KafkaKafka 的 Broker 与 KafkaController 介绍
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KafkaKafka 的 Broker 与 KafkaController 介绍相关的知识,希望对你有一定的参考价值。

1.概述
转载:Kafka总结(二)常见组件上 Broker、Producer和Consumer介绍
源码参考:【kafka】kafka 启动 KafkaController 相关源码分析
2. Broker 介绍
Broker没有副本机制,一旦Broker宕机,该Broker的消息都将不可用。
Broker不会保存Consumer 消费topic partition offset的状态,订阅者自己采用不同模式保存。
无状态导致消息的删除成为难题(有可能会删除正在被消费的消息),kafka采用基于事件的SLA(服务水平保证),消息保存一定时间(默认7天,168小时)会被自动删除
消费者可以将offset重新定位到任意位置进行重新消费,当Consumer故障时,可以选择最小的offset进行重新读取消费数据。
2.1 Broker 的启动过程
Broker启动后先根据其ID在Zookeeper的/brokers/ids/ids znode 下面创建临时子节点,
创建成功后 Controller 的 ReplicaStateMachine 注册其上的 Broker Change Watch 会被触发,从而通过回调 KafkaController.onBrokerStartup方法,
回调方法向所有新启动的Broker发送 UpdateMetadataRequest。
将新启动的 Broker上的所有副本设置为OnlineReplica状态,同时这些Broker会为这些Partition 启动 high watermark线程。
通过partitionStateMachine 触发 OnlinePartitionStateChange。
3.Kafka Controller(控制器)
Kafka 集群中会有一个或者多个Broker,有一个Broker会被选举为控制器(Kafka Controller),它负责整个集群中所有分区和副本的状态。
选择Partition Leader:当某个分区副本出现故障时,由Kafka Controller负责为该分区选举新的leader副本。更新元数据:从Zookeeper中获取当前所有topic、partition以及Broker相关信息进行相应的管理。增/减/分配分区:当使用kafka-topics.sh 脚本为某个topic增加分区数量时,同样还是由Kafka Controller负责新增分区的分配。
3.1 Controller 选举与具体功能
每个Broker在启动的时候都会去尝试读取 /controller 节点的brokerid的值,
如果ZK中不存在 /controller 节点,或者这个节点值为-1,那么会尝试去创建 /controller 节点,在去创建/controller节点的时候,也有可能其他的broker同时尝试创建这个节点,只有创建成功的broker会成为控制器,创建失败的则意味着竞选失败会在 /controller 上注册一个Watch。
如果读取到brokerid的值不为-1,则表示已经有其他broker节点成功竞选为控制器,则该broker就会放弃竞选,并且会在 /controller 上注册一个Watch。
当Controller挂掉时临时节点会自动消失,这时Watch会被触发,此时所有active的Broker都会去竞选成为新的Controller。
/controller 临时节点值如下:
[zk: localhost:2181(CONNECTED) 2] get /controller
"version":1,"brokerid":0,"timestamp":"1581320839809"
# version:目前版本中固定为1
# brokerid:表示控制器的broker的id编号
#timestamp:表示竞选成为控制器的时间戳
每个broker都会在内存中保存当前控制器的brokerid的值,这个值标识位activeControllerId。当/controller节点的数据发生变化时,每个broker都会更新自身内存中保存的activeControllerId。
