模块A:大数据平台搭建(容器环境)
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模块A:大数据平台搭建(容器环境)相关的知识,希望对你有一定的参考价值。
文章目录
- 一、环境说明
- 二、在ubuntu节点上安装Docker
- 三、实验所需安装包
- 任务一:Hadoop 完全分布式安装配置
- 任务二:Spark on Yarn安装配置
- 任务三:Flink on Yarn安装配置
一、环境说明
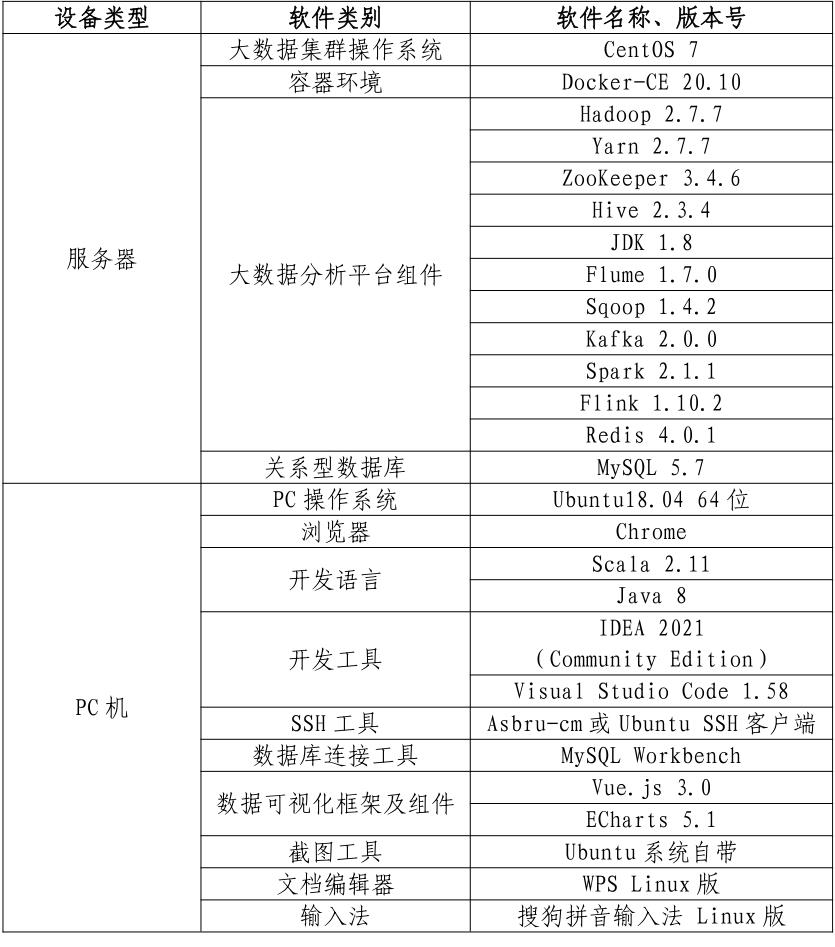
- 服务端登录地址详见各模块服务端说明。
- 补充说明:宿主机可通过Asbru工具或SSH客户端进行SSH访问;相关软件安装包在宿主机的/opt目录下,请选择对应的安装包进行安装,用不到的可忽略;所有模块中应用命令必须采用绝对路径。
- 从本地仓库中拉取镜像,并启动3个容器
进入Master节点的方式为docker exec –it master /bin/bash
进入Slave1节点的方式为docker exec –it slave1 /bin/bash
进入Slave2节点的方式为docker exec –it slave2 /bin/bash - 同时将/opt目录下的所有安装包移动到3个容器节点中。

二、在ubuntu节点上安装Docker
(一)安装必要系统工具
- 执行命令:
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common

(二)安装GPG证书
- 执行命令:
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -

(三)写入软件源信息
- 执行命令:
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"

(四)更新apt源
- 执行命令:
sudo apt-get -y update

(五)查看Docker-CE全部版本
- 执行命令:
apt-cache madison docker-ce,目前最新版本是20.10.13~3-0~ubuntu-bionic

(六)安装Docker-CE
- 执行命令:
sudo apt-get -y install docker-ce=20.10.13~3-0~ubuntu-bionic

- 执行命令:
sudo apt-get -y install docker-ce

(七)设置开机自动启动
- 执行命令:
sudo systemctl enable docker

(八) 启动Docker服务
- 执行命令:
systemctl start docker

(九) 测试Docker是否安装成功
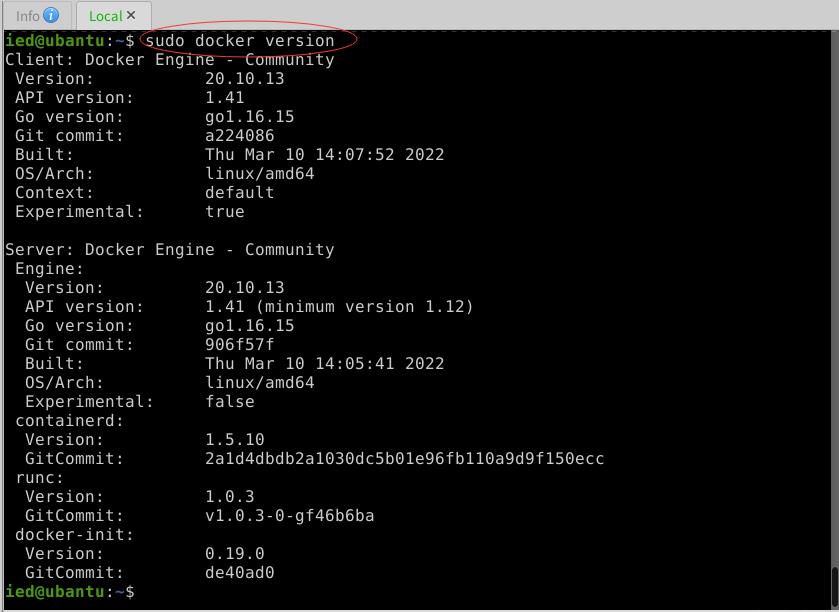
1、查看Docker版本号
- 执行命令:docker version

