Sharding-JDBC 实战(史上最全)
Posted 架构师-尼恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sharding-JDBC 实战(史上最全)相关的知识,希望对你有一定的参考价值。
文章很长,而且持续更新,建议收藏起来,慢慢读! Java 高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源:
- 免费赠送 经典图书 : 极致经典 + 社群大片好评 《 Java 高并发 三部曲 》 面试必备 + 大厂必备 + 涨薪必备
- 免费赠送 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 (加尼恩领取)
- 免费赠送 经典图书 : 《SpringCloud、Nginx高并发核心编程》 面试必备 + 大厂必备 + 涨薪必备 (加尼恩领取)
- 免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 (加尼恩领取)
Sharding-JDBC 实战(史上最全)
在开始 Sharding-JDBC分库分表具体实战之前,
必要先了解分库分表的一些核心概念。
分库分表的背景:
传统的将数据集中存储⾄单⼀数据节点的解决⽅案,在性能、可⽤性和运维成本这三⽅⾯已经难于满⾜互联⽹的海量数据场景。
随着业务数据量的增加,原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。
当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等,
此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
容量瓶颈:
从性能⽅⾯来说,由于关系型数据库⼤多采⽤ B+ 树类型的索引,
数据量超过一定大小,B+Tree 索引的高度就会增加,而每增加一层高度,整个索引扫描就会多一次 IO 。
在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;
一般的存储容量是多少呢? 请参见 3 高架构秒杀部分内容。
吞吐量瓶颈:
同时,⾼并发访问请求也使得集中式数据库成为系统的最⼤瓶颈。
一般的吞吐量是多少呢? 请参见 3 高架构秒杀部分内容。
在传统的关系型数据库⽆法满⾜互联⽹场景需要的情况下,将数据存储⾄原⽣⽀持分布式的 NoSQL 的尝试越来越多。
但 NoSQL 并不能包治百病,而关系型数据库的地位却依然不可撼动。
如果进行sql、nosql数据库的选型呢? 请参见 推送中台架构部分的内容。
分治模式在存储领域的落地
分治模式在存储领域的使用:数据分⽚
数据分⽚指按照某个维度将存放在单⼀数据库中的数据, 分散地存放⾄多个数据库或表中以达到提升性能瓶颈以及可⽤性的效果。
数据分⽚的有效⼿段是对关系型数据库进⾏分库和分表。
分库能够⽤于有效的分散对数据库单点的访问量;
分库的合理的时机, 请参见 3 高架构秒杀部分内容。
分表能够⽤于有效的数据量超过可承受阈值而产⽣的查询瓶颈, 解决mysql 单表性能问题
分表的合理的时机, 请参见 3 高架构秒杀部分内容。
使⽤多主多从的分⽚⽅式,可以有效的避免数据单点,从而提升数据架构的可⽤性。
通过分库和分表进⾏数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进⾏疏导应对⾼访问量,是应对⾼并发和海量数据系统的有效⼿段。
数据分⽚的拆分⽅式⼜分为垂直分⽚和⽔平分⽚。
分库分表的问题
分库导致的事务问题
不过,由于目前采用柔性事务居多,实际上,分库的事务性能也是很高的,有关柔性事务,请参见疯狂创客圈的专题博文:
Sharding-JDBC简介
Sharding-JDBC 是当当网开源的适用于微服务的分布式数据访问基础类库,完整的实现了分库分表,读写分离和分布式主键功能,并初步实现了柔性事务。
从 2016 年开源至今,在经历了整体架构的数次精炼以及稳定性打磨后,如今它已积累了足够的底蕴。
