翻译: 深入深度学习 2.3. 线性代数 pytorch
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译: 深入深度学习 2.3. 线性代数 pytorch相关的知识,希望对你有一定的参考价值。
现在您可以存储和操作数据,让我们简要回顾一下基本线性代数的子集,您将需要理解和实现本书中涵盖的大多数模型。下面,我们介绍线性代数中的基本数学对象、算术和运算,并通过数学符号和代码中的相应实现来表达它们。
2.3.1。标量
如果您从未学习过线性代数或机器学习,那么您过去的数学经验可能就是一次只考虑一个数字。而且,如果你曾经平衡过支票簿,甚至在餐厅支付过晚餐,那么你就已经知道如何做一些基本的事情,比如成对的数字相加和相乘。例如,帕洛阿尔托的温度是52华氏度。形式上,我们称仅由一个数值组成的值scalars。如果您想将此值转换为摄氏温度(公制系统更合理的温标),您将评估表达式 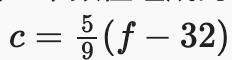
, 环境到. 在这个等式中,每一项——5,9, 和 32— 是标量值。占位符c和 f被称为变量,它们代表未知的标量值。
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x**y
(tensor(5.), tensor(6.), tensor(1.5000), tensor(9.))
2.3.2. 向量
您可以将向量视为简单的标量值列表。我们将这些值称为元素(条目或组件) 的向量。当我们的向量代表我们数据集中的示例时,它们的值具有一定的现实意义。例如,如果我们正在训练一个模型来预测贷款违约的风险,我们可能会将每个申请人与一个向量相关联,该向量的组成部分对应于他们的收入、工作年限、先前违约的数量和其他因素。如果我们正在研究医院患者可能面临的心脏病发作风险,我们可能会用一个向量来表示每个患者,该向量的成分捕捉他们最近的生命体征、胆固醇水平、每天的运动时间等。在数学符号中,我们通常表示以粗体、小写字母表示的向量(例如,x, y, 和z.
我们通过一维张量处理向量。一般来说,张量可以有任意长度,这取决于你机器的内存限制。
x = np.arange(4)
x
array([0., 1., 2., 3.])
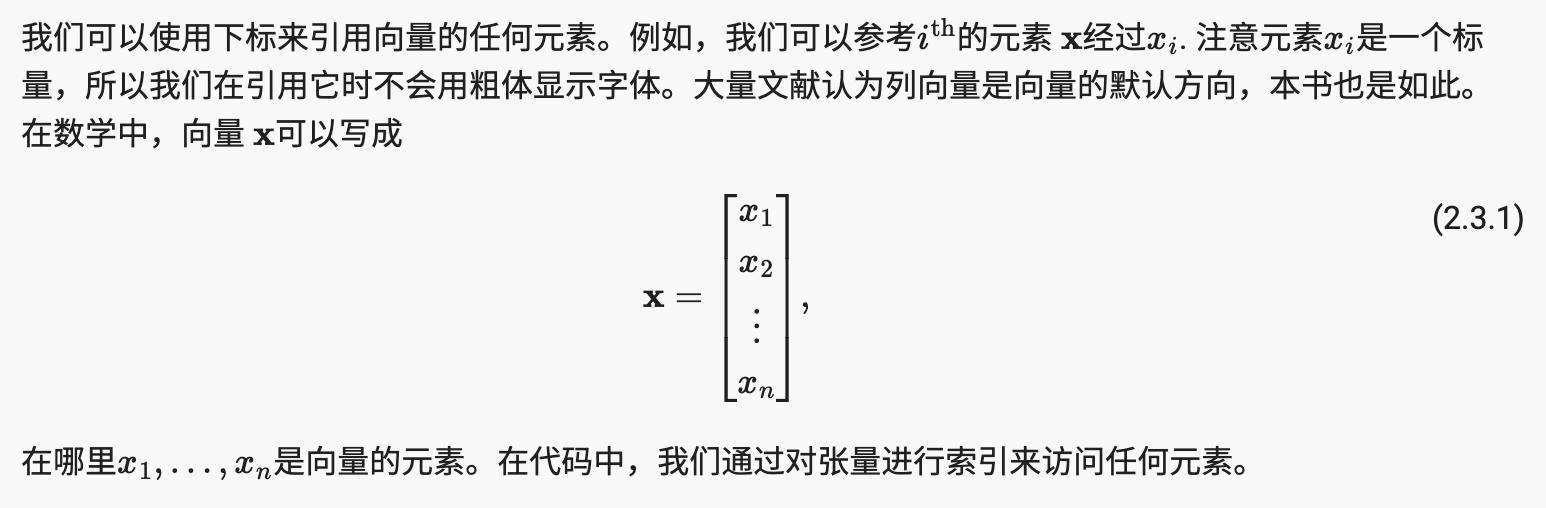
x[3]
array(3.)
2.3.2.1。长度、尺寸和形状
让我们重温第 2.1 节中的一些概念。向量只是一个数字数组。正如每个数组都有长度一样,每个向量也是如此。在数学符号中,如果我们想说一个向量 由组成实值标量,我们可以将其表示为
. 向量的长度通常称为向量的维数。
与普通的 Python 数组一样,我们可以通过调用 Python 的内置len()函数来访问张量的长度。
len(x)
4
当张量表示一个向量(恰好有一个轴)时,我们还可以通过.shape属性访问它的长度。形状是一个元组,它列出了沿张量每个轴的长度(维度)。对于只有一个轴的张量,形状只有一个元素。
x.shape
(4,)
请注意,“维度”一词在这些上下文中往往会变得超载,这往往会使人们感到困惑。为了澄清,我们使用向量或轴的维度来指代它的长度,即向量或轴的元素数。但是,我们使用张量的维度来指代张量具有的轴数。从这个意义上说,张量的某个轴的维度将是该轴的长度。
2.3.3。矩阵¶
正如向量将标量从零阶推广到一阶一样,矩阵将向量从一阶推广到二阶。矩阵,我们通常用粗体大写字母表示(例如,X,Y, 和Z),在代码中表示为具有两个轴的张量。