- 权限不够,执行命令:
sudo docker version
2、运行hello-world程序
- 执行命令:
sudo docker run hello-world
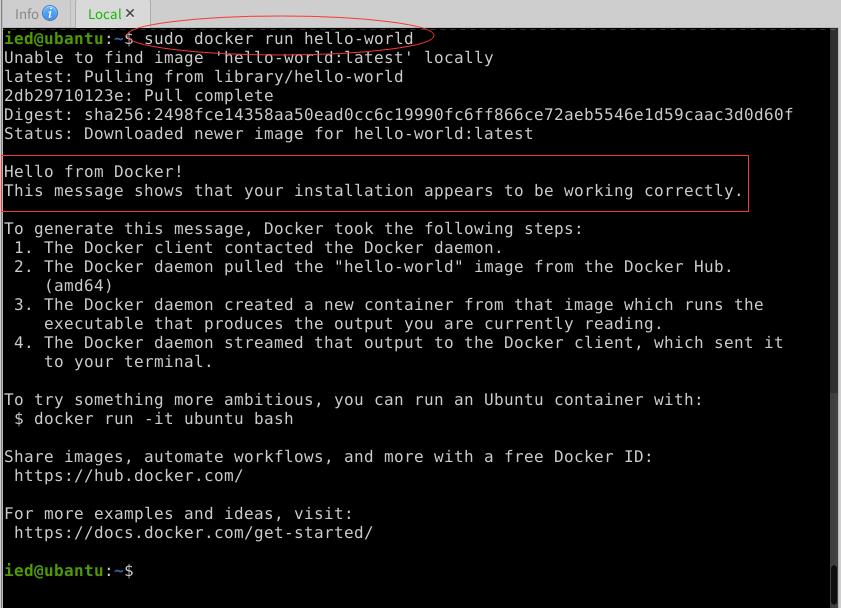
- 收到
Hello from Docker这条消息,就表明Docker安装成功~
三、实验所需安装包
- 实验所需安装包在Master节点的
/chinaskills目录

任务一:Hadoop 完全分布式安装配置
(一)任务要求
- 本环节需要使用
root用户完成相关配置,安装Hadoop需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
- 将Master节点JDK安装包解压并移动到
/usr/java路径(若路径不存在,则需新建),将命令复制并粘贴至对应报告中; - 修改
/etc/profile文件,设置JDK环境变量,配置完毕后在Master节点分别执行“java”和“javac”命令,将命令行执行结果分别截图并粘贴至对应报告中; - 请完成host相关配置,将三个节点分别命名为master、slave1、slave2,并做免密登录,使用绝对路径从master复制JDK解压后的安装文件到slave1、slave2节点,并配置相关环境变量,将全部复制命令复制并粘贴至对应报告中;
- 在Master将Hadoop解压到/opt目录下,并将解压包分发至slave1与slave2中,配置好相关环境,初始化Hadoop环境namenode,将初始化命令及初始化结果复制粘贴至对应报告中;
- 启动hadoop集群,查看master节点jps进程,将查看结果复制粘贴至对应报告中。
(二)完成任务
1、将JDK解压到指定位置
- 执行命令:
mkdir /usr/java,创建`/usr/java```目录 - 执行命令:
tar -zxvf /chinaskills/jdk-8u162-linux-x64.tar.gz -C /usr/java,将JDK安装包解压到/usr/java目录
2、配置Java环境变量
- 执行命令:
vim /etc/profile

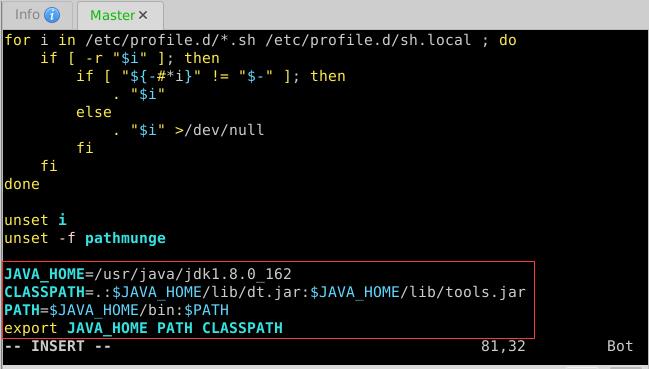
JAVA_HOME=/usr/java/jdk1.8.0_162
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH CLASSPATH
- 存盘退出,执行
source /etc/profile,让环境配置生效
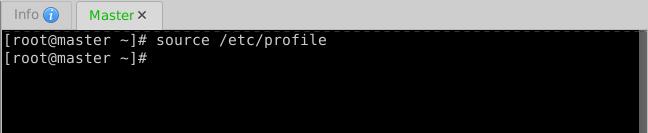
- 执行
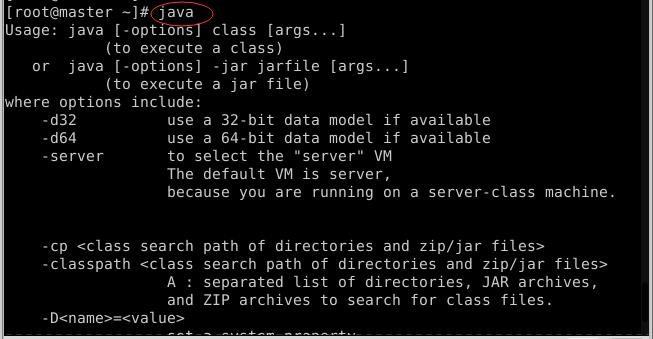
javac