官方的网址如下:
http://shardingsphere.apache.org/index_zh.html
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar这3款相互独立的产品组成。
他们均提供标准化的数据分片、分布式事务 和 数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
Sharding-JDBC的优势
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
- 可适用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
- 可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
- 理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle、SQLServer等数据库的计划。
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
与常见开源产品对比
下表仅列出在数据库分片领域非常有影响力的几个项目:
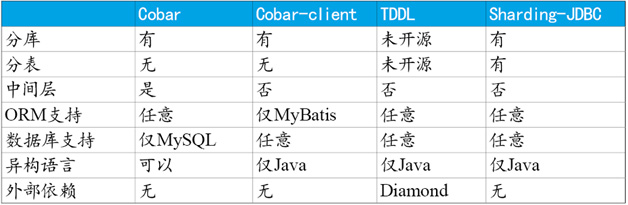
通过以上表格可以看出,Cobar(MyCat)属于中间层方案,在应用程序和MySQL之间搭建一层Proxy。
中间层介于应用程序与数据库间,需要做一次转发,而基于JDBC协议并无额外转发,直接由应用程序连接数据库,性能上有些许优势。这里并非说明中间层一定不如客户端直连,除了性能,需要考虑的因素还有很多,中间层更便于实现监控、数据迁移、连接管理等功能。
Cobar-Client、TDDL和Sharding-JDBC均属于客户端直连方案。
此方案的优势在于轻便、兼容性、性能以及对DBA影响小。其中Cobar-Client的实现方式基于ORM(Mybatis)框架,其兼容性与扩展性不如基于JDBC协议的后两者。
目前常用的就是Cobar(MyCat)与Sharding-JDBC两种方案
MyCAT
MyCAT是社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,
目前已经有一些公司在使用MyCAT。
总体来说支持度比 较高,也会一直维护下去,发展到目前的版本,已经不是一个单纯的MySQL代理了,
它的后端可以支持MySQL, SQL Server, Oracle, DB2, PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。
MyCAT是一个强大的数据库中间件,不仅仅可以用作读写分离,以及分表分库、容灾管理,而且可以用于多租户应用开发、云平台基础设施,让你的架构具备很强的适应性和灵活性,
借助于即将发布的MyCAT只能优化模块,系统的数据访问瓶颈和热点一目了然,
根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表隐射到不同存储引擎上,而整个应用的代码一行也不用改变。
MyCAT是在Cobar基础上发展的版本,两个显著提高:
-
后端由BIO改为NIO,并发量有大幅提高;
-
增加了对Order By, Group By, Limit等聚合功能
(虽然Cobar也可以支持Order By, Group By, Limit语法,但是结果没有进行聚合,只是简单返回给前端,聚合功能还是需要业务系统自己完成, 适用于有专门团队维护的大型企业、或者大团队。)
Sharding-JDBC
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
所以 ,适用于中小企业、或者中小团队。
Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
Sharding-JDBC 功能列表
- 分库 & 分表