A = np.arange(20).reshape(5, 4)
A
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]])

A.T
array([[ 0., 4., 8., 12., 16.],
[ 1., 5., 9., 13., 17.],
[ 2., 6., 10., 14., 18.],
[ 3., 7., 11., 15., 19.]])
作为方阵的一种特殊类型,对称矩阵A等于它的转置: . 这里我们定义一个对称矩阵 B。
. 这里我们定义一个对称矩阵 B。
B = np.array([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B
array([[1., 2., 3.],
[2., 0., 4.],
[3., 4., 5.]])
现在我们B与它的转置进行比较。
B == B.T
array([[ True, True, True],
[ True, True, True],
[ True, True, True]])
矩阵是有用的数据结构:它们允许我们组织具有不同变化形式的数据。例如,我们矩阵中的行可能对应于不同的房屋(数据示例),而列可能对应于不同的属性。如果您曾经使用过电子表格软件或阅读过 第 2.2 节,这听起来应该很熟悉。因此,虽然单个向量的默认方向是列向量,但在表示表格数据集的矩阵中,将每个数据示例视为矩阵中的行向量更为常规。而且,正如我们将在后面的章节中看到的那样,这种约定将使常见的深度学习实践成为可能。例如,沿着张量的最外轴,我们可以访问或枚举数据示例的小批量,或者如果不存在小批量,则只访问数据示例。
2.3.4 张量Tensor
正如向量泛化标量,矩阵泛化向量一样,我们可以构建具有更多轴的数据结构。张量(本小节中的“张量”指代数对象)为我们提供了一种通用的描述方式n具有任意数量轴的维数组。例如,向量是一阶张量,矩阵是二阶张量。张量用特殊字体的大写字母表示(例如,X,Y, 和Z )及其索引机制
类似于矩阵。
当我们开始处理图像时,张量将变得更加重要,图像以n具有对应于高度、宽度和用于堆叠颜色通道(红色、绿色和蓝色)的通道轴的 3 个轴的维数组。现在,我们将跳过高阶张量并专注于基础知识。
X = np.arange(24).reshape(2, 3, 4)
X
array([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]]])
2.3.5。张量算术的基本性质
任意数量轴的标量、向量、矩阵和张量(本小节中的“张量”指代数对象)具有一些很好的属性,这些属性通常会派上用场。例如,您可能已经从元素运算的定义中注意到,任何元素一元运算都不会改变其操作数的形状。类似地,给定任何两个具有相同形状的张量,任何二元元素运算的结果都将是具有相同形状的张量。例如,添加两个相同形状的矩阵会在这两个矩阵上执行元素相加。
A = np.arange(20).reshape(5, 4)
B = A.copy() # Assign a copy of `A` to `B` by allocating new memory
A, A + B
(array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]]),
array([[ 0., 2., 4., 6.],
[ 8., 10., 12., 14.],
[16., 18., 20., 22.],
[24., 26., 28., 30.],
[32., 34., 36., 38.]]))

