大数据技术&并行计算
Posted 真空零点能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术&并行计算相关的知识,希望对你有一定的参考价值。
大数据
通常来说,常规软件无法完成抓取、处理的数据可称为大数据(Big Data)。例如,互联网上的网页数据,社交网站上的用户交互数据,物联网产生的活动数据、电信网络的话单数据等。
- 大数据典型特征在于数字信息的量级,单台机器的分析技术无法扩展,需要一个可靠的、分布式的计算方案。
- 大数据体量庞大。人们为数据存储开发了许多新技术,但数据量却在以每两年翻一番的速度增长,各企业都在努力应对数据的快速增长,不断寻找更高效的数据存储方式。
- 数据的价值在于运用。需要做很多工作才能获得清洁数据,例如数据科学家在真正开始使用数据之前,通常要耗费 50% 到 80% 的时间来管理和准备数据。
- 大数据技术的更新速度非常快,紧跟大数据技术的发展脚步是一项持久性挑战。
处理流程
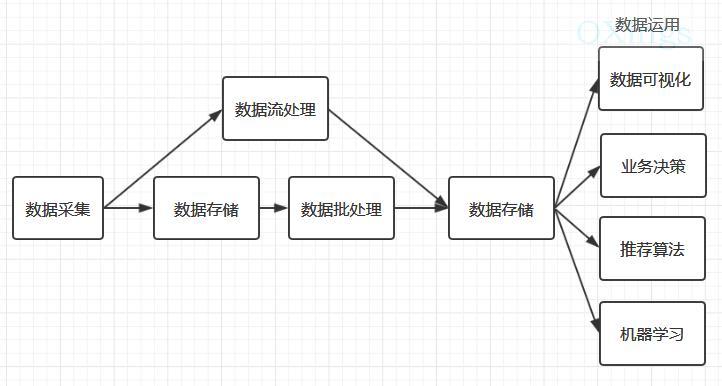
数据经过清理,抽取知识,生成模型,从而做统计分析,预测,将数据转换成智能决策。有几个路径和方式转换成知识和模型:
- 符号主义 >> 知识表示 >> 知识图谱
- 连接主义 >> 神经网络 >> 深度学习
- 行为主义 >> 控制论 >> 机器人
并行计算
并行计算是将一个任务分解成若干个小任务并协同执行以完成求解的过程,是增强复杂问题解决能力和提升性能的有效途径。深度学习,知识图谱和机器人,都离不开分布式计算资源。
相关技术
大数据应用划分四个方面:业务处理、统计分析、数据挖掘和机器学习。
- Hadoop 是最流行的大数据处理技术之一,它把分析任务划分为工作片段,并分派到上千台计算机上,提供快速分析和海量数据分布式存储。
- 数据分析侧重于数据的收集和解释,过去和现在的统计。典型技术工具:Hive HBase Spark Sql
- 数据科学侧重于探索性分析,关注未来趋势。典型技术工具:Python R MLlib
- 日志收集框架:Flume、Logstash、Filebeat
- 分布式文件存储系统:Hadoop HDFS
- 数据库系统:Mongodb、HBase、数据湖
- 批处理框架:Hadoop MapReduce
- 流处理框架:Storm
- 混合处理框架:Spark、Flink
- 查询分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
- 集群资源管理器:Hadoop YARN
- 分布式协调服务:Zookeeper
- 数据迁移工具:Sqoop
- 任务调度框架:Azkaban、Oozie
- 集群部署和监控:Ambari、Cloudera Manager
大数据&人工智能时代
大数据、并行计算带来无数的机遇,这些知识模型,作为外部大脑,为人类和机器人提供智能决策和行动,让人工智能成为现实。计算资源之间可以共享,协作,共同完成任务,它们构成了最强大脑。物联网提供了输入、行动,大数据提供了知识模型和智能,并行计算提供了工具,它们相辅相成,成就最后的人工智能。
 https://blog.oxings.com/article/65
https://blog.oxings.com/article/65以上是关于大数据技术&并行计算的主要内容,如果未能解决你的问题,请参考以下文章