- 读写分离
- 分布式主键
高并发数据分片的两大工作
一般情况下,开发维度的数据分片,大多是以水平切分模式(水平分库、分表)为基础来说的,
垂直分片主要在于 运维维度,或者 或者做存储的深级改造的时候。
数据分片的工作
简单来说,数据分片的工作分为两大工作 :
第一大工作:分片的拆分
es 的数据分片的背后原理
参见视频
rediscluster的数据分片的背后原理
表的拆分:
将一张大表 t_order ,拆分生成数个表结构完全一致的小表 t_order_0、t_order_1、···、t_order_n,
每张小表,只存储大表中的一部分数据,
第二大工作:分片的路由
当执行一条SQL时,会通过 路由策略 , 将数据**route(路由)**到不同的分片内。
面临的问题:
-
分片建的选择
-
分片策略的选择
-
分片算法的选择
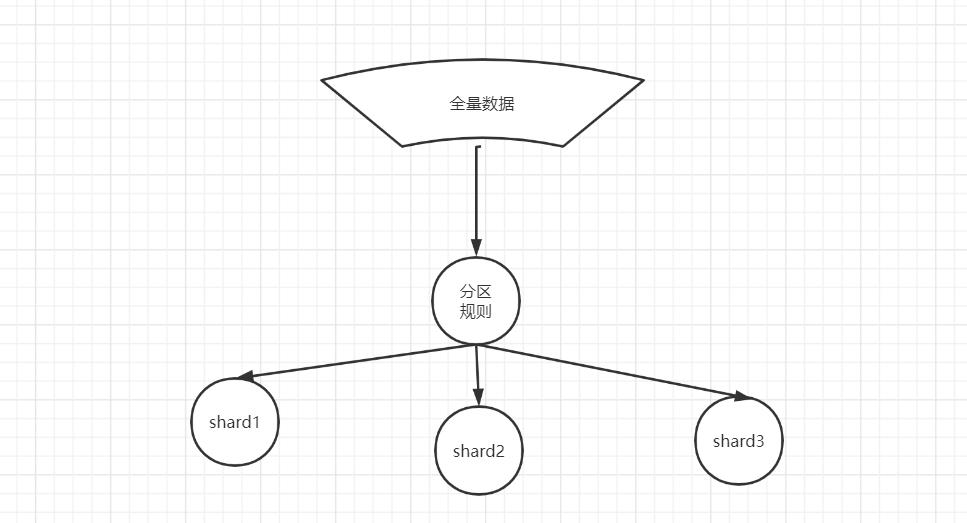
什么是数据分片?
按照分片规则把数据分到若干个shard、partition当中
主要的分片算法
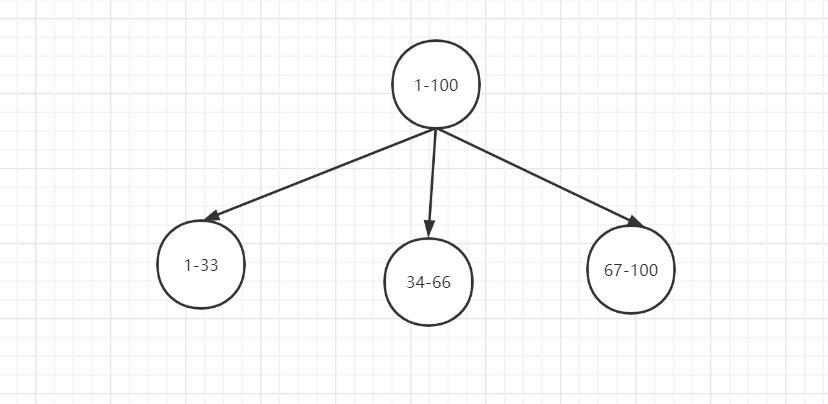
range 分片
一种是按照 range 来分,就是每个片,一段连续的数据,这个一般是按比如时间范围/数据范围来的,但是这种一般较少用,因为很容易发生数据倾斜,大量的流量都打在最新的数据上了。
比如,安装数据范围分片,把1到100个数字,要保存在3个节点上
按照顺序分片,把数据平均分配三个节点上
- 1号到33号数据保存到节点1上
- 34号到66号数据保存到节点2上
- 67号到100号数据保存到节点3上
ID取模分片
此种分片规则将数据分成n份(通常dn节点也为n),从而将数据均匀的分布于各个表中,或者各节点上。
扩容方便。
ID取模分片常用在关系型数据库的设计
具体请参见 秒杀视频的 亿级库表架构设计
hash 哈希分布
使用hash 算法,获取key的哈希结果,再按照规则进行分片,这样可以保证数据被打散,同时保证数据分布的比较均匀
哈希分布方式分为三个分片方式:
- 哈希取余分片
- 一致性哈希分片
- 虚拟槽分片
哈希取余模分片
例如1到100个数字,对每个数字进行哈希运算,然后对每个数的哈希结果除以节点数进行取余,余数为1则保存在第1个节点上,余数为2则保存在第2个节点上,余数为0则保存在第3个节点,这样可以保证数据被打散,同时保证数据分布的比较均匀
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上
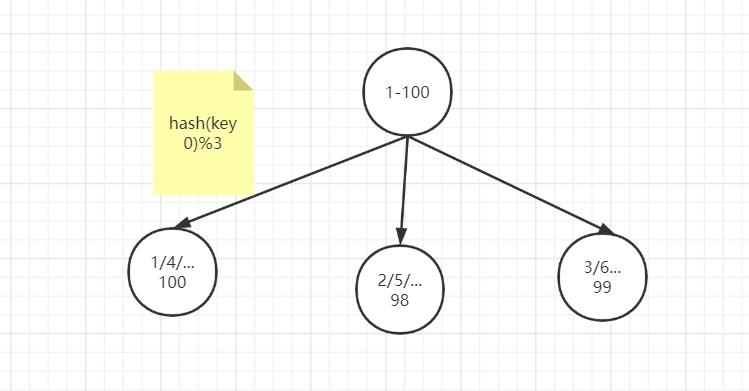
哈希取余分片是非常简单的一种分片方式
哈希取模分片有一个问题
即当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分布
哈希取余分片,建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。
数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据
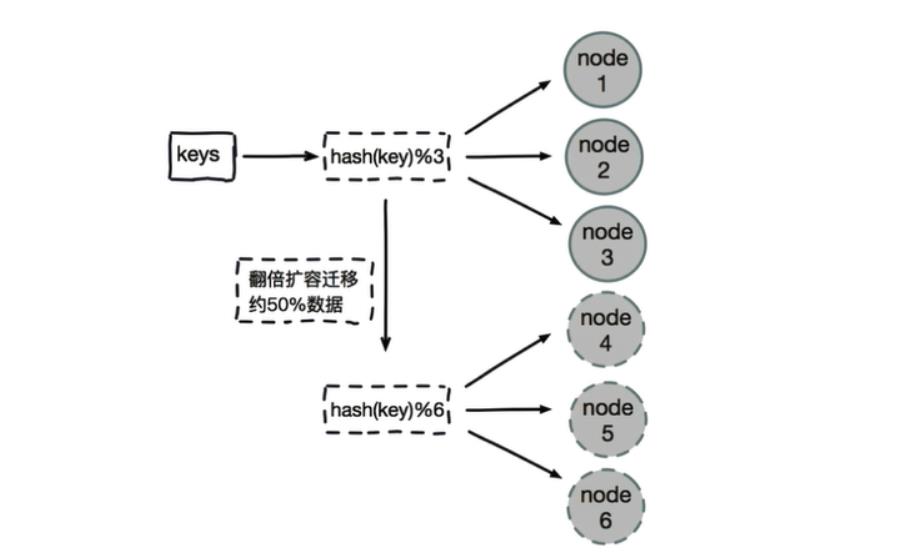
哈希取余分片优点:
- 配置简单:对数据进行哈希,然后取余
哈希取余分片缺点:
- 数据节点伸缩时,导致数据迁移
- 迁移数量和添加节点数据有关,建议翻倍扩容
一致性哈希分片
一致性哈希原理:
将所有的数据当做一个token环,
token环中的数据范围是0到2的32次方。
然后为每一个数据节点分配一个token范围值,这个节点就负责保存这个范围内的数据。
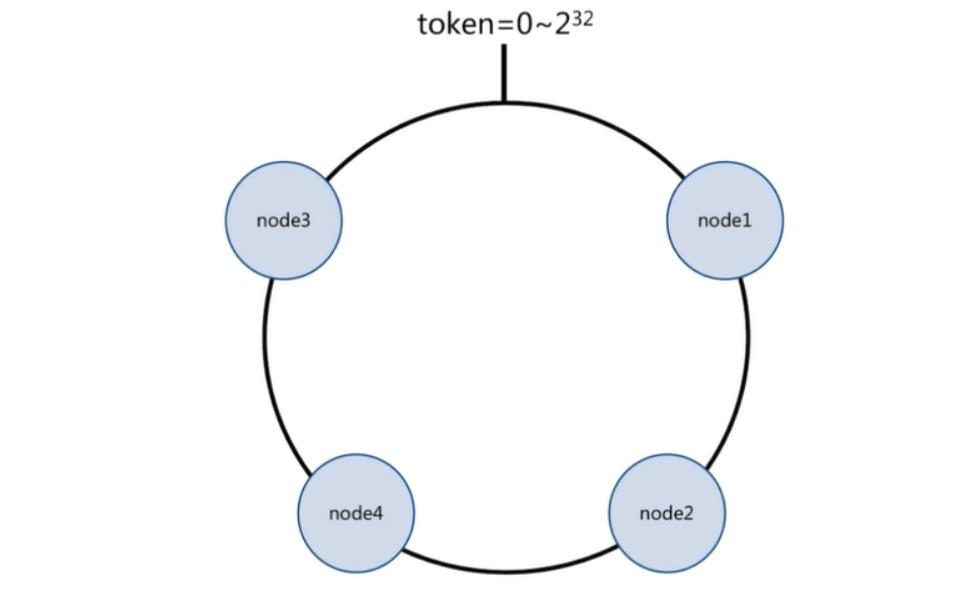
对每一个key进行hash运算,被哈希后的结果在哪个token的范围内,则按顺时针去找最近的节点,这个key将会被保存在这个节点上。
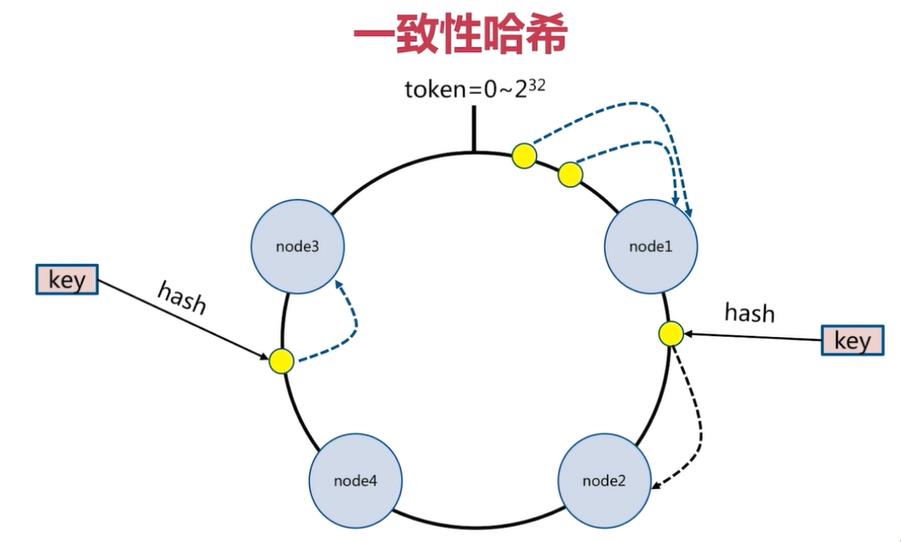
一致性哈希分片的节点扩容
在下面的图中:
-
