破解大厂面试动态算法题:字符串分解单词和二叉树统计
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了破解大厂面试动态算法题:字符串分解单词和二叉树统计相关的知识,希望对你有一定的参考价值。
我们看两道关于动态规划的算法题。第一题的题目如下:在某些语言例如拉丁语,泰语,他们没有空格将不同意思的单词分开,因此有些字处理软件在处理这样语言时,给定一串字符串,它必须有办法将他们分割成有意义的单词组合。我们有一个单词对照表,例如[“cat”, “cats”, “eat”, “mice”, “seat”], 同时给定一个字符串”catseatmic",那么根据单词对照表,它可以分解成句子如下:cat seat mice, 或者 cats eat mice ,请给出算法,在给定对照表和字符串后,将它分解成对应单词组合。
在此我们还是要走老套路,动态规划问题还是要将大问题分解成小问题,同时缓存小问题的解从而加快大问题的解决速度。面对这个问题我们的做法是,首先依次读入字符组合成单词,然后看看单词是否出现在对照表中,如果有,那么我们递归的解决剩下的字符串。例如给定字符串catseatmic,我们依次读入c,a,t,此时组合成单词cat,并发现它出现在对照表中,于是我们递归的处理剩下字符串seatmic,回到上一层,我们继续读入字符s,于是组合成单词cats,这时又发现它在对照表中,于是我们再递归的处理字符串eatmic,以此类推,在递归的处理余下字符串时,我们要在缓存中查找,给定字符串是否已经能分割成对应单词,如果缓存中没有答案,我们再进行处理,具体代码如下:
word_map =
word_map["cat"] = 1
word_map["cats"] = 1
word_map["eat"] = 1
word_map["mice"] = 1
word_map["seat"] = 1
cache_map =
def split_string_words(string, index):
if index >= len(string):
return [] , 0
if index in cache_map: #先从缓存中查找是否已经有答案
return cache_map[index]
word = ""
word_list = []
origin_index = index
while index < len(string):
word += string[index] #依次读入字符组合成单词
if word in word_map: #如果单词在对照表中,则递归处理余下字符串
sub_word_list, count = split_string_words(string,index + 1)
if sub_word_list is not None:
word_list.append(word)
word_list.extend(sub_word_list)
if origin_index in cache_map:
sequence, count = cache_map[origin_index]
if count == 1:
cache_map[origin_index] = ([sequence, word_list.copy()], count+1)
else:
sequence.append(word_list)
cache_map[origin_index] = (sequence, count + 1)
else:
cache_map[origin_index] = (word_list, 1)
word_list = []
index += 1
if origin_index in cache_map:
return cache_map[origin_index]
return None, 0
split_string_words("catseatmice", 0)
for key in cache_map:
print("split of words : ", cache_map[key])
上面代码运行后所得结果如下:
split of words : (['mice'], 1)
split of words : (['seat', 'mice'], 1)
split of words : ([['cat', 'seat', 'mice'], ['cats', 'eat', 'mice']], 2)
split of words : (['eat', 'mice'], 1)