如果broker在数据变更前是控制器,那么如果在数据变更后自身的brokerid值与新的activeControllerId值不一致的话,那么就需要“退位”,关闭相应的资源,比如关闭状态机、注销相应的监听器等。有可能控制器由于异常而下线,造成/controller这个临时节点会被自动删除;也有可能是其他原因将此节点删除了。
当/controller节点被删除时,每个broker都会进行选举,
如果broker在节点被删除前是控制器的话,在选举前还需要有一个“退位”的动作。
如果有特殊需要,可以手动删除/controller节点来触发新一轮的选举。当然关闭控制器所对应的broker以及手动向/controller节点写入新的brokerid的所对应的数据同样可以触发新一轮的选举。
Zookeeper中还有一个与控制器有关的节点:/controller_epoch节点,这个节点是一个持久化节点(Persistent),它保存的是一个整型的controller_epoch值。这个值用于记录控制器发生变更的次数。即记录当前的控制器是第几代控制器,当控制器发生变更时,每选出一个新的控制器都会在该值的基础上 +1 ,每个和控制器交互的请求都会携带上controller_epoch的值。
[zk: localhost:2181(CONNECTED) 4] get /controller_epoch
3
如果请求的 controller_epoch 值小于内存中 controller_epoch 的值,则认为这个请求是向已经过期的控制器发送的请求,那么这个请求会被认定为无效请求。
如果请求的 controller_epoch 值大于内存中 controller_epoch 的值,则说明已经有新的控制器当选了。
由此可见,kafka通过controller_epoch 来保证控制器的唯一性,进而保证相关操作的一致性。
3.2 Controller 选举成功后的操作
Broker成功竞选为Controller后会触发KafkaController.onControllerFailover 方法,并在该方法中完成如下操作:
- 读取并在
/controller_epoch的值基础上+1。 - 增加一系列监听用于处理集群环境的变化,具体有哪些监听可以查看 Controller 事件监听章节。
- 初始化 Controller对象,设置当前所有Topic、Broker列表、Partition的Leader以及ISR等
- 启动 replicaStateMachine 和 partitionStateMachine
- 将brokerState 状态设置为 partitionStateMachine
- 将每个Partition的Leadership 发送给所有active 的Broker
- 若auto.leader.rebalance.enable设置为true,则还会开启一个名为”auto-leader-rebalance-task”的定时任务来负责维护分区的有限副本的均衡。
- 如果delete.topic.enable值为true,且/admin/delete_topics中有值,则删除对应的topic
3.3 Controller 事件监听
在Kafka的早期版本中,并没有采用Kafka Controller这样一个概念来对分区和副本的状态进行管理,而是依赖于Zookeeper,每个broker都会在Zookeeper上为分区和副本注册大量的监听器(Watcher)。当分区或者副本状态变化时,会唤醒很多不必要的监听器,这种严重依赖于Zookeeper的设计会有脑裂、羊群效应以及造成Zookeeper过载的隐患。
在目前的新版本的设计中,只有Kafka Controller在Zookeeper上注册相应的监听器,其他的broker极少需要再监听Zookeeper中的数据变化,这样省去了很多不必要的麻烦。不过每个broker还是会对/controller节点添加监听器的,以此来监听此节点的数据变化(参考ZkClient中的IZkDataListener)。
控制器在选举成功之后会读取Zookeeper中各个节点的数据来初始化上下文信息(ControllerContext),并且也需要管理这些上下文信息,比如为某个topic增加了若干个分区,控制器在负责创建这些分区的同时也要更新上下文信息,并且也需要将这些变更信息同步到其他普通的broker节点中。