有4个key被hash之后的值在在n1节点和n2节点之间,按照顺时针规则,这4个key都会被保存在n2节点上
-
如果在n1节点和n2节点之间添加n5节点,当下次有key被hash之后的值在n1节点和n5节点之间,这些key就会被保存在n5节点上面了
下图的例子里,添加n5节点之后:
- 数据迁移会在n1节点和n2节点之间进行
- n3节点和n4节点不受影响
- 数据迁移范围被缩小很多
同理,如果有1000个节点,此时添加一个节点,受影响的节点范围最多只有千分之2。所以,一致性哈希一般用在节点比较多的时候,节点越多,扩容时受影响的节点范围越少
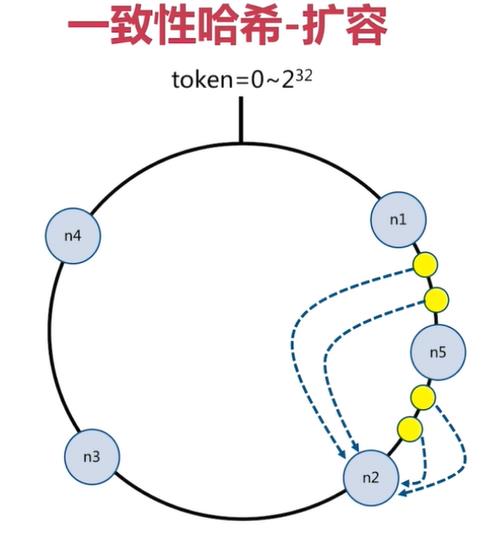
分片方式:哈希 + 顺时针(优化取余)
一致性哈希分片优点:
- 一致性哈希算法解决了分布式下数据分布问题。比如在缓存系统中,通过一致性哈希算法把缓存键映射到不同的节点上,由于算法中虚拟节点的存在,哈希结果一般情况下比较均匀。
- 节点伸缩时,只影响邻近节点,但是还是有数据迁移
“但没有一种解决方案是银弹,能适用于任何场景。所以实践中一致性哈希算法有哪些缺陷,或者有哪些场景不适用呢?”
一致性哈希分片缺点:
一致性哈希在大批量的数据场景下负载更加均衡,但是在数据规模小的场景下,会出现单位时间内某个节点完全空闲的情况出现。
虚拟槽分片 (范围分片的变种)
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式.
虚拟槽分片 ,可以理解为范围分片的变种, hash取模分片+范围分片, 把hash值取余数分为n段,一个段给一个节点负责
es的数据分片两大工作
Shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。
分片的数量只能在索引创建前指定,并且索引创建后不能更改。(why,大家可以独立思考一下!)
分片配置建议:
每个分片大小不要超过30G,硬盘条件好的话,不建议超过100G.
(官方推荐,每个shard的数据量应该在20GB - 50GB)。
总而言之,每个分片都是一个Lucene实例,当查询请求打到ES后,ES会把请求转发到每个shard上分别进行查询,最终进行汇总。
这时候,shard越少,产生的额外开销越少
路由机制
一条数据是如何落地到对应的shard上的?
当索引一个文档的时候,文档会被存储到一个主分片中。
Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?

es的路由过程是根据下面这个算法决定的:
shard_num = hash(_routing) % num_primary_shards
其中 _routing是一个可变值,默认是文档的 _id 的值 ,也可以设置成一个自定义的值。Elasticsearch文档的ID(类似于关系数据库中的自增ID),
_routing 通过 hash 函数生成一个数字,然后这个数字再除以 num_of_primary_shards (主分片的数量)后得到余数 。
这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:
因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
假设你有一个100个分片的索引。当一个请求在集群上执行时会发生什么呢?
1. 这个搜索的请求会被发送到一个节点
2. 接收到这个请求的节点,将这个查询广播到这个索引的每个分片上(可能是主分片,也可能是复本分片)
3. 每个分片执行这个搜索查询并返回结果
4. 结果在通道节点上合并、排序并返回给用户
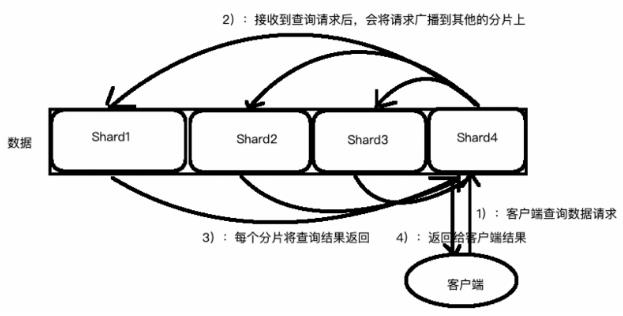
rediscluster的数据分片两大工作
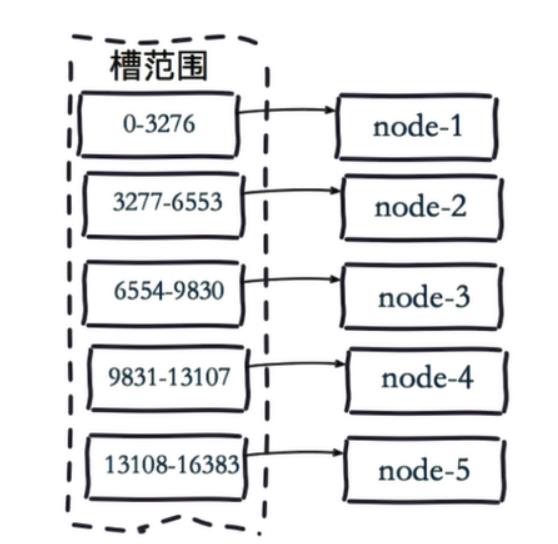
虚拟槽分片 ( hash取模分片+范围分片的混血)
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式.