- 执行
java
3、三个节点相互免密登录,分发JDK到Slave1与Slave2
(1)设置三个节点主机名:master、slave1和slave2
- 在Master节点上执行命令:
hostnamectl set-hostname master

- 在Slave1节点上执行命令:
hostnamectl set-hostname slave1

- 在Slave2节点上执行命令:
hostnamectl set-hostname slave2

(2)做IP地址与主机名映射
- 编辑
/etc/hosts文件,添加三个节点的IP地址与主机名映射


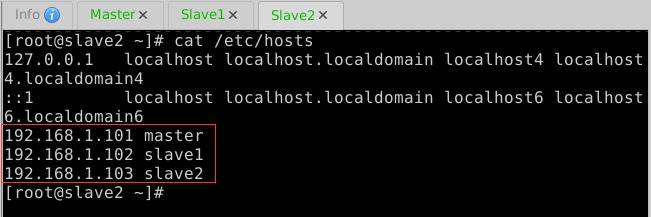
(3)Master节点免密登录Master、Slave1与Slave2
- 生成密钥对
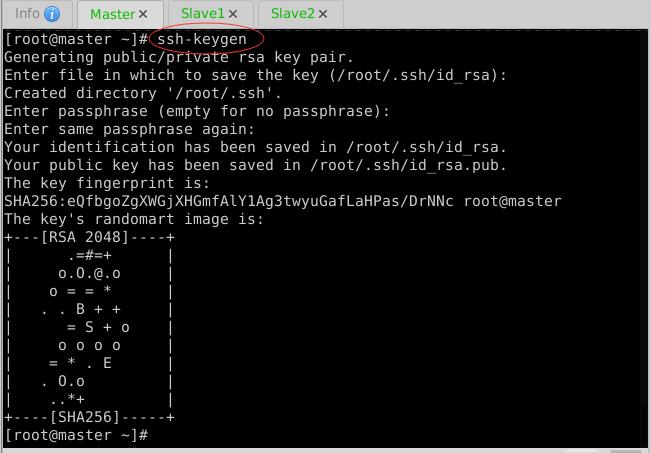
- 拷贝公钥到Master节点