算法复杂度是O(n^2),因为我们在第一次进入split_string_wordss时代码会依次遍历字符,一旦形成单词后,它会将剩下的字符串递归调用,在递归中又会对余下的字符进行遍历,如果上一层遍历了t个字符,那么在后面递归中就会遍历余下的n-t个字符,因此一旦最上层找到对应单词时,假设单词的长度为t,那么进入递归会继续遍历剩下n-t个字符,因此依次遍历长度为n,由于上层要遍历完所有字符,因此最上层遍历的字符数是n,于是总的遍历次数是O(n ^ 2)。
接下来我们看第二题。给定一个排序整形数组,计算他们所能形成的排序二叉树的个数,例如给定数组为[1,2,3],那么它们能组成的二叉树如下: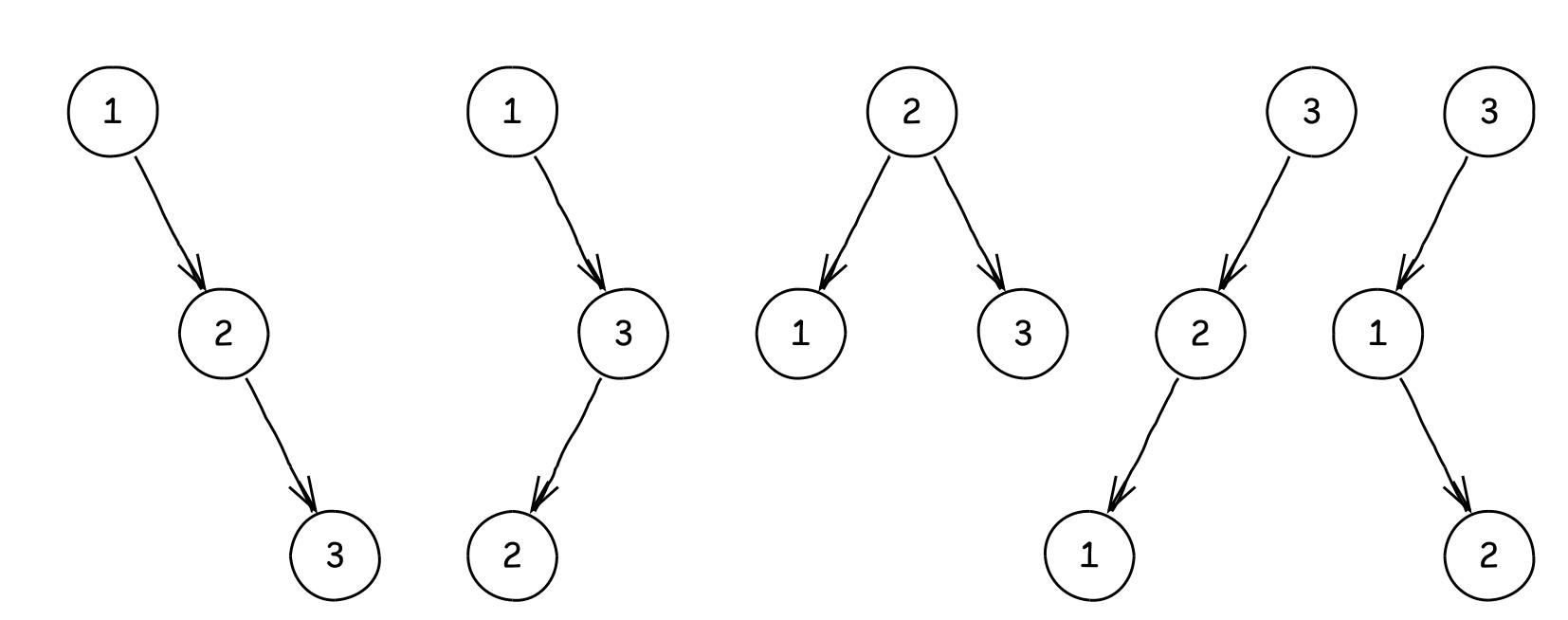
于是3个元素的数组对应二叉树的个数为5,给出算法计算数组元素为n时对应排序二叉树的个数。
这里我们首先需要注意的是,二叉树的个数跟数组元素有关,跟元素的大小无关,例如我们给定数组[4,5,6],那么形成排序二叉树的个数依然是5,我们只要把上面二叉树节点1,2,3分别换成,4,5,6即可。从上面示例我们也看到,不同二叉树有个特点,那就是根节点不同,数组中每个元素都可以成为跟节点。假设给定包含n个元素的数组a,我们取a[t]作为根节点,根据二叉排序树的特点,a[0…t-1]就形成左子树,因为他们的数组都比a[t]小,a[t+1…n-1]都形成右子树,因为他们的数值都比根节点大,于是我们就可以递归的计算左子树的个数L和右子树的个数R,那么以a[t]为根节点的二叉树个数就是L * R。
当然我们递归的计算左子树个数或者是右子树个数时,我们都先在缓存中判断一下,看看给定问题是否已经有解,如果没有我们再进行相应处理,由此给出代码如下:
cache_map =
def number_of_binary_tree(n :int):
if n == 0:
return 0
if n == 1 : #只有一个节点,那么二叉树只有1种
return 1
if n == 2:
return 2 #如果有两个节点,那么二叉树只有2种
if n in cache_map: #现在缓存中查找看看给定n个节点时答案是否存在
return cache_map[n]
tree_counts = 0
for root in range(1, n+1): #每个节点都能成为根节点
total_count_with_root = 0
if root == 1: #根节点为第一个元素时,它只能有右子树
total_count_with_root = number_of_binary_tree(n-1) #根节点为最小值点,因此只计算右子树
elif root == n: #根节点为最后一个元素,它只能有左子树
total_count_with_root = number_of_binary_tree(n-1) # 根节点为最大值点,因此只计算左子树
else: # 给定节点的下标为t, 那么前面t-1个元素形成左子树,右边n - t - 1个元素形成右子树
left_tree_count = number_of_binary_tree(root - 1) #计算左子树数量
right_tree_count = number_of_binary_tree(n - root) # 计算右子树的数量
total_count_with_root = left_tree_count * right_tree_count # 总共的二叉树数量
tree_counts += total_count_with_root
cache_map[n] = tree_counts
return tree_counts
node_num = 5
tree_counts = number_of_binary_tree(node_num)
print(f"number of binary tree with node count:node_num is :tree_counts")
上面代码运行后所得结果为:
number of binary tree with node count:5 is :42
也就是说当数组有5个节点时,能形成的排序二叉树有42个。我们看到number_of_binary_tree会有一个for循环,遍历输入数组所有元素,然后它会进入一个或两个递归,如果进入只有1个递归,也就是当前根节点是a[0]或者a[n-1],那么递归就会遍历余下的n-1个元素,如果是a[t],那么进入两个递归,第一个递归会遍历前t-1个元素,第二个递归会遍历n-t个元素,因此在for循环里面递归的次数为n,而for循环本身就得遍历n次,因此算法复杂度为O(n ^ 2)。
以上是关于破解大厂面试动态算法题:字符串分解单词和二叉树统计的主要内容,如果未能解决你的问题,请参考以下文章