在该分片方式中:
- 首先 预设虚拟槽,每个槽为一个hash值,每个node负责一定槽范围。
- 每一个值都是key的hash值取余,每个槽映射一个数据子集,一般比节点数大
Redis Cluster中预设虚拟槽的范围为0到16383

3个节点的Redis集群虚拟槽分片结果:
[root@localhost redis-cluster]# docker exec -it redis-cluster_redis1_1 redis-cli --cluster check 172.18.8.164:6001
172.18.8.164:6001 (c4cfd72f...) -> 0 keys | 5461 slots | 1 slaves.
172.18.8.164:6002 (c15a7801...) -> 0 keys | 5462 slots | 1 slaves.
172.18.8.164:6003 (3fe7628d...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 172.18.8.164:6001)
M: c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd 172.18.8.164:6001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: a212e28165b809b4c75f95ddc986033c599f3efb 172.18.8.164:6006
slots: (0 slots) slave
replicates 3fe7628d7bda14e4b383e9582b07f3bb7a74b469
M: c15a7801623ee5ebe3cf952989dd5a157918af96 172.18.8.164:6002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 5e74257b26eb149f25c3d54aef86a4d2b10269ca 172.18.8.164:6004
slots: (0 slots) slave
replicates c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd
S: 8fb7f7f904ad1c960714d8ddb9ad9bca2b43be1c 172.18.8.164:6005
slots: (0 slots) slave
replicates c15a7801623ee5ebe3cf952989dd5a157918af96
M: 3fe7628d7bda14e4b383e9582b07f3bb7a74b469 172.18.8.164:6003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
虚拟槽分片的路由机制:
1.把16384槽按照节点数量进行平均分配,由节点进行管理
2.对每个key按照CRC16规则进行hash运算
3.把hash结果对16383进行取模
4.把余数发送给Redis节点
5.节点接收到数据,验证是否在自己管理的槽编号的范围
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。
当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
shardingjdbc的数据分片两大工作
第一大工作:分片的拆分
表的拆分:
将一张大表 t_order ,拆分生成数个表结构完全一致的小表 t_order_0、t_order_1、···、t_order_n,
每张小表,只存储大表中的一部分数据,
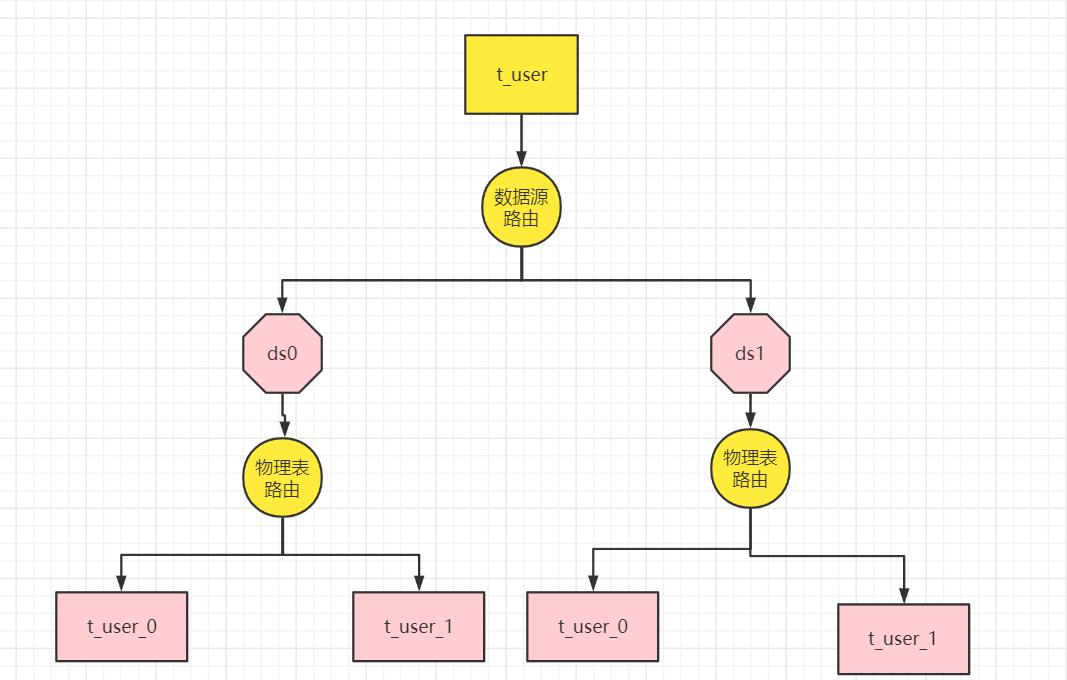
例子:user表的数据分片
例子:order表的数据分片

第二大工作:分片的路由
当执行一条SQL时,会通过 路由策略 , 将数据**route(路由)**到不同的分片内。
-
数据源的路由
-
表的路由
面临的问题:
- 分片key的选择
- 分片策略的选择
- 分片算法的选择
核心概念
分⽚键
⽤于分⽚的字段,是将数据库(表)⽔平拆分的关键字段。
在对表中的数据进行分片时,首先要选出一个分片键(Shard Key),即用户可以通过这个字段进行数据的水平拆分。
例:
将订单表中的订单主键的尾数取模分⽚,则订单主键为分⽚字段。
执行表的选择
我们将 t_order 表分片以后,当执行一条 SQL 时,通过对字段 order_id 取模的方式来决定要执行的表, 这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是分片健。
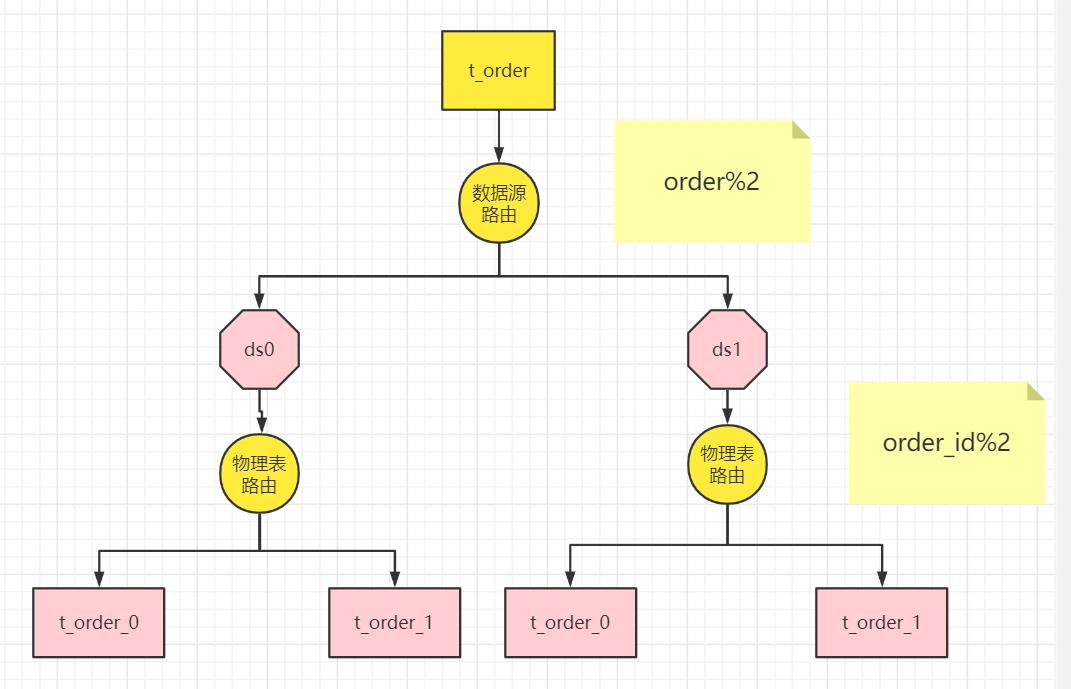
执行库的选择(数据源的选择)
这样以来同一个订单的相关数据就会存在同一个数据库表中,大幅提升数据检索的性能,
说明
-
除了使用单个字段作为分片件, sharding-jdbc 还支持根据多个字段作为分片健进行分片。
-
SQL 中如果⽆分⽚字段,将执⾏全路由,性能较差。
数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,
