数据挖掘导论——Python练习
Posted 上山打老虎D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘导论——Python练习相关的知识,希望对你有一定的参考价值。
实验2:Python练习
- 编写一个名为collatz()的函数,它有一个名为number的参数,如果输入的参数是质数,那么collatz()就打印出number,如果number不是质数,则打印3*number+1。
- 有两个磁盘文件test1.txt和test2.txt,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列,每类字母大写在前,小写在后), 输出到一个新文件test3.txt中。
- 某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下:每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换。
- 元素分类。给定如下的集合[11,33,22,44,55,66,77,88,99,90],创建一个字典,第一个键(“min”)对应的值是所有小于66的值,第二个键(“max”)对应的值是所有大于或等于66的值。输出该字典的所有键值对。
- 创建一个名为names的空列表,往里面按顺序添加 Lihua、Rain、Jack、Xiuxiu、Peiqi和Black共6个元素。再分别按照如下3个要求对names进行操作(每个操作不相关):
- 定义一个字典。其中键是字符串,描述清单中的物品,值是一个整型值,说明玩家有多少该物品。例如,字典值'rope': 1, 'torch': 6, 'gold coin': 42, 'dagger': 1, 'arrow': 12。写一个名为 displayInventory()的函数,参数是字典,打印输出物品个数和物品名称,并统计物品总数量。(输出格式参考下图)
- 输入包含数字和字母的字符串,判断:
编写一个名为collatz()的函数,它有一个名为number的参数,如果输入的参数是质数,那么collatz()就打印出number,如果number不是质数,则打印3*number+1。
| 输入 | 2 | 3 | 4 |
|---|---|---|---|
| 输出 | 2 | 3 | 13 |
代码
import math
def collatz(number):
if number <= 1:
return 3 * number + 1
if number == 2:
return number
i = 2
while i <= math.sqrt(number) + 1:
if number % i == 0:
return 3 * number + 1
i += 1
return number
分析
首先对负数以及小于等于1的数字进行特判,如果是小于等于1的数字则一定不是质数,直接返回三倍number+1的值即可。当输入为2时,为质数,直接返回即可。当输入其他数字时,利用循环,依次取2到number的平方根+1的值进行取余运算,利用遍历对是否存在非1以及其本身的其他因子进行判断。如果存在,则直接返回三倍number+1的值。若穷举后发现不存在,则返回原值即可。
测试
当输入为2时:
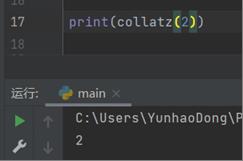
当输入为3时:

当输入为4时:
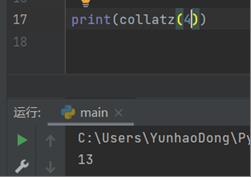
当输入为8时:

当输入为19时:
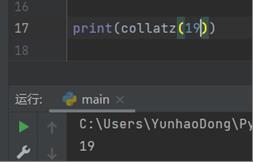
有两个磁盘文件test1.txt和test2.txt,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列,每类字母大写在前,小写在后), 输出到一个新文件test3.txt中。
示例:
注:运行以上程序前,你需要在脚本执行的目录下创建 test1.txt、test2.txt 文件
test1.txt : AbCdEf
test2.txt: HIiJKaBcDeF
test3.txt: AaBbCcDdEeFfHIiJK
代码
with open('test1.txt', 'r+') as f:
tempString = f.read()
with open('test2.txt', 'r+') as f:
tempString += f.read()
print(tempString)
temp = list(tempString)
temp.sort(key=lambda x: 2 * ord(x) if x.isupper() else 2 * ord(x.upper()) + 1)
tempString = "".join(temp)
f = open("test3.txt", "w")
f.write(tempString)
print(tempString)
分析
首先利用文件流读取两个文件并合并成一个字符串,然后将其转成列表,再利用sort函数结合ASCII码,对于大写字母,排序的键为ASCII码的二倍,对于小写字母,排序的键为对应大写字母ASCII码的二倍加一,从而将小写字母插入大写字母中。排序结束后再利用join将列表转换成字符串。最后利用文件流,输出到文件中即可。
测试
Test1.txt:
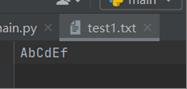
Test2.txt
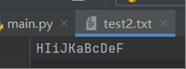
Test3.txt
某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下:每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换。
示例:
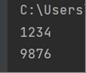
输入:1234
输出:9876
代码
def encrypt(num):
res = int(num / 1000 + 5) % 10
res += int(num % 1000 / 100 + 5) % 10 * 10
res += int(num % 100 / 10 + 5) % 10 * 100
res += int(num % 10 + 5) % 10 * 1000
return res
print(encrypt(1234))
分析
对于个位数,新数字的个位数即为原数字的千位数,因此对原数字的千位数加五之后对10取模即可
对于十位数,新数字的十位数即为原数字的百位数,因此对原数字的百位数加五之后对10取模即可
对于百位数,新数字的百位数即为原数字的十位数,因此对原数字的十位数加五之后对10取模即可
对于千位数,新数字的千位数即为原数字的个位数,因此对原数字的个位数加五之后对10取模即可
测试
加密前:1234
加密后:9876
元素分类。给定如下的集合[11,33,22,44,55,66,77,88,99,90],创建一个字典,第一个键(“min”)对应的值是所有小于66的值,第二个键(“max”)对应的值是所有大于或等于66的值。输出该字典的所有键值对。
代码
if __name__ == '__main__':
num = [11, 33, 22, 44, 55, 66, 77, 88, 99, 90]
dic = 'min': [], 'max': []
for i in num:
if i < 66:
dic['min'].append(i)
else:
dic['max'].append(i)
print(dic)
分析
首先创建元素列表以及目标字典。利用for循环遍历列表,对于列表中的每个数字,当其小于66时,加入到以min为键的字典中,反之则加入到以max为键的字典中。最后输出结果即可
测试