- 拷贝公钥到Slave1节点
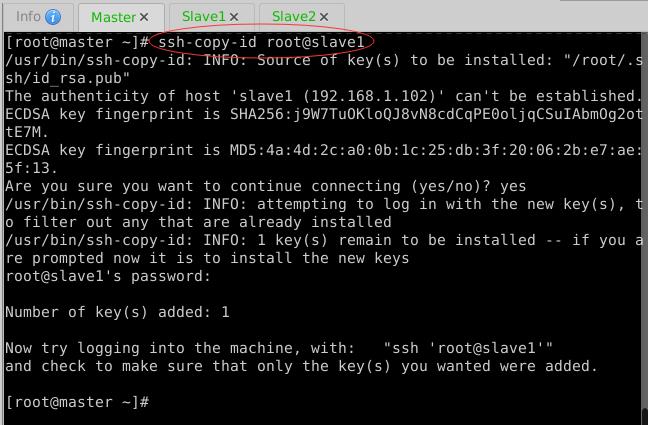
- 拷贝公钥到Slave2节点

(4)Slave1节点免密登录Master、Slave1与Slave2
- 生成密钥对

- 拷贝公钥到Master节点
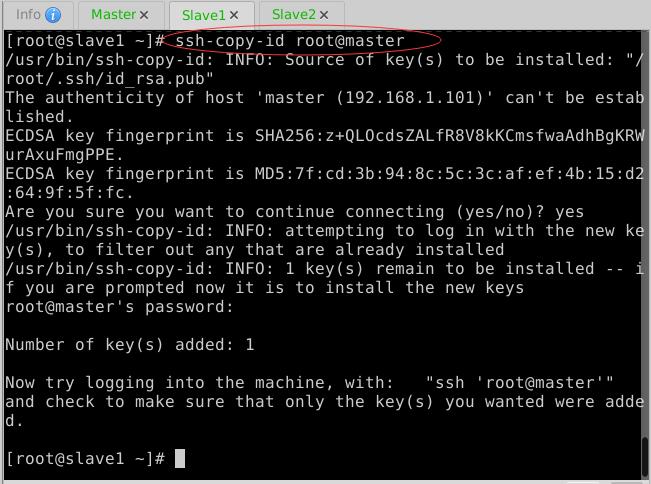
- 拷贝公钥到Slave1节点

- 拷贝公钥到Slave2节点

(5)Slave2节点免密登录Master、Slave1与Slave2
- 生成密钥对

- 拷贝公钥到Master节点
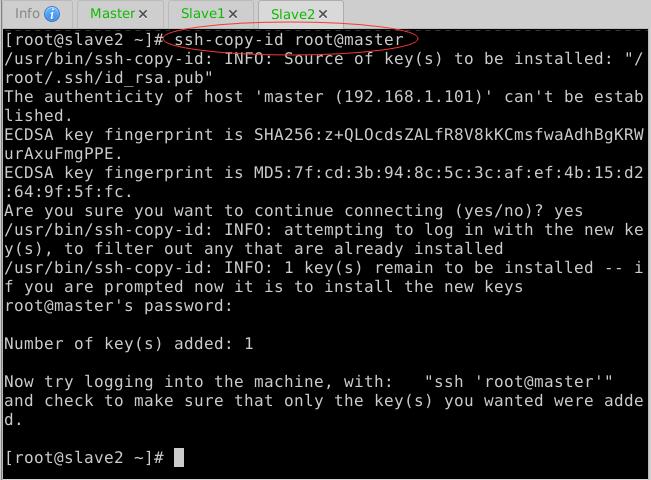
- 拷贝公钥到Slave1节点
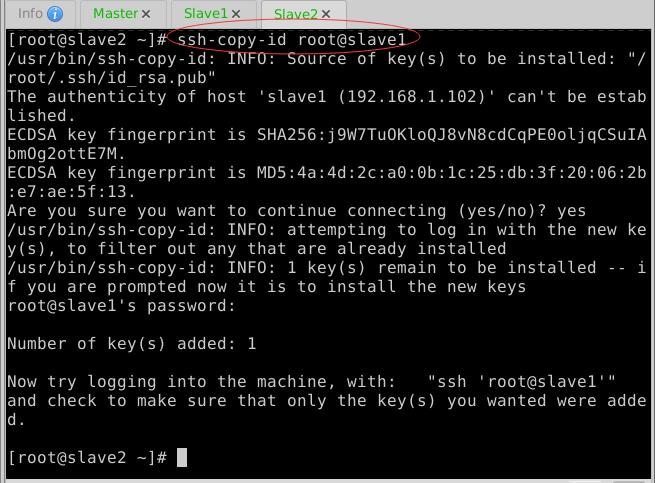
- 拷贝公钥到Slave2节点

(6)将Master节点上安装的JDK分发到Slave1与Slave2
- 在Slave1与Slave2节点上创建
/usr/java目录


- 执行命令:
scp -r $JAVA_HOME root@slave1:$JAVA_HOME

- 执行命令:
scp -r $JAVA_HOME root@slave2:$JAVA_HOME

(7)将Master节点上的环境配置文件分发到Slave1与Slave2
- 执行命令:
scp /etc/profile root@slave1:/etc/profile

- 执行命令:
scp /etc/profile root@slave2:/etc/profile
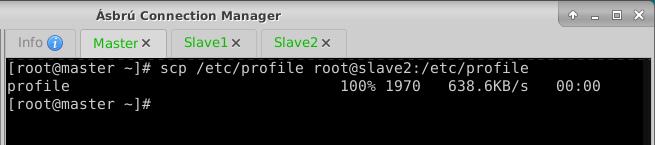
(8)在Slave1与Slave2让环境配置生效
- 在Slave1节点上执行命令:
source /etc/profile

- 在Slave2节点上执行命令:
source /etc/profile

4、安装配置Hadoop分布式环境
(1)在master虚拟机上安装配置hadoop
A. 将hadoop安装包解压到指定位置
- 执行命令:
tar -zxvf /chinaskills/hadoop-2.7.7.tar.gz -C /opt

B. 配置hadoop环境变量
- 执行命令:
vim /etc/profile

JAVA_HOME=/usr/java/jdk1.8.0_162
HADOOP_HOME=/opt/hadoop-2.7.7
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME HADOOP_HOME PATH CLASSPATH
- 存盘退出,执行命令:
source /etc/profile,让配置生效

C. 编辑hadoop环境配置文件 - hadoop-env.sh
-
执行命令:
cd $HADOOP_HOME/etc/hadoop,进入hadoop配置目录

-
执行命令:
vim hadoop-env.sh

export JAVA_HOME=/usr/java/jdk1.8.0_162
export HADOOP_HOME=/opt/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- 存盘退出后,执行命令
source hadoop-env.sh,让配置生效

D. 编辑核心配置文件 - core-site.xml
- 执行命令:
vim core-site.xml

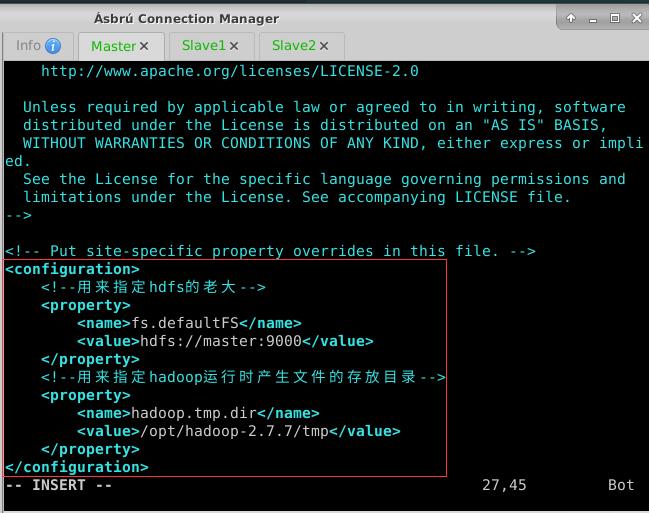
<configuration>
<!--用来指定hdfs的老大-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.7/tmp</value>
</property>
</configuration>
- 存盘退出。由于配置了IP地址主机名映射,因此可用
hdfs://master:9000,否则必须用IP地址hdfs://192.168.1.101:9000
E. 编辑HDFS配置文件 - hdfs-site.xml
- 执行命令:
vim hdfs-site.xml