例如上图中 ds1.t_user_0 就表示一个数据节点。
逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。
比如我们将订单表 t_order 拆分成 t_order_0 ··· t_order_9 等 10 张表。
此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL 依然按 t_order 来写。
此时 t_order 就是这些拆分表的逻辑表。
例如上图中 t_user 就表示一个数据节点。
真实表(物理表)
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
例如上图中 t_user _0就表示一个真实表。
分片策略
分片策略是一种抽象的概念,实际分片操作的是由分片算法和分片健来完成的。
真正可⽤于分⽚操作的是分⽚键 + 分⽚算法,也就是分⽚策略。
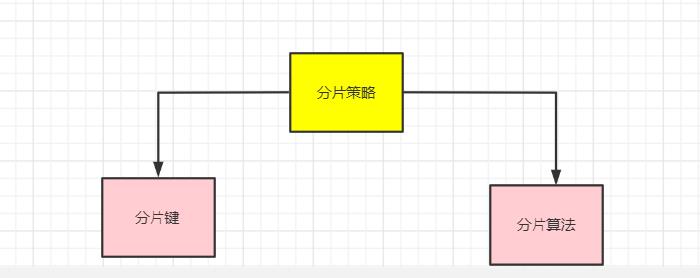
为什么要这么设计,是出于分⽚算法的独⽴性,将其独⽴抽离。
ShardingSphere-JDBC考虑更多的灵活性,把分片算法单独抽象出来,方便开发者扩展;
标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。
RangeShardingAlgorithm 用于处理BETWEEN AND, >, <,>=,<= 条件分片,
RangeShardingAlgorithm 是可选的, 如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。
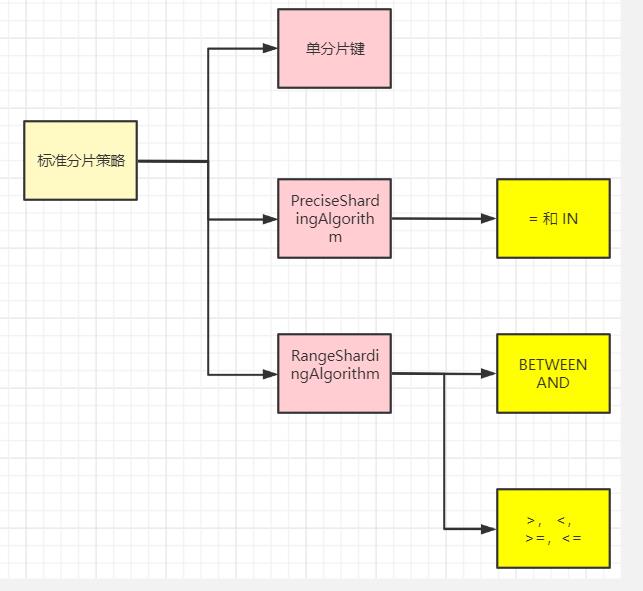
复合分片策略
复合分片策略对应 ComplexShardingStrategy。
同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。
不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
ComplexShardingStrategy ⽀持多分⽚键,由于多分⽚键之间的关系复杂,因此并未进⾏过多的封装,而是直接将分⽚键值组合以及分⽚操作符透传⾄分⽚算法,完全由应⽤开发者实现,提供最⼤的灵活度。
表达式分片策略(inline内联分片策略)
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。
这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
t_order_$->t_order_id % 4 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。
强制分片策略(Hint 暗示分片策略)
Hint 分片策略,通过指定分片健而非从 SQL 中提取分片健的方式进行分片的策略。
对于分⽚值⾮ SQL 决定,不是来自于分片建,甚至连分片建都没有 ,而由其他外置条件决定的场景,可使⽤Hint 分片策略 。
前面的分片策略都是解析 SQL 语句, 提取分片建和分片值,并根据设置的分片算法进行分片。
Hint 分片算法 指定分⽚值而⾮从 SQL 中提取,而是手工设置的⽅式,进⾏分⽚的策略。
例:内部系统,按照员⼯登录主键分库,而数据库中并⽆此字段。
不分⽚策略
对应 NoneShardingStrategy。不分⽚的策略。
这种严格来说不算是一种分片策略了。
只是ShardingSphere也提供了这么一个配置。
分片算法
上边我们提到可以用分片健取模的规则分片,但这只是比较简单的一种,
在实际开发中我们还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。
从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。
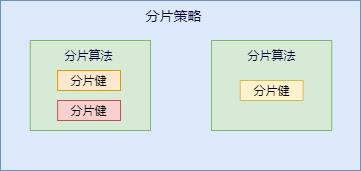
sharding-jdbc 提供了多种分片算法:
提供了抽象分片算法类:ShardingAlgorithm,根据类型又分为:精确分片算法、区间分片算法、复合分片算法以及Hint分片算法;
- 精确分片算法:对应
PreciseShardingAlgorithm类,主要用于处理=和IN的分片; - 区间分片算法:对应
RangeShardingAlgorithm类,主要用于处理BETWEEN AND,>,<,>=,<=分片; - 复合分片算法:对应
ComplexKeysShardingAlgorithm类,用于处理使用多键作为分片键进行分片的场景; - Hint分片算法:对应
HintShardingAlgorithm类,用于处理使用Hint行分片的场景;
精确分片算法 PreciseShardingAlgorithm
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,
需要配合 StandardShardingStrategy 使⽤。
范围分片算法 RangeShardingAlgorithm