不管是监听器触发的事件,还是定时任务触发的事件,亦或者是其他事件(比如ControlledShutdown)都会读取或者更新控制器中的上下文信息,那么这样就会涉及到多线程间的同步,如果单纯的使用锁机制来实现,那么整体的性能也会大打折扣。针对这一现象,Kafka的控制器使用单线程基于事件队列的模型,将每个事件都做一层封装,然后按照事件发生的先后顺序暂存到LinkedBlockingQueue中,然后使用一个专用的线程(ControllerEventThread)按照FIFO(First Input First Output, 先入先出)的原则顺序处理各个事件,这样可以不需要锁机制就可以在多线程间维护线程安全。
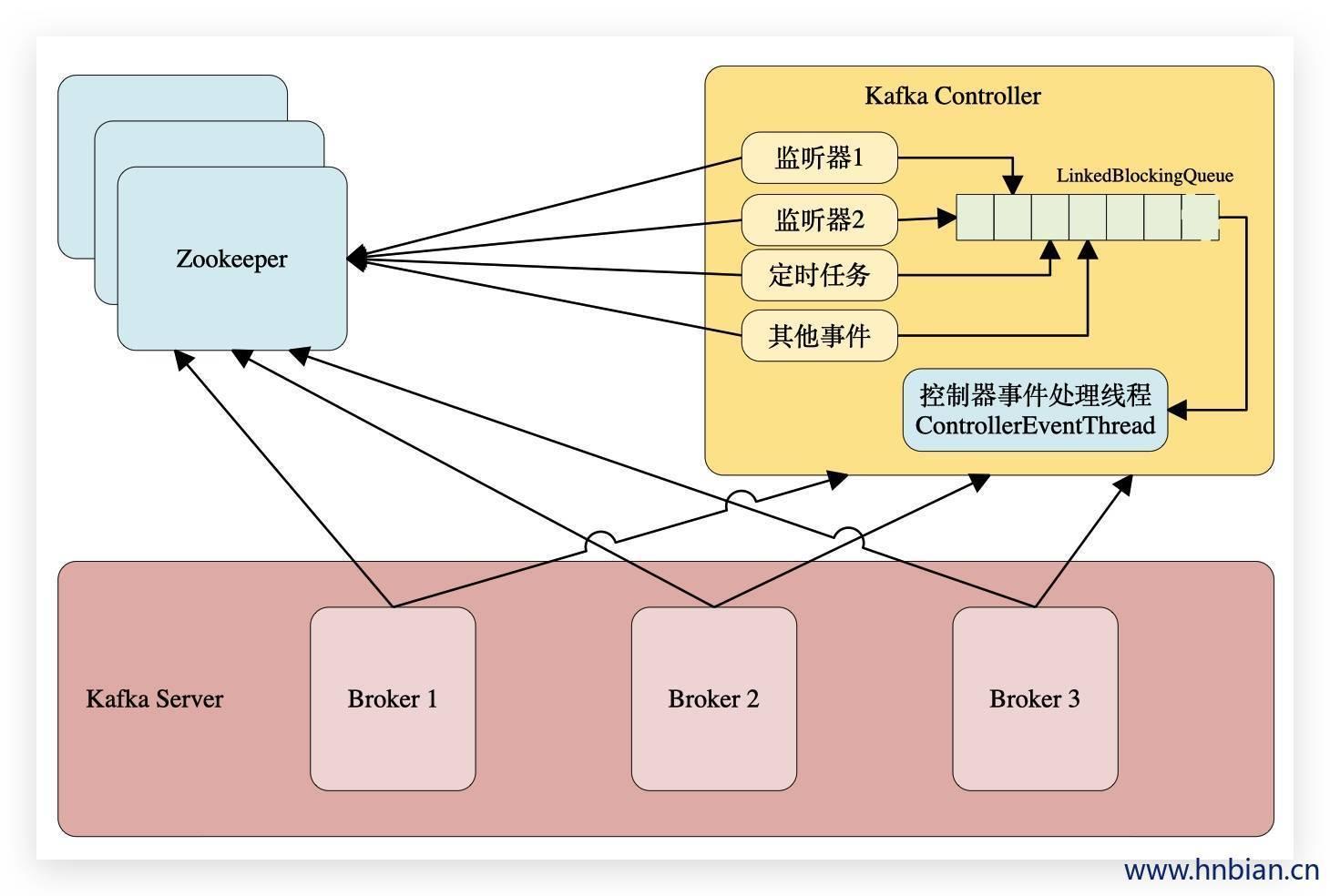
Kafka Controller事件监听处理
监听partition的变化
| 功能 | 添加监听的zk节点 | 添加的Listener |
|---|---|---|
| 处理分区重分配 | /admin/reassign_partitions | PartitionReassignmentListener |
| 处理优先副本选举 | /admin/preferred_replica_election | PreferredReplicaElectionListener |
| 处理ISR集合变更 | /isr_change_notification | IsrChangeNotificationListener |
监听topic相关变化
| 功能 | 添加监听的zk节点 | 添加的Listener |
|---|---|---|
| 处理topic增减的变化 | /brokers/topics | TopicChangeListener |
| 处理删除topic动作 | /admin/delete_topics | TopicDeletionListener |
| 处理topic分区变化 | /brokers/topics/[topic] | PartitionModificationsListener |
监听broker相关的变化
| 功能 | 添加监听的zk节点 | 添加的Listener |
|---|---|---|
| 处理broker增减变化 | /brokers/ids | BrokerChangeListener |
3.4 Controller 对 Broker 的故障处理
Controller在Zookeeper的/brokers/ids节点上注册Watch 用来处理broker增减变化,一旦有Broker宕机对应的Zookeeper上的节点会自动删除,就会触发Controller的Watch,Controller即会获取最新的active的Broker列表。
Controller 决定Set_p,该集合包含了宕机的Broker上的所有Partition副本分布。
对于Set_p中的每个Partition会做如下操作:
-
从
/brokers/topics/topic-name/partitions/partition-id/state读取该partition的ISR。ISR是什么会在下一个章节中介绍 -
决定该partition的新leader,
- 如果当前ISR中至少有一个副本还处于active状态,则选择其中一个为新的Leader,新的ISR中包含当前ISR中所有幸存的副本
- 如果当前ISR中没有副本存活,则选择该partition任意一个存活的副本作为新的Leader以及ISR(这种场景会存在数据丢失的风险)
- 如果该partition所有的副本都宕机了,则将新的leader设置为-1
-
将新的Leader、新的leader_epochISR以及controller_epoch 写入
/brokers/topics/topic-name/partitions/partition-id/state。 -
直接通过RPC向Set_p 相关的Broker发送LeaderAndISRRequest命令,Controller可以在一个RPC操作中发送多个命令从而提高效率。
3.5 LeaderAndISRRequest的响应过程
Broker收到 LeaderAndISRRequest 主要通过ReplicaManager 的 becomeLeaderOrFollower 处理:
若请求中controller_epoch 值小于最新的 controller_epoch 的值,则认为这个请求是向已经过期的控制器发送的请求,那么这个请求会被认定为无效请求,直接返回ErrorMapping.StaleControllerEpochCode
对于请求中 partitionStateInfos 中的每一个元素,即((topic, partitionId), partitionStateInfo):
- 若 partitionStateInfo 中的 leader epoch 大于当前 ReplicManager 中存储的 (topic, partitionId) 对应的 partition 的 leader epoch,则:
- 若当前 brokerid(或者说 replica id)在 partitionStateInfo 中,则将该 partition 及 partitionStateInfo 存入一个名为 partitionState 的 HashMap 中
- 否则说明该 Broker 不在该 Partition 分配的 Replica list 中,将该信息记录于 log 中
- 否则将相应的 Error code(ErrorMapping.StaleLeaderEpochCode)存入 Response 中
筛选出partitionState 中Leader与当前BrokerID相等的所有记录保存到 partitionsTobeLeader 中,其它记录存入 partitionsToBeFollower 中
若 partitionsTobeLeader 不为空,则对其执行 makeLeaders 方
若 partitionsToBeFollower 不为空,则对其执行 makeFollowers 方法
若 highwatermak 线程还未启动,则将其启动,并将 hwThreadInitialized 设为 true
关闭所有 Idle 状态的 Fetcher
3.6 Broker 响应请求的流程
Broker 通过kafka.network.SocketServer 及其相关模块接受各种请求并作出相应,整个网络通信模块基于Java NIO 开发,并采用 Reactor模式,其中包括1个Acceptor负责接受客户请求,N个Processor负责读写数据,M个Handle 处理业务逻辑。
Acceptor:主要负责监听并接受客户端发送的请求,包括Producer、Consumer、Controller、Admin Tool 等的请求,并建立和客户端的数据传输通道,然后为该客户端指定一个 Processor,至此它对该客户端的该次请求的任务就结束了,可以去响应下一个客户端的连接请求了。
Processor:主要负责从客户端读取数据并将响应返回给客户端,它本身并不处理具体的业务逻辑,并且其内部维护了一个队列来保存分配给它的所有 SocketChannel。Processor 会循环调用run方法从队列中取出新的SocketChannel,并将其SelectionKey.OP_READ 注册到selector 上,然后循环处理已就绪的读(请求)和写(响应)。Processor读完数据之后,将其封装成 Request对象,并将其交给RequestChannel。
RequestChannel是Processor 和KafkaRequestHandler 交换数据的地方,它包含一个队列,requestQueue用来存放Processor 加入 Request 。
Processor 会通过prosessNewReponses 方法依次将 requestChannel 中的ResponseQueue保存的Response取出,将其对应的SelectionKey.OP_WRITE事件注册到selector 上。当selector的select 方法返回时,对检测到的可写通道,调用write方法,将Response返回给客户端。
Handler:KafkaRequestHandler 循环送 RequestChannel 中读取Request 并交给kafka.server.kafkaAPIs 处理具体业务逻辑。同时 这个Request还包含一个respondQueue,用来存放KafkaRequestHandler处理完Request后返还给客户端的Response.
以上是关于KafkaKafka 的 Broker 与 KafkaController 介绍的主要内容,如果未能解决你的问题,请参考以下文章