A * B
array([[ 0., 1., 4., 9.],
[ 16., 25., 36., 49.],
[ 64., 81., 100., 121.],
[144., 169., 196., 225.],
[256., 289., 324., 361.]])
将张量与标量相乘或相加也不会改变张量的形状,其中操作数张量的每个元素都将与标量相加或相乘。
a = 2
X = np.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape
(array([[[ 2., 3., 4., 5.],
[ 6., 7., 8., 9.],
[10., 11., 12., 13.]],
[[14., 15., 16., 17.],
[18., 19., 20., 21.],
[22., 23., 24., 25.]]]),
(2, 3, 4))
2.3.6 聚合函数

x = np.arange(4)
x, x.sum()
(array([0., 1., 2., 3.]), array(6.))

A.shape, A.sum()
((5, 4), array(190.))
默认情况下,调用计算总和的函数会将沿其所有轴的张量减少为标量。我们还可以通过求和指定张量减少的轴。以矩阵为例。为了通过汇总所有行的元素来减少行维度(轴 0),我们axis=0在调用函数时指定。由于输入矩阵沿轴 0 减少以生成输出向量,因此输入的轴 0 的维度在输出形状中丢失。
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape
(array([40., 45., 50., 55.]), (4,))
指定axis=1将通过汇总所有列的元素来减少列维度(轴 1)。因此,输入的轴 1 的维度在输出形状中丢失了。
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape
(array([ 6., 22., 38., 54., 70.]), (5,))
通过求和沿行和列减少矩阵等效于对矩阵的所有元素求和。
A.sum(axis=[0, 1]) # Same as `A.sum()`
array(190.)
一个相关的量是平均值,也称为平均值。我们通过将总和除以元素总数来计算平均值。在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(), A.sum() / A.size
(array(9.5), array(9.5))
同样,计算平均值的函数也可以减少沿指定轴的张量。
A.mean(axis=0), A.sum(axis=0) / A.shape[0]
(array([ 8., 9., 10., 11.]), array([ 8., 9., 10., 11.]))
2.3.6.1 运算后保持维度¶
但是,有时在调用计算总和或平均值的函数时保持轴数不变会很有用。
sum_A = A.sum(axis=1, keepdims=True)
sum_A
array([[ 6.],
[22.],
[38.],
[54.],
[70.]])
例如,由于sum_A在对每一行求和后仍然保持它的两个轴,我们可以用广播A除以。sum_A
A / sum_A
array([[0. , 0.16666667, 0.33333334, 0.5 ],
[0.18181819, 0.22727273, 0.27272728, 0.3181818 ],
[0.21052632, 0.23684211, 0.2631579 , 0.28947368],
[0.22222222, 0.24074075, 0.25925925, 0.2777778 ],
[0.22857143, 0.24285714, 0.25714287, 0.27142859]])
如果我们想计算A沿某个轴的元素的累积和,比如说axis=0(逐行),我们可以调用该cumsum 函数。此函数不会减少沿任何轴的输入张量。
A.cumsum(axis=0)
array([[ 0., 1., 2., 3.],
[ 4., 6., 8., 10.],
[12., 15., 18., 21.],
[24., 28., 32., 36.],
[40., 45., 50., 55.]])
2.3.7。点积

y = np.ones(4)
x, y, np.dot(x, y)
(array([0., 1., 2., 3.]), array([1., 1., 1., 1.]), array(6.))
请注意,我们可以通过执行元素乘法然后求和来等效地表示两个向量的点积:
np.sum(x * y)
array(6.)

