大数据之维度建模中的重要概念
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之维度建模中的重要概念相关的知识,希望对你有一定的参考价值。
🌸本篇博客,是在经历了小10轮面试后,我对大数据建模中,比较重要的知识点进行了梳理,截取了书中一些常考的概念,在这里列举出来给大家,大家对面经感兴趣的可以参查看如下内容👇:
- 2022字节终面: 2022字节跳动数仓实习面经(2、3面、hr面).
- 2022字节一面面经: 2022字节跳动数据仓库实习面经.
- 2022 字节被拒面经: 2022暑期实习字节跳动数据研发面试经历.
- 2022百度面经: 2022百度大数据开发工程师实习面试经历.
🌳经这几次的面试,发现自己在数据模型这块的确有所欠缺,虽然知道数仓中有这个概念,但却不能用规范的语言将它描述出来,下面我将介绍数据建模中比较重要的部分,大家需要根据这些概念,自行理解消化。
目录
1. 大数据建设体系架构
以下是阿里巴巴集团的大数据体系架构,很多其他的大厂也在使用这一套标准的流程。
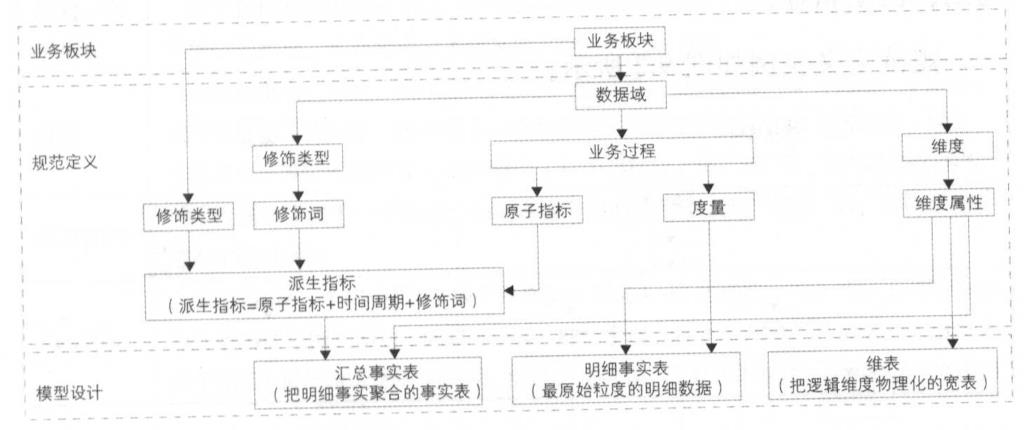
业务板块:根据公司的业务生态,划分出几个相对独立的业务板块,各板块之间的指标和业务重叠较小,如:电商板块、物流板块等
规范定义:公司业务庞大,需要有一套标准的规范命名体系来设计数据仓库模型。
模型设计:模型一般都选择维度建模,构建一致性的维度表和事实表,统一设计和命名规范。
2. 规范定义部分
这一部分是对大数据体系架构中各部分内容进行规范定义(以电商模块为例)
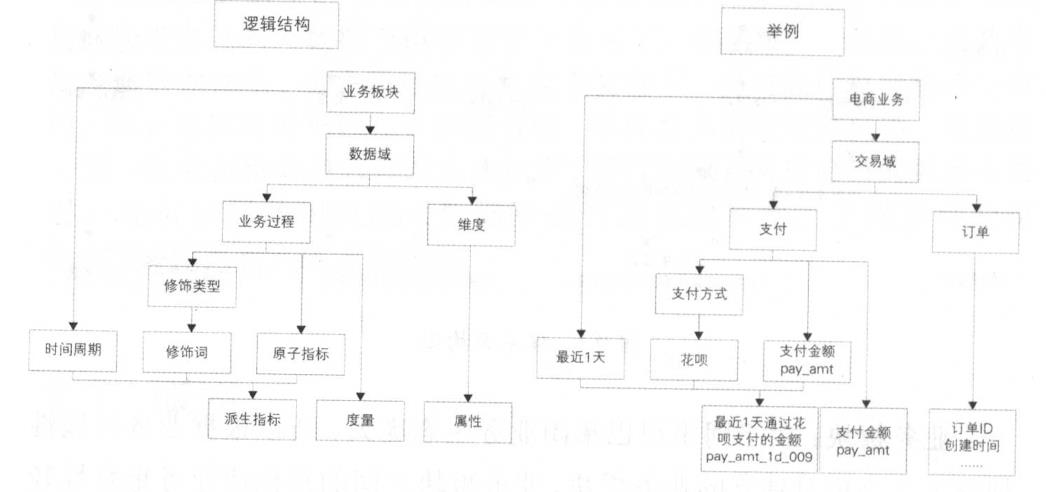
2.1 名词术语
业务板块:基于业务特征划分的命名空间,在同一个业务板块中可能包含多个不同的项目。
数据域:数据域是当前业务板块下,一组/一串/一类业务活动单元的集合,如日志、交易。 项目属于具体的业务板块。 数据域是指面向业务分析,将业务过程或维度进行抽象的集合。为保障整个体系的生命力,数据域需要抽象提炼,并长期维护更新,但不轻易变动。
业务过程:指企业的业务活动事件,如下单、支付、退款都是业务过程。 请注意,业务过程业务过程是一个不可拆分的行为事件,通俗地讲,业务过程就是企业活动中的事件。
时间周期: 用来明确数据统计的时间范用或者时间点,如最近 30 天、自然周、截至当日等。
修饰类型:是对修饰词的一种抽象划分。 修饰类型从属于某个业务域,如日志域的访问终端类型涵盖无线端、 PC 端等修饰词
修饰词:指除了统计维度以外指标的业务场景限定抽象。修饰词隶属于一种修饰类型,如修饰词在日志域的访问终端类型下,有修饰词 PC 端、无线端等。
原子指标:某一业务事件行为下的度量,是业务中不可再拆分的指标,如支付金额。
维度:维度是度量的环境,用来反映业务的一类属性 , 这类属性的集合构成一个维度 , 也可以称为实体对象。维度属于一个数据域,如地理维度(其中包挤罔家、地区、 省以及城市等级别的内容)、时间维度(其中包括年、季、月、周、日等级别的内容)
维度属性:维度属性隶属于一个维度 , 如地理维度里面的国家名称、同家 ID、省份名称等
派生指标:派生指标=一个原子指标+多个修饰词(可选)+时间周期。如最近1天海外买家支付金额(支付金额为原子指标,最近1天为时间周期,买家为维度,海外为修饰词)
2.2 指标体系
原子指标:业务中不可再拆分的指标。
派生指标:由原子指标、时间周期修饰词、若干其他修饰词组合