<configuration>
<property>
<!--设置名称节点的目录-->
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.7/tmp/namenode</value>
</property>
<property>
<!--设置数据节点的目录-->
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.7.7/tmp/disk1,/opt/hadoop-2.7.7/tmp/disk2</value>
</property>
</configuration>
- 存盘退出
F. 编辑MapReduce配置文件 - mapred-site.xml
- 执行命令:
vim mapred-site.xml

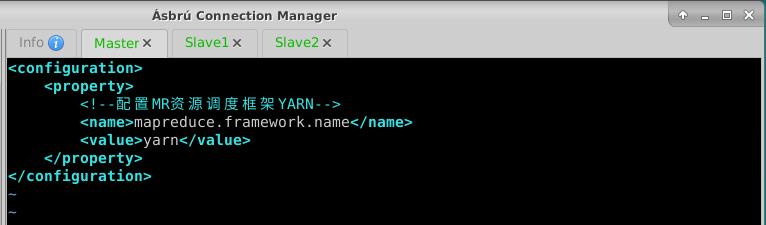
<configuration>
<property>
<!--配置MR资源调度框架YARN-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
G. 编辑yarn配置文件 - yarn-site.xml
- 执行命令:
vim yarn-site.xml


<configuration>
<property>
<!--配置资源管理器-->
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<!--配置节点管理器-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
H. 编辑slaves文件(定名分)
- 通过slaves文件定义从节点,有两个:slave1与slave2
- 执行命令:
vim slaves
(2)将Master节点上的hadoop分发到Slave1与Slave2
- 执行命令:
scp -r $HADOOP_HOME root@slave1:$HADOOP_HOME
- 执行命令:
scp -r $HADOOP_HOME root@slave2:$HADOOP_HOME
(3)将Master节点上的环境配置文件分发到Slave1与Slave2
- 执行命令:
scp /etc/profile root@slave1:/etc/profile
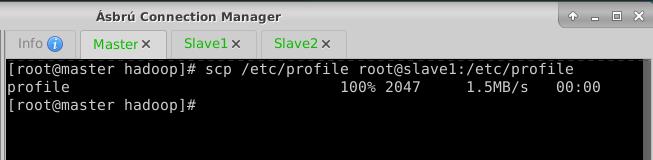
- 执行命令:
scp /etc/profile root@slave2:/etc/profile

(4)在Slave1与Slave2让环境配置生效
- 在Slave1节点上执行命令:
source /etc/profile
- 在Slave2节点上执行命令:
source /etc/profile
(5)在Master节点格式化名称节点
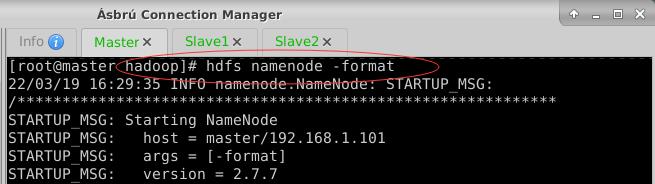
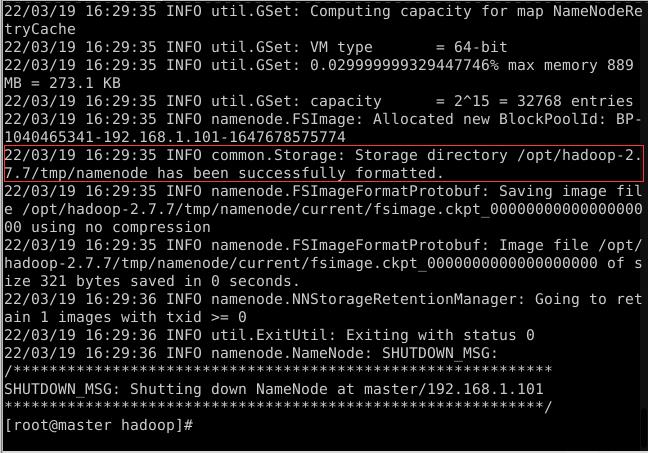
- 在Master虚拟机上,执行命令:
hdfs namenode -format
5、在Master节点上启动Hadoop集群
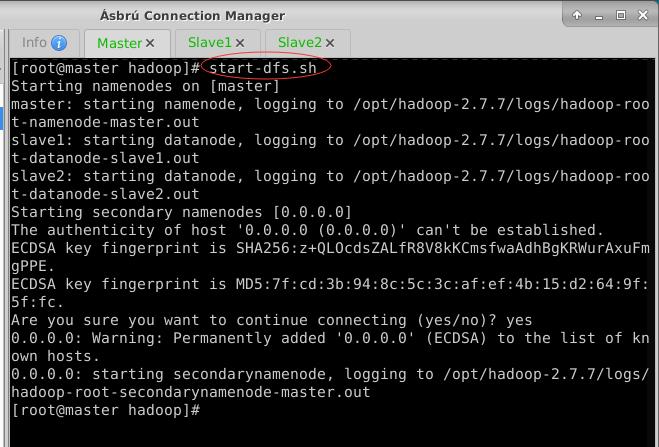
- 执行命令:
start-dfs.sh,启动HDFS服务
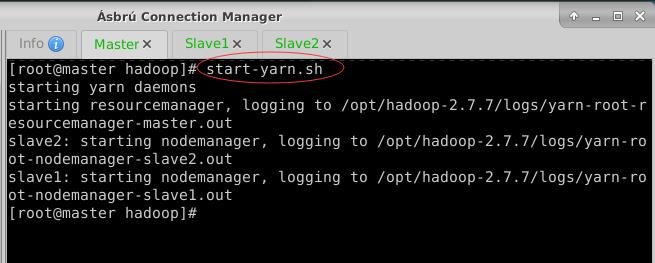
 - 执行命令:
- 执行命令:start-yarn.sh,启动YARN服务
- 执行命令:
jps,查看进程,有名称节点、辅助名称节点和资源管理器
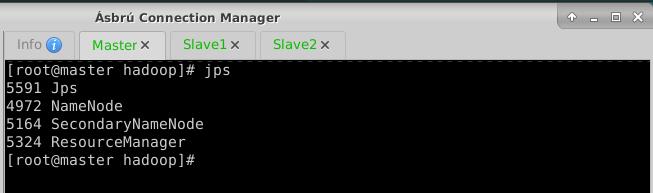
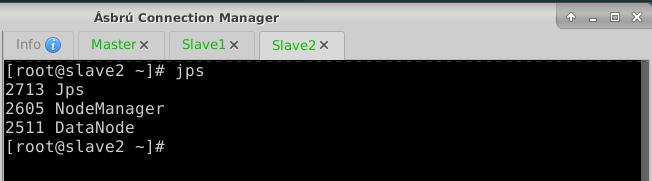
- 在Slave1节点上执行命令:
jps,有数据节点和节点管理器