2.3.8 矩阵向量积

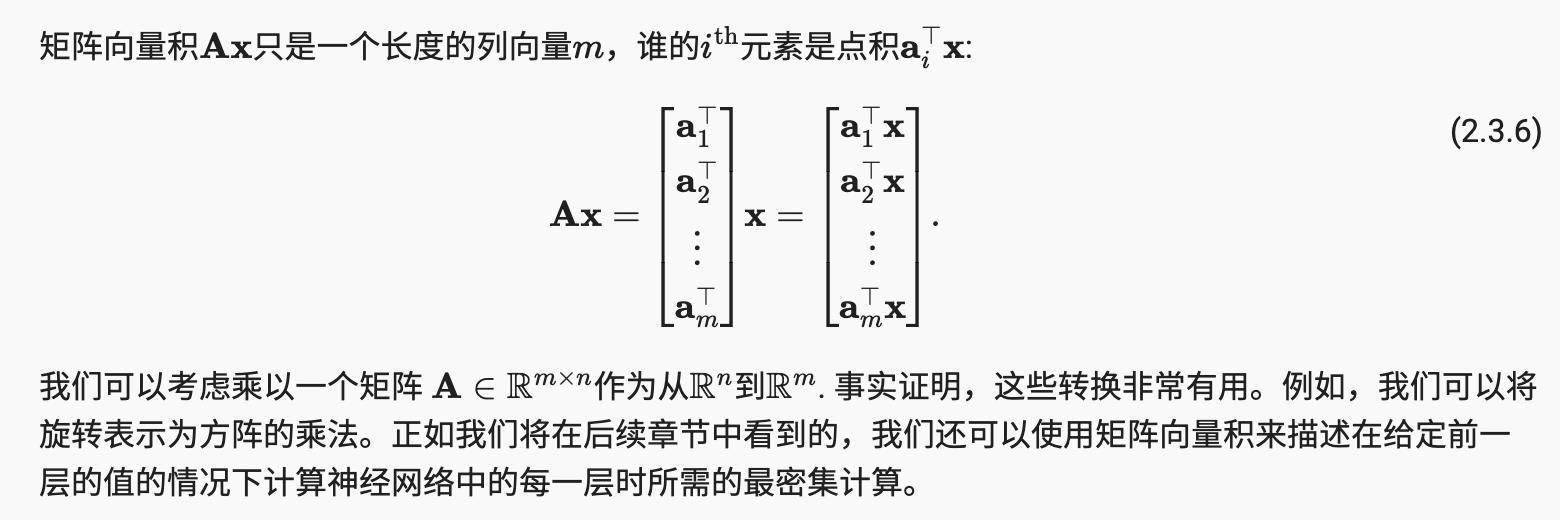
用张量在代码中表达矩阵向量乘积,我们使用该 mv函数。当我们调用一个矩阵和一个向量时,执行矩阵-向量乘积。请注意,(其沿轴 1 的长度)的列尺寸必须与(其长度)的尺寸相同。torch.mv(A, x)
A.shape, x.shape, torch.mv(A, x)
(torch.Size([5, 4]), torch.Size([4]), tensor([ 14., 38., 62., 86., 110.]))
2.3.9 矩阵-矩阵乘法
如果您已经掌握了点积和矩阵-向量积的窍门,那么矩阵-矩阵乘法应该很简单。