派生指标的种类:事务型指标、存量型指标和复合型指标
- 事务型指标:是指对业务活动进行衡量的指标。例如新发商品数、重发商品数(不用新建原子指标)
- 存量型指标:是指对实体对象(如商品、会员)某些状态的统计。
例如商品总数、注册会员总数。(不用新建原子指标) - 复合型指标:是在事务型指标和存量型指标的基础上复合而成
的。例如浏览 UV-下单买家数转化率等。(根据情况而定)
3. 模型设计
3.1 建模理论
维度建模为主题思想(星形模型),设计为以下几个步骤:
- 选择需要进行分析决策的业务过程
- 确定粒度
- 识别维表
- 选择事实
3.2 模型层次
- 数据操作层ODS:把操作系统数据几乎无处理地存放在数据仓 库系统中。
- 公共维度模型层CDM:存放明细事实数据、维表数据及公共指标汇总数据 , 其中明细事实数据、维表数据一般根据 ODS 层数据加工生成,CDM 层又细分为明细数据层DWD 和汇总数据层DWS ,采用维度模型方法作为理论基础,更多地采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联,提高明细数据表的易用性:同时在汇总数据层,加强指标的维度退化,采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性。
- 应用数据层APP:存放数据产品个性化的统计指标数据,根据CDM 层与 ODS 层加工生成 。(个性化指标:排名型、比值型等)
4. 维度设计
4.1 维度的定义
维度是维度建模的基础和灵魂。在维度建模中,将度量称为“事实” ,将环境描述为“维度”,维度是用于分析事实所需要的多样环境。
4.2 维度设计步骤
- 第一步:选择维度或新建维度。作为维度建模的核心,在企业级数 据仓库中必须保证维度的唯一性。以淘宝商品维度为例,有且只允许有一个维度定义。
- 第二步:确定主维表。此处的主维表一般是 ODS 表,直接与业务系统同步。以淘宝商品维度为例, s_auction_ auctions 是与前台商品中心系统同步的商品表,此表即是主维表。
- 第三步:确定相关维表。数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联性。根据对业务的梳理,确定哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。以淘宝商品维度为例,根据对业务逻辑的梳理,可以得到商品与类目、 SPU 、 卖家、店铺等维度存在关联关系。
- 第四步:确定维度属性。本步骤主要包括两个阶段,其中第一个阶段是从主维表中选择维度属性或生成新的维度属性;第二个阶段是从相关维表中选择维度属性或生成新的维度属性。以淘宝商品维度为例,从主维表 ( s_auction_auctions)和类目、 SPU、卖家、店铺等相关维表中选择维度属性或生成新的维度属性。
4.3 维度的层次
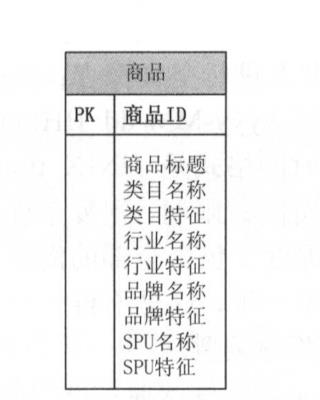
维度中的一些描述属性以层次方式或一对多的方式相互关联,可以被理解为包含连续主从关系的属性层次。层次的最底层代表维度中描述最低级别的详细信息,最高层代表最高级别的概要信息。维度常常有多个这样的嵌入式层次结构。比如淘宝商品维度,有卖家、类目、品牌等。 商品属于类目,类目属于行业,其中类目的最低级别是叶子类目,叶子 类目属于二级类目,二级类目属于一级类目(多层的维度是用雪花模型存储吗?)
