如何用python把返回的html提取相应的内容到excel
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用python把返回的html提取相应的内容到excel相关的知识,希望对你有一定的参考价值。
解决方法:
正则提取出多个列表,然后利用 Pandas 的 DataFrame 数据类型写入 excel,具体格式你自己安排,这里给出个基本示例:
text = """<td align="center">1</td><td align="center">产品</td>
<td align="center">red</td>
<td align="center">单价</td>
<td align="center">价格</td>
<td align="center">备注</td>
<td align="center">2</td>
<td align="center">产品</td>
<td align="center">red</td>
<td align="center">单价</td>
<td align="center">价格</td>
<td align="center">备注</td>import pandas as pd
import re
p = re.compile(\'>(\\S+)</td>\')
q = p.findall(text)
table = pd.read_excel(r\'D:\\test.xlsx\')
table[\'your title\'] = pd.Series(q)
table.to_excel(r\'D:\\test.xlsx\')
结果:
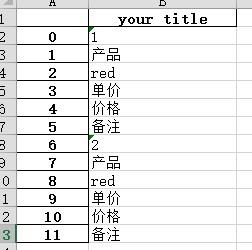
soup=BeaitifulSoup(html,'html.parser')
要找到某各元素使用find_all方法就行
for div in soup.find_all('div'):
但是经常会遇到网站有反爬的设置,比如子结点中含有换行符,只要写个函数去掉子结点间的换行符就行
以上是关于如何用python把返回的html提取相应的内容到excel的主要内容,如果未能解决你的问题,请参考以下文章