- 在Slave2节点上执行命令:
jps,有数据节点和节点管理器
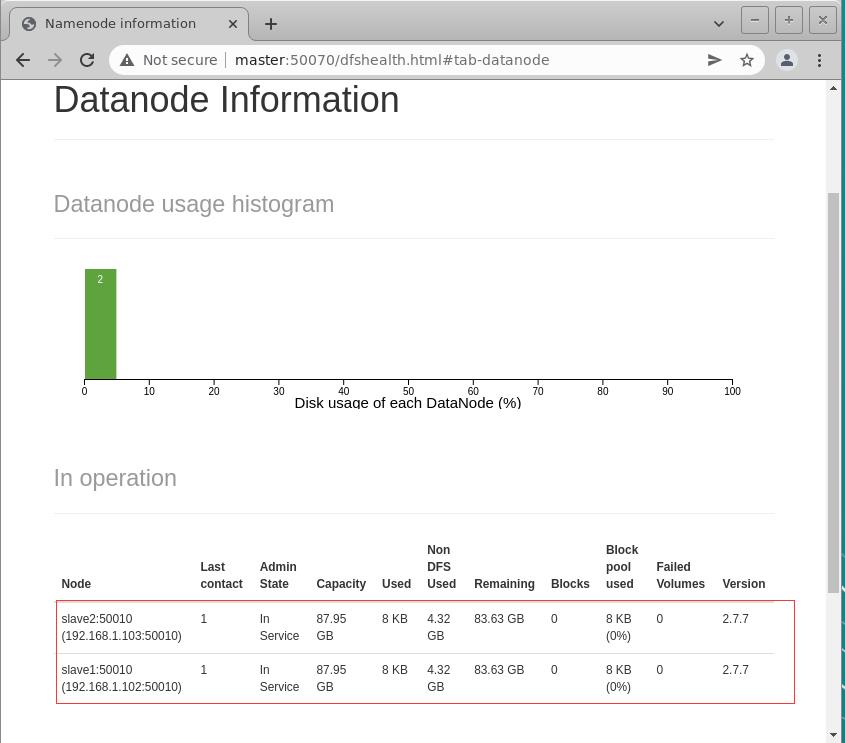
- 访问Hadoop集群的WebUI -
http://192.168.1.101:50070

- 在ubuntu节点上编辑
/etc/hosts文件,添加IP地址与主机名映射
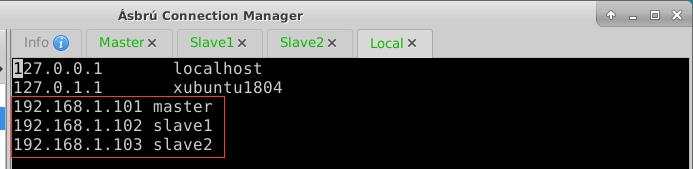
- 如此,就可以用
http://master:50070来访问Hadoop集群的WebUI
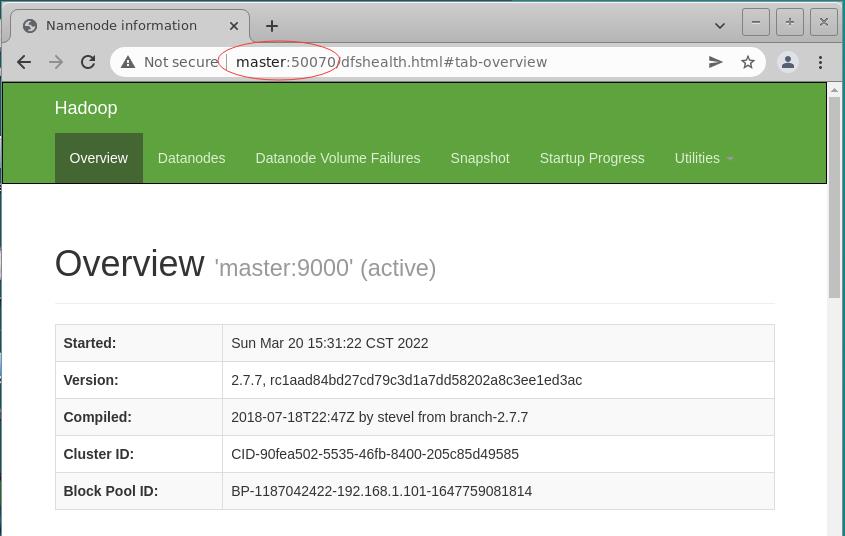
- 查看两个数据节点(在slave1与slave2上)
任务二:Spark on Yarn安装配置
(一)任务要求
- 本环节需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
- 将spark包解压到
/usr/路径,配置环境变量使其生效,将完整命令复制粘贴至对应报告中(若已安装,则可跳过); - 配置
/etc/profile文件,设置Spark环境变量,并使环境变量生效将环境变量配置内容复制粘贴至对应报告中; - 完 成 on yarn 相 关 配 置 , 使 用 spark on yarn的 模 式 提 交
$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.1.jar运行的主类为org.apache.spark.examples.SparkPi,将运行结果粘贴至对应报告中。
(二)完成任务
- Spark On YARN模式的搭建比较简单,仅需要在YARN集群的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。Spark本身的Master节点和Worker节点不需要启动。
1、将spark安装包解压到Master节点指定位置
- 执行命令:
tar -zxvf /chinaskills/spark-2.1.1-bin-hadoop2.7.tgz -C /usr