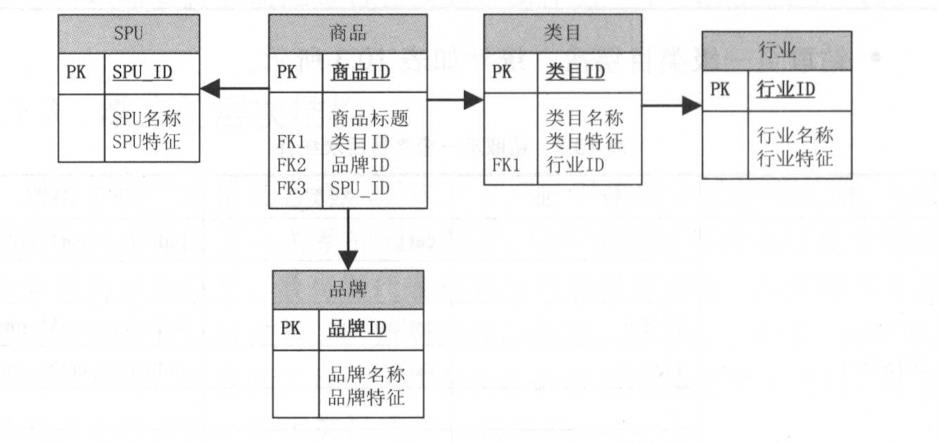
答案是否定的,雪花模型一般用于OLTP,而OLAP是用空间换时间,反规范化处理。
4.4 维度的一致性
在针对不同数据域进行迭代构建或并行构建时,存在很多需求是对于不同数据域的业务过程或者同一数据域的不同业务过程合并在一起观察。比如对于日志数据域,统计了商品维度的最近一天的 PV 和 UV ; 对于交易数据域,统计了商品维度的最近一天的下单 GMV。现在将不同数据域的商品的事实合并在一起进行数据探查,如计算转化率等,称为交叉探查。(说的简单一点,对于有较大联系的业务过程,最好设置有相同的维度属性,格式,命名,含义,范围都一样)具体的方法如下:
- 共享维表, 比如在阿里巴巴的数据仓库中,商品、卖家、买家、类目等维度有且只有一个。所以基于这些公共维度进行的交叉勘查不会存在任何问题。(涉及到这些维度的,都有固定的维度)
- 一致性上卷,其中一个维度的维度属性是另一个维度的维度属性
的子集,且两个维度的公共维度属性结构和内容相同。比如在阿里巴巴的商品体系中,有商品维度和类目维度,其中类目维度的维度属性是商品维度的维度属性的子集,且有相同的维度属性和维度属性值。这样基于类目维度进行不同业务过程的交叉探查也不会存在任何问题。(维度互相为父子集) - 交叉属性,两个维度具有部分相同的维度属性。比如在商品维度
中具有类目属性,在卖家维度中具有主营类目属性,两个维度具有相同的类目属性,则可以在相同的类目属性上进行不同业务过程的交叉探查。(维度属性相同)
4.5 维度整合
维度整合指的是,数仓建设过程中,数据来源多样,如何将这些来源多样的数据中的维度进行集成。
- 垂直整合,即不同的来源表包含相同的数据集,只是存储的信息不同。比如淘宝会员在源系统中有多个表,如会员基础信息表、会员扩展信息表、淘宝会员等级信息表、天猫会员等级信息表,这些表 都属于会员相关信息表,依据维度设计方法,尽量整合至会员维度模型中,丰富其维度属性。(同一数据集,维度属性不同)
- 水平整合,即不同的来源表包含不同的数据集,不同子集之间无交叉,也可以存在部分交叉。比如针对蚂蚁金服的数据仓库,其采集的会员数据有淘宝会员、 1688 会员、国际站会员、支付宝会员等, 是否需要将所有的会员整合到一个会员表中呢?通常采用将来源表各子集的自然键作为联合主键的方式,并且在物理实现时将来源字段作为分区字段。(不同数据集,维度属性相似)
4.6 维度拆分
- 水平拆分:由于维度分类的不同而存在特殊的维度属性,可以通过水平拆分的方式解决此问题,比如航旅的商品和普通的淘系商品,都属于商品,都有商品价格、标题、类型、上架时间、类目等维度属性,但是航旅的商品除了有这些公共属性外,还有酒店、景点、门票、旅行等自己独特的维度属性。如何设计维度?针对此问题,主要有两种解决方案:方案1是将维度的不同分类实例化为不同的维度,同时在主维度中保存公共属性 ;方案2是维护单一维度,包含所有可能的属性。
- 垂直拆分:某些维度属性的来源表产出时间较早,而某些维度属性的来源表产出时间较晚;或者某些维度属性的热度高、使用频繁,而某些维度属性的热度低、较少使用;或者某些维度属性经常变化,而某些维度属性比较稳定,出于扩展性、产出时间、易用性等方面的考虑,设计主从维度。主维表存放稳定、产出时间早、热度高的属性;从维表存放变化较快、产出时间晚、热度低的属性。
