一个python爬虫工程师参加博主之星之后,必做的事情
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个python爬虫工程师参加博主之星之后,必做的事情相关的知识,希望对你有一定的参考价值。

51CTO博主之星评选来临,橡皮擦首次进入前100,欢迎大家来投票。
51CTO 博主之星竞选人 梦想橡皮擦 申请票票票票~~~啦啦
第一步:打开 https://blog.51cto.com/blog-contest/index#part2
第二步:搜索 33
第三步:点击全部投给博主橡皮擦3票
希望未来我的博客能对大家有所帮助。
需求评审
本次的需求如下所示,官网提供的页面中,前100是随机出现的,无法获取大家的投票排名,基于此,爬虫的需求就诞生了
我们将通过 Python 爬虫获取页面投票数据,实现及时排名程序。
实现逻辑如下所示:
- 爬取所有用户数据
- 入库
- 展示
数据爬虫
首先查询API接口地址与数据,分别如下所示:
接口地址与规则
https://blog.51cto.com/blog-contest/get-blogger-list?listtype=3&page=1&type=0&keywords=
https://blog.51cto.com/blog-contest/get-blogger-list?listtype=3&page=2&type=0&keywords=
……
https://blog.51cto.com/blog-contest/get-blogger-list?listtype=3&page=7&type=0&keywords=
数据格式如下所示:
"status": 1,
"msg": "获取成功",
"data":
"data": [
"id": "001",
"user_id": "3002256",
"user_name": "三杯水",
"poll": "5",
"domain": "https://blog.51cto.com/jerrymin",
"headUrl": "https://头像.jpg"
,
"id": "002",
"user_id": "14797794",
"user_name": "江晓龙的技术博客",
"poll": "23",
"domain": "https://blog.51cto.com/jiangxl",
"headUrl": "https://头像"
,
以上数据清理完毕之后,就可以编写相关源码
import requests
import time
def get_data(page, now):
res = requests.get(f'https://blog.51cto.com/blog-contest/get-blogger-list?listtype=3&page=page&type=0&keywords=')
data = res.json()['data']['data']
for item in data:
id = item["id"]
user_id = item["user_id"]
user_name = item["user_name"]
poll = item["poll"]
domain = item["domain"]
print(id, user_id, user_name, poll, domain)
if __name__ == '__main__':
now = int(time.time())
for i in range(1, 8):
get_data(i, now)
我们调用了一下对应的接口,并且传递对应参数到接口中,对返回的JSON进行了解析,其中额外增加了一个 JSON 参数,用于后续控制数据筛选范围。
建立表结构
在 mysql 中创建一张如下格式的表格,用于存储采集到的数据,其中 time 字段仅获取到秒位。
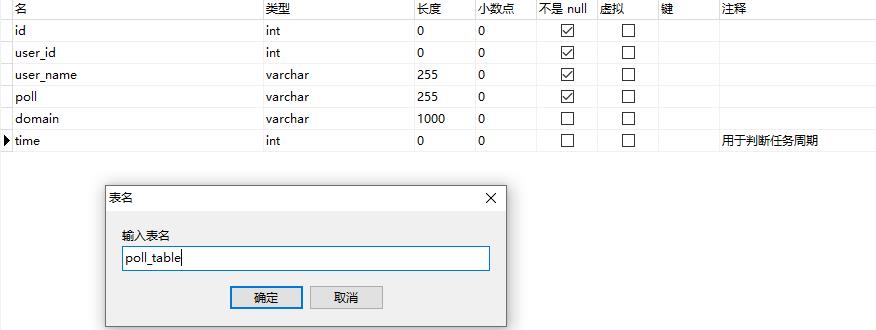
表结构创建完毕,就可以运行我们的代码,然后插入结果数据了。
def insert_table(id, user_id, user_name, poll, domain, now):
db = pymysql.connect(host='localhost',
user='root',
password='root',
database='51cto_rank')
cursor = db.cursor()
sql = """
insert into poll_table(id, user_id, user_name, poll, domain,time)
values(%s,%s,%s,%s,%s,%s);"""
try:
cursor.execute(sql, (id, user_id, user_name, poll, domain, now))
db.commit()
except Exception as e:
# print(content)
print(e)
db.rollback()
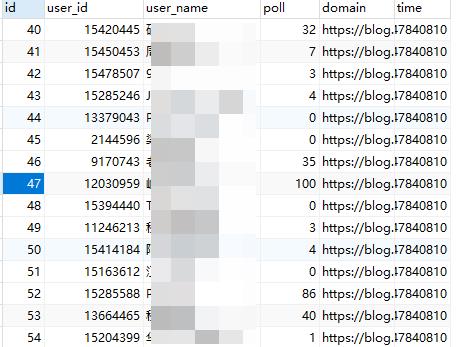
运行结果如下所示:
前台页面实现
下面就是最终步骤,用 Python Flask 框架实现数据的前台渲染,由于数据比较简单,直接使用 bootstrap 框架落地实现即可
Flask 框架的学习与使用,可以参考橡皮擦的其它博客,核心的代码如下所示:
# 导入Flask类
from flask import Flask
from flask import request
from flask import render_template
import pymysql
# 实例化,可视为固定格式
app = Flask(__name__)
def get_data():
db = pymysql.connect(host='localhost',
user='root',
password='root',
database='51cto_rank')
cursor = db.cursor()
sql = """select id, user_id, user_name, poll, domain, time from poll_table order by time desc LIMIT 100;"""
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
return results
except Exception as e:
# print(content)
print(e)
# route()方法用于设定路由;
@app.route('/rank.html', methods=['GET'])
def hello_world():
if request.method == 'GET':
data = get_data()
return render_template('rank.html', data=data)
if __name__ == '__main__':
# app.run(host, port, debug, options)
# 默认值:host="127.0.0.1", port=5000, debug=False
app.run(host="0.0.0.0", port=5000)
其中 rank.html 页面如下所示,其中 bootstrap 建议使用 cdn 加速地址,这里我直接引用的官方地址
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>51CTO博主之星排名</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/css/bootstrap.min.css" integrity="sha384-HSMxcRTRxnN+Bdg0JdbxYKrThecOKuH5zCYotlSAcp1+c8xmyTe9GYg1l9a69psu" crossorigin="anonymous">
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
</head>
<body>
<table class="table">
<tr>
<th>用户名</th>
<th>票数</th>
<th>个人主页</th>
</tr>
% for item in data %
<tr>
<td>item[2]</td>
<td>item[3]</td>
<td>item[4]</td>
</tr>
% endfor %
</table>
</body>
</html>
上述代码的排序存在一定问题,我们在按照票数进行一下倒序,代码如下:
select id, user_id, user_name, poll, domain,time from (
select id, user_id, user_name, poll, domain,time from poll_table order by time desc LIMIT 100 )
as f ORDER BY f.poll desc
除此之外,还可以根据序号,将数据进行分组,对应的就是上述 id 值。
- 网络运维:1~30
- 前后端开发:31~70
- IT新技术:71~100
发布我们的程序
找一台闲置的服务器(广告位招商),部署 Python 代码,注意在云端安全组放开指定端口,这里我直接使用默认的 80 端口。
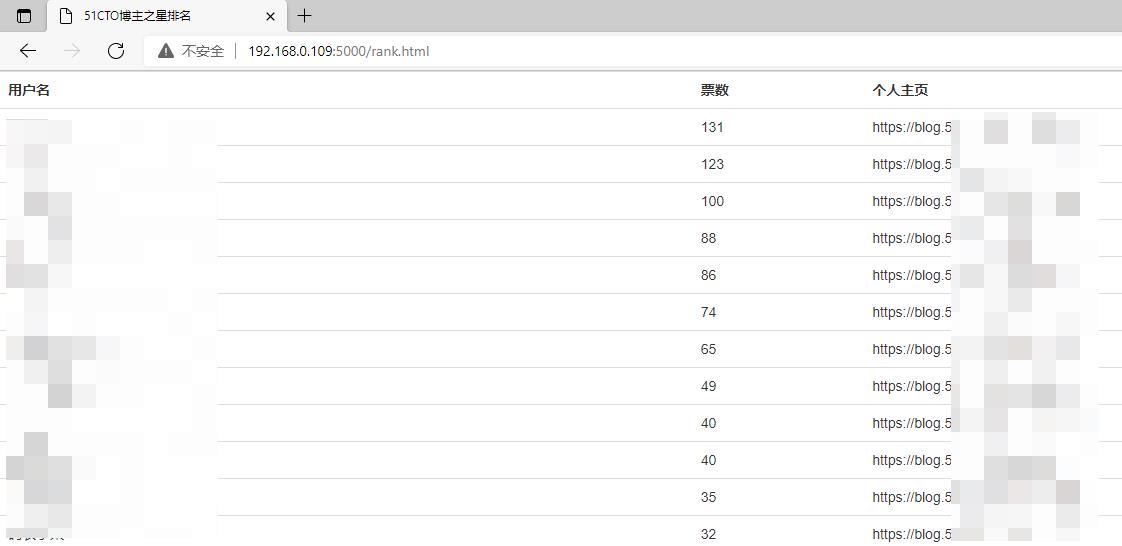
展示一下服务器端的模块配置
打开如下IP地址(没有绑定域名,因为域名没备案)
等你投票
51CTO博主之星评选来临,橡皮擦首次进入前100,欢迎大家来投票。
51CTO 博主之星竞选人 梦想橡皮擦 申请票票票票~~~啦啦
第一步:打开 https://blog.51cto.com/blog-contest/index#part2
第二步:搜索 33
第三步:点击全部投给博主橡皮擦3票
希望未来我的博客能对大家有所帮助。
记录时间
2022年度 Flag,写作的 588 / 1024 篇。
可以关注我,点赞我、评论我、收藏我啦。
更多精彩
以上是关于一个python爬虫工程师参加博主之星之后,必做的事情的主要内容,如果未能解决你的问题,请参考以下文章