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要需要配合 StandardShardingStrategy 使⽤。
复合分片算法 ComplexKeysShardingAlgorithm
对应 ComplexKeysShardingAlgorithm,⽤于处理使⽤ 多键作为分⽚键 进⾏分⽚的场景,
(多个字段作为分片键),同时获取到多个分片健的值,根据多个字段处理业务逻辑。
包含多个分⽚键的逻辑较复杂,需要应⽤开发者⾃⾏处理其中的复杂度。
需要配合 ComplexShardingStrategy 使⽤。
需要在复合分片策略(ComplexShardingStrategy )下使用。
Hint 分片算法 HintShardingAlgorithm
Hint 分片算法(HintShardingAlgorithm)稍有不同
前面的算法(如StandardShardingAlgorithm)都是解析 SQL 语句, 提取分片值,并根据设置的分片算法进行分片。
Hint 分片算法 指定分⽚值而⾮从 SQL 中提取,而是手工设置的⽅式,进⾏分⽚的策略。
对于分⽚值⾮ SQL 决定,不是来自于分片建,甚至连分片建都没有 ,而由其他外置条件决定的场景,可使⽤Hint 分片算法 。
就需要通过 Java API 等方式 指定 分片值,这也叫强制路由、或者说 暗示路由。
例: 内部系统,按照员⼯登录主键分库,而数据库中并⽆此字段。
SQL Hint ⽀持通过 Java API 和 SQL 注释(待实现)两种⽅式使⽤。
ShardingJDBC的分片策略
整个ShardingJDBC 分库分表的核心就是在于**配置 分片策略+分片算法 **。
我们的这些实战都是使用的inline分片算法,即提供一个分片键和一个分片表达式来制定分片算法。
这种方式配置简单,功能灵活,是分库分表最佳的配置方式,并且对于绝大多数的分库分片场景来说,都已经非常好用了。
但是,如果针对一些更为复杂的分片策略,例如多分片键、按范围分片等场景,inline分片算法就有点力不从心了。
所以,我们还需要学习下ShardingSphere提供的其他几种分片策略。
ShardingSphere目前提供了一共五种分片策略:
-
NoneShardingStrategy 不分片
-
InlineShardingStrategy
InlineShardingStrategy
最常用的分片方式
实现方式:
按照分片表达式来进行分片。
实战:JavaAPI使用InlineShardingStrategy 实战
Inline内联分片策略
分片策略基本和上面的分片算法对应,包括:标准分片策略、复合分片策略、Hint分片策略、内联分片策略、不分片策略;\\
- 内联分片策略:
对应InlineShardingStrategy类,没有提供分片算法,路由规则通过表达式来实现;
Inline内联分片配置类
在使用中我们并没有直接使用上面的分片策略类,ShardingSphere-JDBC分别提供了对应策略的配置类包括:
InlineShardingStrategyConfiguration
Inline内联分片实战
有了以上相关基础概念,接下来针对每种分片策略做一个简单的实战,
在实战前首先准备好库和表;
具体请参见视频,和配套源码
准备真实数据源
分别准备两个库:ds0、ds1;然后每个库分别包含4个表
CREATE TABLE `t_user_0` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
CREATE TABLE `t_user_1` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
CREATE TABLE `t_user_2` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
CREATE TABLE `t_user_3` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
我们这里有两个数据源,这里都使用java代码的方式来配置:
@Before
public void buildShardingDataSource() throws SQLException
/*
* 1. 数据源集合:dataSourceMap
* 2. 分片规则:shardingRuleConfig
*
*/
DataSource druidDs1 = buildDruidDataSource(
"jdbc:mysql://cdh1:3306/sharding_db1?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC",
"root", "123456");
DataSource druidDs2 = buildDruidDataSource(
"jdbc:mysql://cdh1:3306/sharding_db2?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC",
"root", "123456");
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
// 添加数据源.