4.7 缓慢变化维度
如何处理维度的变化是维度设计的重要工作之一。缓慢变化维的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间的流逝发生缓慢的变化 。与数据增长较为快速的事实表相比,维度变化相对缓慢,那么应该如何处理这些变化的维度呢?
- 快照维表
- 历史拉链表
- 极限存储
- 微型维度
5. 事实表设计
5.1 事实表的特性
- 事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设 计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度 和与业务过程有关的度量。
- 事实表中一条记录所表达的业务细节程度被称为粒度。通常粒度可 以通过两种方式来表述:一种是维度属性组合所表示的细节程度:一种 是所表示的具体业务含义。
- 作为度量业务过程的事实,一般为整型或浮点型的十进制数值,有可加性、半可加性和不可加性三种类型。
5.2 事实表的种类
- 事务事实表:任何类型的事件都可以被理解为一种事务。比如交易过程中的创建订单、买家付款等,都可以被理解为一种事务。事务事实表, 即针对这些 过程构建的一类事实表,用以跟踪定义业务过程的个体行为,提供丰富的分析能力,作为数据仓库原子的明细数据。(一条数据记录着一件事务的变化)
- 周期快照事实表:当需要一些状态度量时,比如账户余额、买卖家星级 、 商品库存、卖家累积交易额等,则需要聚集与之相关的事务才能进行识别计算,于是便有了周期快照事实表。快照事实表在确定的问隔内对实体的度量进行抽样,这样可以很容易地研究实体的度量值,而不需要聚集长期的事务历史。
- 累计快照事实表:事务型事实表能够很好的记录单一事务的发生,但对于统计不同的事务时间的关系逻辑较为复杂。比如统计买家下单到支付的时长、买家支付到卖家发货的时长、买家从下单到确认收货的时长等。如果使用事务事实表进行统计,则逻辑复杂且性能很差。对于类似于研究事件之间时间间 隔的需求,采用累积快照事实表可以很好地解决。累积快照事实表。对实体的某一实例定期更新。累积快照事实表样式如下:

5.3 三种事实表的比较
| 名称 | 事务事实表 | 周期快照事实表 | 累计快照事实表 |
|---|---|---|---|
| 时间 | 离散事务时间点 | 以有规律的、可预测的间隔产生快照 | 用于时间跨度不确定的不断变化的工作流 |
| 日期维度 | 事务日期 | 快照日期 | 相关业务课程涉及的多个日期 |
| 粒度 | 每一行代表实体的一个事务 | 每行代表某时间周期的一个实体 | 每行代表一个实体的生命周期 |
| 事实 | 事务事实 | 累计事实 | 相关业务过程事实和时间间隔事实 |
| 事实表加载 | 插入 | 插入 | 插入与更新 |
| 事实表更新 | 不更新 | 不更新 | 业务过程变更时更新 |
6. 总结
以上的内容,截取自《阿里巴巴大数据之路》,我也不能记住全部,但也能大致说出来个大概,再结合自己做过的项目经验,能和面试官说清楚即可,一定不要死记硬背,理解记忆,效果最好。
7. 参考资料
重要的参考说三遍:
- 《阿里巴巴大数据之路》
- 《阿里巴巴大数据之路》
- 《阿里巴巴大数据之路》
以上是关于大数据之维度建模中的重要概念的主要内容,如果未能解决你的问题,请参考以下文章