责往前预测多少步。
深度学习模型可以考虑的包括:LSTM、Dilated cnn、DeepAR、N-BEATS等。
统计模型常见的包括ARIMA以及facebook的prophet。
赛题解析-线下验证
线下验证尽量和测试集的构造方式保持一致。
例如训练集给定1-7天,预测未来42小时,最后24小时用来计算结果。我们可以将1-5天的数据拿来训练,预测未来42小时,最后24小时作为线下验证集。
赛题解析-模型融合
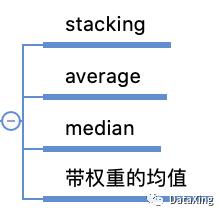
模型融合可以使用stacking以及加权平均、调和平均等方法。
赛题解析-后处理
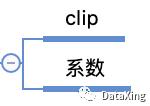
后处理可以查看一下预测结果是否超出了合理范围;以及使用一些魔法系数等。
baseline
我们的开源项目AutoX提供了本赛题的baseline代码:
https://github.com/4paradigm/AutoX/blob/master/autox/autox_ts/demo/kdd_cup_2022_autox.ipynb
预测结果示例
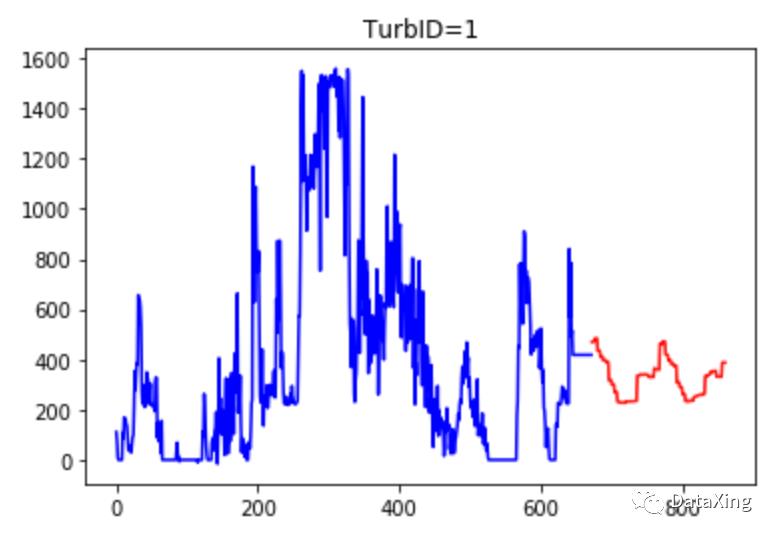
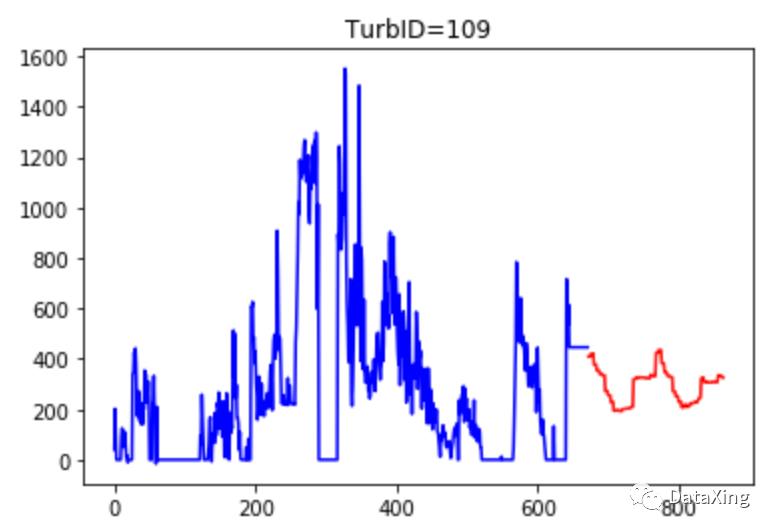
开源项目地址
https://github.com/4paradigm/AutoX
参赛选手可以关注下面公众号,后台回复“KDDCUP”即可进群。
以上是关于KDD Cup大赛Baseline&思路开源了!的主要内容,如果未能解决你的问题,请参考以下文章
7次KDD Cup&Kaggle冠军的经验分享:从多领域优化到AutoML框架