B = torch.ones(4, 3)
torch.mm(A, B)
tensor([[ 6., 6., 6.],
[22., 22., 22.],
[38., 38., 38.],
[54., 54., 54.],
[70., 70., 70.]])
矩阵-矩阵乘法可以简单地称为矩阵乘法,不应与 Hadamard 乘积相混淆。
2.3.10 范数
线性代数中一些最有用的算子是范数。非正式地,向量的范数告诉我们向量有多大。这里考虑的大小概念不是维度,而是组件的大小。
在线性代数中,向量范数是一个函数f将向量映射到标量,满足一些属性。给定任何向量x ,第一个属性表示,如果我们将向量的所有元素缩放一个常数因子a,其范数也按相同常数因子的绝对值缩放:
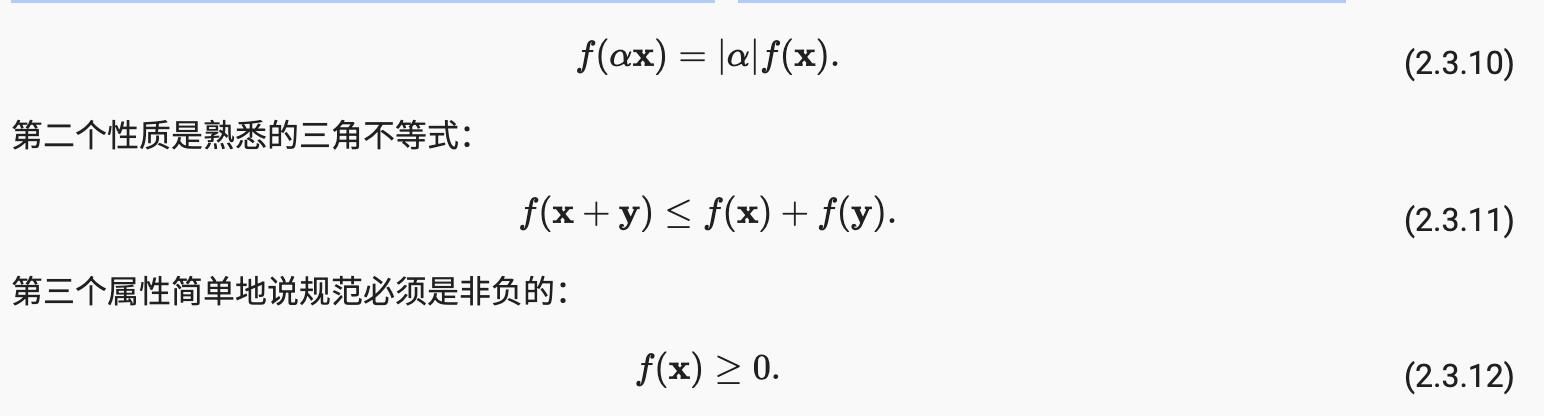

u = torch.tensor([3.0, -4.0])
torch.norm(u)
tensor(5.)

torch.abs(u).sum()
tensor(7.)

torch.norm(torch.ones((4, 9)))
tensor(6.)
2.3.10.1 范数和目标
虽然我们不想过于超前,但我们已经可以对这些概念为何有用有了一些直觉。在深度学习中,我们经常尝试解决优化问题:最大化 分配给观察数据的概率;最小化预测和真实观测之间的距离。将向量表示分配给项目(如单词、产品或新闻文章),使相似项目之间的距离最小化,而不同项目之间的距离最大化。通常,目标,也许是深度学习算法最重要的组成部分(除了数据),被表示为规范。
2.3.11 更多关于线性代数
在本节中,我们已经教给你所有的线性代数,你需要了解现代深度学习的重要部分。线性代数还有很多,其中很多数学对机器学习很有用。例如,矩阵可以分解为因子,这些分解可以揭示现实世界数据集中的低维结构。机器学习的整个子领域都专注于使用矩阵分解及其对高阶张量的推广来发现数据集中的结构并解决预测问题。但这本书侧重于深度学习。我们相信,一旦您开始在真实数据集上部署有用的机器学习模型,您将更倾向于学习更多数学知识。
如果您渴望了解更多关于线性代数的知识,您可以参考关于线性代数运算的在线附录 或其他优秀资源
2.3.12 总结
-
标量、向量、矩阵和张量是线性代数中的基本数学对象。
-
向量泛化标量,矩阵泛化向量。
-
标量、向量、矩阵和张量分别具有零、一、二和任意数量的轴。
-
可以通过sum和 沿指定轴减少张量mean.
-
两个矩阵的元素乘法称为它们的 Hadamard 乘积。它与矩阵乘法不同。
-
在深度学习中,我们经常使用诸如L1 范数 L2范数和 Frobenius 范数。
-
我们可以对标量、向量、矩阵和张量执行各种操作。
2.3.13 练习

参考
https://d2l.ai/chapter_preliminaries/linear-algebra.html
以上是关于翻译: 深入深度学习 2.3. 线性代数 pytorch的主要内容,如果未能解决你的问题,请参考以下文章