2、配置spark环境变量
- 执行命令:
vim /etc/profile

JAVA_HOME=/usr/java/jdk1.8.0_162
HADOOP_HOME=/opt/hadoop-2.7.7
SPARK_HOME=/usr/spark-2.1.1-bin-hadoop2.7
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME:/bin:$SPARK_HOME/sbin:$PATH
export JAVA_HOME HADOOP_HOME SPARK_HOME PATH CLASSPATH
- 存盘退出后,执行命令:
source /etc/profile,让配置生效
3、完成Spark on YARN配置
- 进入spark配置目录后,执行命令:
cp spark-env.sh.template spark-env.sh与vim spark-env.sh


export JAVA_HOME=/usr/java/jdk1.8.0_162
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export HADOOP_HOME=/opt/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- JAVA_HOME:指定JAVA_HOME的路径。若集群中每个节点在/etc/profile文件中都配置了JAVA_HOME,则该选项可以省略,Spark集群启动时会自动读取。为了防止出错,建议此处将该选项配置上。
- SPARK_MASTER_HOST:指定集群主节点(Master)的主机名,此处为master。
- SPARK_MASTER_PORT:指定Master节点的访问端口,默认为7077。
- 存盘退出,执行命令:
source spark-env.sh,让配置生效
 ,
, - 执行命令:
vim slaves,创建slaves文件,添加从节点


4、提交执行Spark应用程序
- 启动hdfs与yarn

- 使用spark on yarn的模式提交
$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.1.jar运行的主类为org.apache.spark.examples.SparkPi
$SPARK_HOME/bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.1.jar
- 执行上面的命令

- 执行命令,报错说没有数据节点
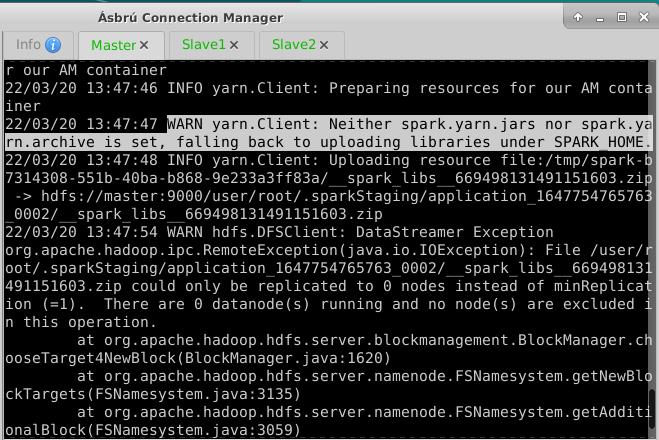
- 解决方法:关掉三个节点上的防火墙
- 执行命令:
systemctl stop firewalld与systemctl disable firewalld - 查看三个节点的防护墙状态
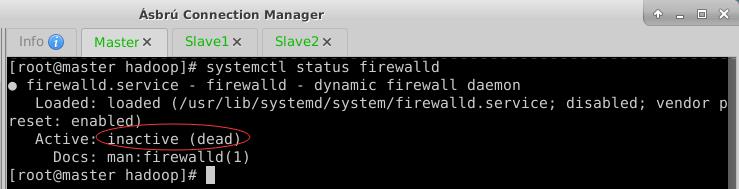
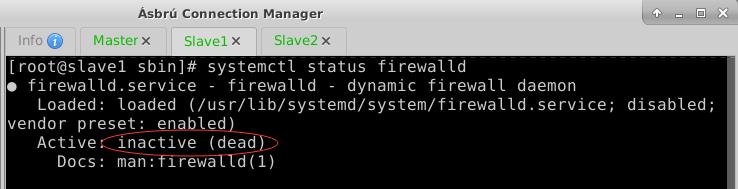

- 再次提交Spark应用程序

- 执行完显示
22/03/20 16:47:42 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.1.103
ApplicationMaster RPC port: 0
queue: default
start time: 1647766044471
final status: SUCCEEDED
tracking URL: http://master:8088/proxy/application_1647765492055_0003/
user: root
22/03/20 16:47:42 INFO util.ShutdownHookManager: Shutdown hook called
22/03/20 16:47:42 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-b639b00f-7040-426f-aec5-f095d2ab6f04
- 注意:
tracking URL: http://master:8088/proxy/application_1647765492055_0003/ - 程序执行过程中,可在YARN的ResourceManager对应的WebUI中查看应用程序执行的详细信息
- 浏览器中通过
http://master:8088来访问YARN的WebUI