// 两个数据源ds_0和ds_1
dataSourceMap.put("ds0",druidDs1);
dataSourceMap.put("ds1", druidDs2);
/**
* 需要构建表规则
* 1. 指定逻辑表.
* 2. 配置实际节点》
* 3. 指定主键字段.
* 4. 分库和分表的规则》
*
*/
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
//消息表分片规则
TableRuleConfiguration userShardingRuleConfig = userShardingRuleConfig();
shardingRuleConfig.getTableRuleConfigs().add(userShardingRuleConfig);
// 多数据源一定要指定默认数据源
// 只有一个数据源就不需要
shardingRuleConfig.setDefaultDataSourceName("ds0");
Properties p = new Properties();
//打印sql语句,生产环境关闭
p.setProperty("sql.show", Boolean.TRUE.toString());
dataSource= ShardingDataSourceFactory.createDataSource(
dataSourceMap, shardingRuleConfig, p);
这里配置的两个数据源都是普通的数据源,最后会把dataSourceMap交给ShardingDataSourceFactory管理;
表规则配置
表规则配置类TableRuleConfiguration,包含了五个要素:
逻辑表、真实数据节点、数据库分片策略、数据表分片策略、分布式主键生成策略;
/**
* 消息表的分片规则
*/
protected TableRuleConfiguration userShardingRuleConfig()
String logicTable = USER_LOGIC_TB;
//获取实际的 ActualDataNodes
String actualDataNodes = "ds$->0..1.t_user_$->0..1";
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration(logicTable, actualDataNodes);
//设置分表策略
// inline 模式
ShardingStrategyConfiguration tableShardingStrategy =
new InlineShardingStrategyConfiguration("user_id", "t_user_$->user_id % 2");
//自定义模式
// TableShardingAlgorithm tableShardingAlgorithm = new TableShardingAlgorithm();
// ShardingStrategyConfiguration tableShardingStrategy = new StandardShardingStrategyConfiguration("user_id", tableShardingAlgorithm);
tableRuleConfig.setTableShardingStrategyConfig(tableShardingStrategy);
// 配置分库策略(Groovy表达式配置db规则)
// inline 模式
ShardingStrategyConfiguration dsShardingStrategy = new InlineShardingStrategyConfiguration("user_id", "ds$user_id % 2");
//自定义模式
// DsShardingAlgorithm dsShardingAlgorithm = new DsShardingAlgorithm();
// ShardingStrategyConfiguration dsShardingStrategy = new StandardShardingStrategyConfiguration("user_id", dsShardingAlgorithm);
tableRuleConfig.setDatabaseShardingStrategyConfig(dsShardingStrategy);
tableRuleConfig.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "user_id"));
return tableRuleConfig;
-
逻辑表:这里配置的逻辑表就是t_user,对应的物理表有t_user_0,t_user_1;
-
真实数据节点:这里使用行表达式进行配置的,简化了配置;上面的配置就相当于配置了:
db0 ├── t_user_0 └── t_user_1 db1 ├── t_user_0 └── t_user_1 -
数据库分片策略:
这里的库分片策略就是上面介绍的五种类型,
这里使用的InlineShardingStrategy,需要设置 内联表达式,groovy表达式;
//设置分表策略 // inline 模式 ShardingStrategyConfiguration tableShardingStrategy = new InlineShardingStrategyConfiguration("user_id", "t_user_$->user_id % 2"); //自定义模式 // TableShardingAlgorithm tableShardingAlgorithm = new TableShardingAlgorithm(); // ShardingStrategyConfiguration tableShardingStrategy = new StandardShardingStrategyConfiguration("user_id", tableShardingAlgorithm); tableRuleConfig.setTableShardingStrategyConfig(tableShardingStrategy);这里的shardingValue就是user_id对应的真实值,每次和2取余;availableTargetNames可选择就是ds0,ds1;看余数和哪个库能匹配上就表示路由到哪个库;
-
数据表分片策略:指定的**分片键(order_id)**和分库策略不一致,其他都一样;
-
分布式主键生成策略:ShardingSphere-JDBC提供了多种分布式主键生成策略,后面详细介绍,这里使用雪花算法;
groovy语法说明
行表达式的使⽤⾮常直观,只需要在配置中使⽤ $ expression 或 $-> expression 标识 行表达式即可。
⽬前⽀持数据节点和分⽚算法这两个部分的配置。
行表达式的内容使⽤的是 Groovy 的语法,Groovy 能够⽀持的所有操作, 行表达式均能够⽀持。例如:
$begin…end 表⽰范围区间
$[unit1, unit2, unit_x] 表⽰枚举值
行表达式中如果出现连续多个 $ expression 或 $-> expression 表达式,整个表达式最终的结果将会根据每个表达式的结果进笛卡尔组合。
例如,以下⾏表达式:
[
′
o
n
l
i
n
e
′
,
′
o
f
f
l
i
n
e
′
]
t
a
b
l
e
['online', 'offline']_table
[′online′,以上是关于Sharding-JDBC 实战(史上最全)的主要内容,如果未能解决你的问题,请参考以下文章