创建一个名为names的空列表,往里面按顺序添加 Lihua、Rain、Jack、Xiuxiu、Peiqi和Black共6个元素。再分别按照如下3个要求对names进行操作(每个操作不相关):
- 往names列表里Black前面插入一个Blue,后面插入White,输出names列表;
- 把names列表中Xiuxiu的名字替换成“秀秀”,并输出names列表;
- 创建新列表[1,2,3,4,2,5,6,2],将新列表元素追加到names列表末尾,并输出names列表;取出names列表中索引2-10的元素,步长为2,打印所取出的元素。
代码
if __name__ == '__main__':
names = ['Lihua', 'Rain', 'Jack', 'Xiuxiu', 'Peiqi', 'Black']
names.insert(-1, 'Blue')
names.append('White')
print(names)
if __name__ == '__main__':
names = ['Lihua', 'Rain', 'Jack', 'Xiuxiu', 'Peiqi', 'Black']
names[names.index('Xiuxiu')] = '秀秀'
print(names)
if __name__ == '__main__':
names = ['Lihua', 'Rain', 'Jack', 'Xiuxiu', 'Peiqi', 'Black']
newList = [1, 2, 3, 4, 2, 5, 6, 2]
names.extend(newList)
print(names)
print(names[2:11:2])
分析
通过利用insert在倒数第二个位置插入’Blue’,通过append在末尾加入’White’
通过利用index函数获取对应内容的下标值之后,再直接进行读写。
通过利用extend函数完成两个列表间的合并操作。利用切片对列表进行切片,从而获取以2开始,步长为2的序列
测试



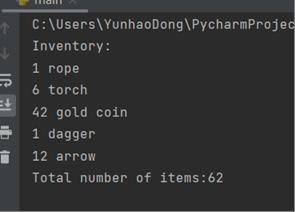
定义一个字典。其中键是字符串,描述清单中的物品,值是一个整型值,说明玩家有多少该物品。例如,字典值‘rope’: 1, ‘torch’: 6, ‘gold coin’: 42, ‘dagger’: 1, ‘arrow’: 12。写一个名为 displayInventory()的函数,参数是字典,打印输出物品个数和物品名称,并统计物品总数量。(输出格式参考下图)

代码
def displayInventory(dir):
print('Inventory:')
temp = 0
for i in dir.keys():
print(str(dir[i]) + " " + i)
temp += dir[i]
print('Total number of items:' + str(temp))
if __name__ == '__main__':
dir = 'rope': 1, 'torch': 6, 'gold coin': 42, 'dagger': 1, 'arrow': 12
displayInventory(dir)
分析
首先输出“Inventory:”,然后利用for循环遍历整个字典并累加。最后将累加结果输出。
测试
输入包含数字和字母的字符串,判断:
- 该串中是否两类字符[数字和英文字符]都包含?
- 每种字符都唯一?
若两个条件都满足返回”TURE”,否则返回”FALSE”。
示例:
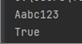
输入: Aabc123 输出:TURE
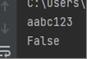
输入: aabc123 输出:FALSE
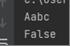
输入:Aabc 输出:FALSE
代码
import re
def judge(string0):
if len(string0) != len(set(string0)):
return False
if re.compile(r"[0-9]").findall(string0) and re.compile(r"[a-zA-Z]").findall(string0):
return True
else:
return False
分析
首先利用set,将字符串转化为字符串集合。由于集合的键值元素特性,集合长度即为字符串中拥有的不同字符数,因此当集合长度与字符串长度相等时,字符串每种字符均唯一。
其次,利用正则表达式检索数字与英文字符,当两个正则表达式都匹配时,即说明字符串中两类字符都包含。
测试
以上是关于数据挖掘导论——Python练习的主要内容,如果未能解决你的问题,请参考以下文章