- 查看Spark应用程序运行结果:Spark On YARN的cluster模式运行该例子的输出结果不会打印到控制台中,可以在上图的WebUI中单击
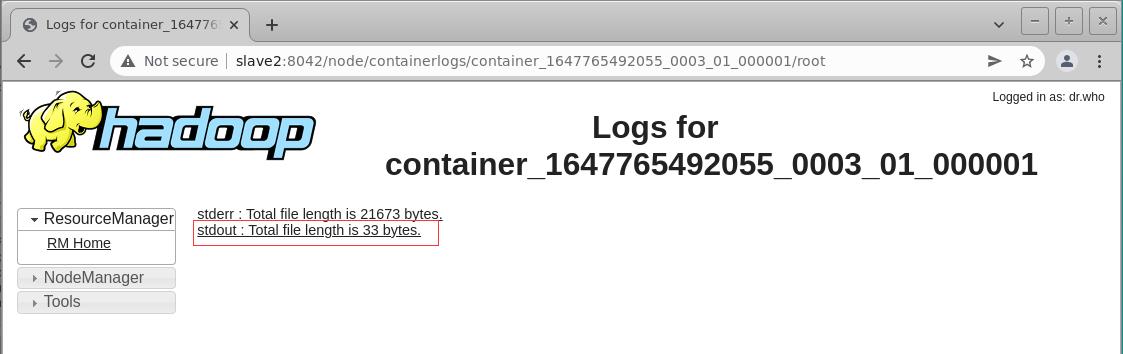
application Id,在Application详情页面的最下方单击Logs超链接,然后在新页面中单击stdout所属超链接,即可显示输出日志,而运行结果则在日志中,整个查看日志的过程如下所示。
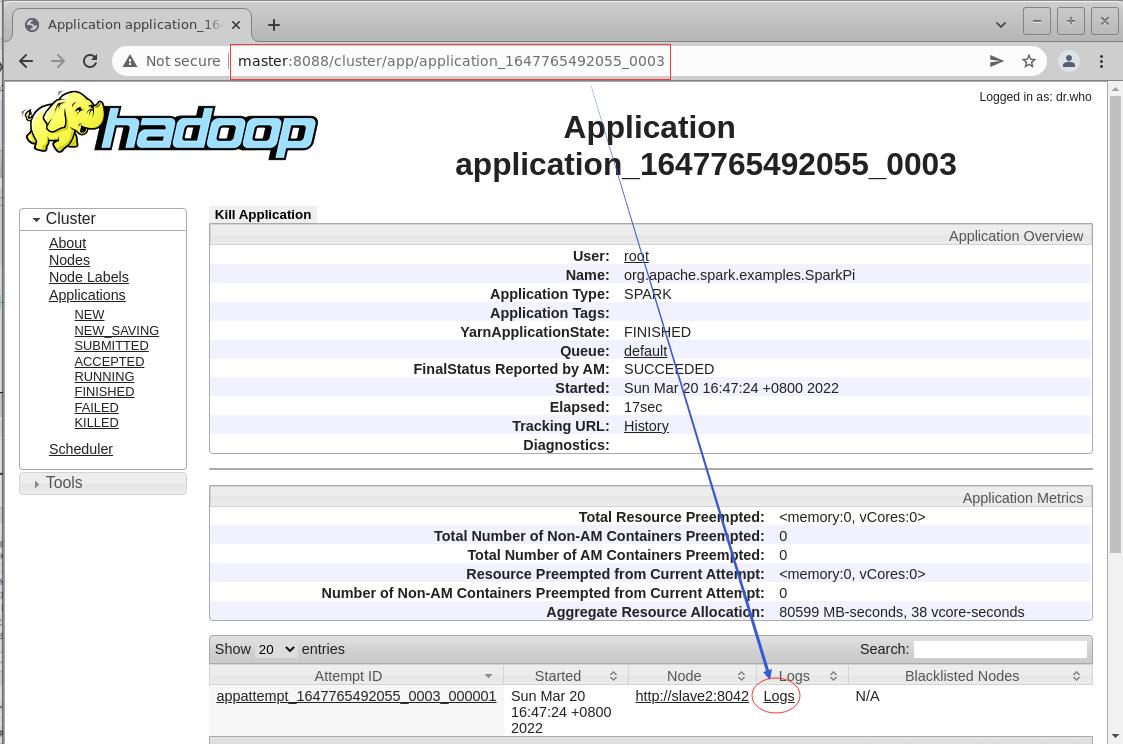
- 单击
Logs超链接

任务三:Flink on Yarn安装配置
(一)任务要求
- 本环节需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
- 将Flink包解压到路径/opt目录下,将完整命令复制粘贴至对应报告中;
- 修改
/etc/profile文件,设置Flink环境变量,并使环境变量生效将环境变量 配置内容复制粘贴至对应报告中; - 开启Hadoop集群,在yarn上以per job模式(即Job分离模式,不采用Session模 式)运行$FLINK_HOME/examples/batch/WordCount.jar,将运行结果最后10行复制粘贴至对应报告中。
- 示例 :flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar
(二)完成任务
以上是关于模块A:大数据平台搭建(容器环境)的主要内容,如果未能解决你的问题,请参考以下文章