PyTorch学习笔记 8. 实现线性回归模型
Posted 编程圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch学习笔记 8. 实现线性回归模型相关的知识,希望对你有一定的参考价值。
PyTorch学习笔记 8. 实现线性回归模型

一、 回归的概念
1. 概念
回归(Linear Regression)是一种基本的统计学习方法,它用于建立两个或多个变量之间的关系。
- 线性回归假设自变量(输入)和因变量(输出)之间是线性关系,即输出值可以通过一条直线(或超平面)来表示输入值的函数。
- 逻辑回归拟合的结果是非线性关系 , 也称为广义线性回归。
回归问题与分类问题的区别:
- 回归问题中,预测值是连续值;
- 分类问题中,预测值是离散值。
2. 目标
线性回归的目标是找到一条最佳拟合直线,以最小化预测值与实际值之间的差距(误差)。
3. 应用
线性回归在机器学习和数据分析中被广泛使用,它可以用于预测、分类和特征选择等任务。它的应用领域包括金融、经济学、社会科学、医学和工程学等领域。
4. 训练线性回归的步骤
- 定义网络模型:包括神经网络的层数、每一层的神经元数、激活函数等。
- 定义损失函数:根据问题的性质,选择适合的损失函数。
- 定义优化器:选择合适的优化器来更新神经网络的参数,如SGD、Adam等。
- 遍历训练数据:对于每个训练样本,进行前向传播,计算损失函数,并进行反向传播求梯度。
- 更新网络参数:根据梯度信息和优化器的选择,更新神经网络的参数。
- 重复上述步骤,直到达到预设的停止条件,如训练次数达到上限、损失函数下降到一定程度等。
训练的过程中要避免过拟合现象,可采用一些方法如早停法、正则化等来缓解。
二、数据集
1. 构造数据集
本例定义一个 y = 5 ∗ x + 2 y=5*x+2 y=5∗x+2 的线性函数,并适当添加噪声点:
np.random.seed(0)
x_train = np.random.rand(100, 1)
y_train = 5 * x_train + 2 + 0.2 * np.random.randn(100, 1)
x_test = np.random.rand(20, 1)
y_test = 5 * x_test + 2 + 0.2 * np.random.randn(20, 1)
2. 把数据集转为 pytorch 使用的张量
x_train_tensor = torch.from_numpy(x_train).float()
y_train_tensor = torch.from_numpy(y_train).float()
x_test_tensor = torch.from_numpy(x_test).float()
y_test_tensor = torch.from_numpy(y_test).float()
三、模型
1. 模型定义
为了实现线性回归,我们定义只有一个层的神经网络LinearRegression,在类中定义了一个全连接层linear,这个层的输入和输出都是1维的。
在前向传播方法中,输入x被传入全连接层中进行计算,得到模型的输出out,然后将其返回。
模型的输出out就是输入x的线性变换结果,具体的计算公式为 y = W x + b y = Wx + b y=Wx+b,其中 W W W是全连接层的权重, b b b是偏置,由于输入和输出都是1维的,因此 W W W也是一个1维的向量, b b b是一个标量。
# 定义模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
2. 损失函数
线性回归使用均方误差损失函数。
均方误差损失函数,又称为平方损失函数,是一种用于回归问题的损失函数,计算预测值与真实值之间差异的平方和。在训练过程中,通过不断调整模型参数,最小化损失函数,使得模型能够更好地拟合训练数据。
均方误差损失函数容易受到噪声的影响,不适用于离群点数据。
criterion = nn.MSELoss()
3. 优化器
这里使用了 torch.optim.SGD优化器,即随机梯度下降优化器(Stochastic Gradient Descent Optimizer),其通过对模型参数的梯度进行迭代更新,来最小化损失函数。
SGD是深度学习中最常用的优化器之一,也是最基础的优化器之一。
lr 表示学习率,它控制了优化器每次更新参数的步长大小。
- 较小的学习率会使优化器收敛缓慢,但是可能会得到更准确的结果;
- 较大的学习率会使优化器收敛较快,但是可能会错过最优解。
选择学习率的大小需要根据具体问题进行调整。在下面的代码中,学习率被设置为 0.01,这个值是一个经验值,通常需要根据实际情况进行调整。
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
四、使用模型
1. 训练
这里重点是反向传播。
通过计算损失函数对模型参数的梯度,可以确定当前参数下损失函数变化最快的方向,然后将参数朝着这个方向更新,以期望能够使损失函数的值减小。
计算反向传播的一般步骤是:
- 通过前向传播计算模型输出;
- 计算损失函数;
- 计算损失函数对模型参数的梯度;
- 使用计算得到的梯度对模型参数进行更新。
在每次计算梯度时,要注意梯度的值会累加到模型参数的梯度值中,因此需要在每个batch或每个epoch开始之前将模型参数的梯度值清零。如果不清零,梯度值会一直累加并影响到后续梯度的计算,导致训练出现问题。
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
y_pred = model(x_train_tensor)
# 计算损失
loss = criterion(y_pred, y_train_tensor)
# 反向传播和优化
# 清除所有模型参数的梯度值
optimizer.zero_grad()
# 计算损失函数对模型参数的梯度
loss.backward()
# 根据计算出的梯度更新模型参数
optimizer.step()
# 每隔50个epoch输出一次信息
if (epoch + 1) % 50 == 0:
print('Epoch[/], loss: :.6f'.format(epoch + 1, num_epochs, loss.item()))
2. 测试
查看损失:
在PyTorch中,损失函数计算的结果一般会返回一个tensor,这个tensor里面存储的是所有样本的损失值,如果要在训练过程中及时查看损失函数的值,需要将这个tensor转换成Python标量(即一个float数值),通过调用item()方法实现。这样得到的就是单个数值,便于进行打印输出、可视化等操作。
# 测试模型
model.eval()
with torch.no_grad():
y_pred_train = model(x_train_tensor)
y_pred_test = model(x_test_tensor)
train_loss = criterion(y_pred_train, y_train_tensor).item()
test_loss = criterion(y_pred_test, y_test_tensor).item()
print(f'Train loss: train_loss:.6f, Test loss: test_loss:.6f')
3. 预测
# 预测结果
x_new_tensor = torch.Tensor([[0.2], [0.4], [0.6]])
y_new_tensor = model(x_new_tensor).detach().numpy()
print(f'Prediction for x_new_tensor: y_new_tensor')
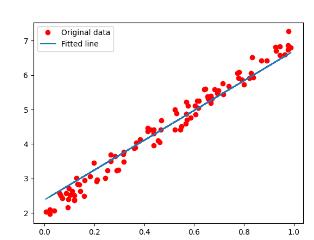
4. 可视化
可视化时,把预测结果转换成 numpy 数组,并且使用 detach() 方法将其与计算图分离,即使其不参与反向传播;最后使用matplotlib绘制函数。
# 可视化结果
model.eval()
y_pred = model(x_train_tensor).detach().numpy()
plt.plot(x_train_tensor.numpy(), y_train_tensor.numpy(), 'ro', label='Original data')
plt.plot(x_train_tensor.numpy(), y_pred, label='Fitted line')
plt.legend()
plt.show()
五、完整代码实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0)
x_train = np.random.rand(100, 1)
y_train = 5 * x_train + 2 + 0.2 * np.random.randn(100, 1)
x_test = np.random.rand(20, 1)
y_test = 5 * x_test + 2 + 0.2 * np.random.randn(20, 1)
# 转换为张量
x_train_tensor = torch.from_numpy(x_train).float()
y_train_tensor = torch.from_numpy(y_train).float()
x_test_tensor = torch.from_numpy(x_test).float()
y_test_tensor = torch.from_numpy(y_test).float()
# 定义模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
model = LinearRegression()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
y_pred = model(x_train_tensor)
# 计算损失
loss = criterion(y_pred, y_train_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每隔50个epoch输出一次信息
if (epoch + 1) % 50 == 0:
print('Epoch[/], loss: :.6f'.format(epoch + 1, num_epochs, loss.item()))
# 测试模型
model.eval()
with torch.no_grad():
y_pred_train = model(x_train_tensor)
y_pred_test = model(x_test_tensor)
train_loss = criterion(y_pred_train, y_train_tensor).item()
test_loss = criterion(y_pred_test, y_test_tensor).item()
print(f'Train loss: train_loss:.6f, Test loss: test_loss:.6f')
# 预测结果
x_new_tensor = torch.Tensor([[0.2], [0.4], [0.6]])
y_new_tensor = model(x_new_tensor).detach().numpy()
print(f'Prediction for x_new_tensor: y_new_tensor')
# 可视化结果
model.eval()
y_pred = model(x_train_tensor).detach().numpy()
plt.plot(x_train_tensor.numpy(), y_train_tensor.numpy(), 'ro', label='Original data')
plt.plot(x_train_tensor.numpy(), y_pred, label='Fitted line')
plt.legend()
plt.show()
可视化结果:
以上是关于PyTorch学习笔记 8. 实现线性回归模型的主要内容,如果未能解决你的问题,请参考以下文章