深入浅出Yolov5之自有数据集训练超详细教程
Posted 浩瀚之水_csdn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出Yolov5之自有数据集训练超详细教程相关的知识,希望对你有一定的参考价值。
除了本文,大白还整理了如何深入浅出人工智能行业,算法、数据、目标检测、论文创新点、求职等版块的内容,可以查看:点击查看。
此外本文章Yolov5相关的代码、模型、数据等内容,可以查看下载:点击查看。
当然下方也列出了,如何通过官方链接的方式,下载的过程,也可以查看。
1 下载Yolov5代码及模型权重
1.1 下载Yolov5代码
登录github链接:https://github.com/ultralytics/yolov5,下载完整的代码。
1.2 下载Yolov5模型权重
在Yolov5模型权重页面,https://github.com/ultralytics/yolov5/releases
在下方选择相应的Yolov5各个pt权重文件。
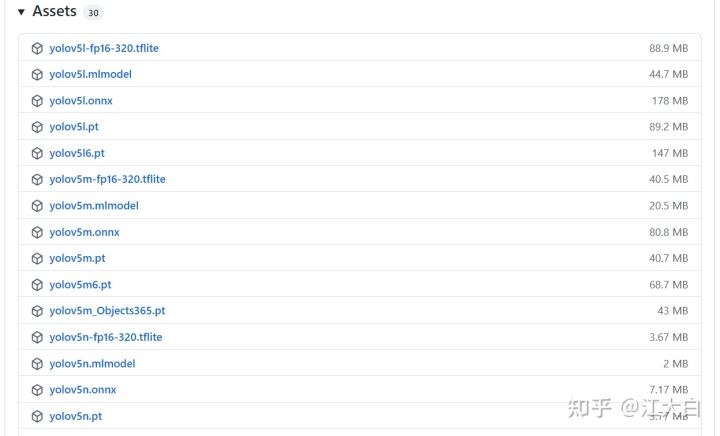
放在Yolov5代码的models文件夹中。

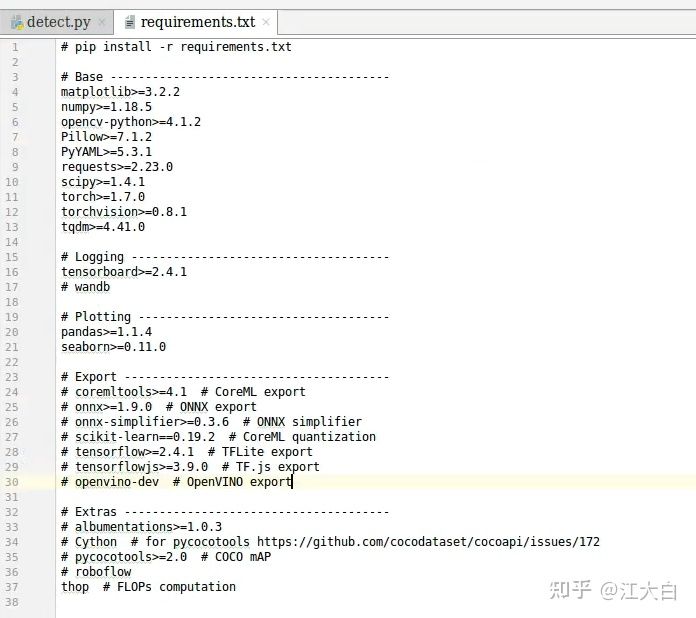
2 下载一系列的依赖库
按照yolov5代码中requirements.txt中的说明,下载一系列的依赖库
3 对于推理功能进行测试
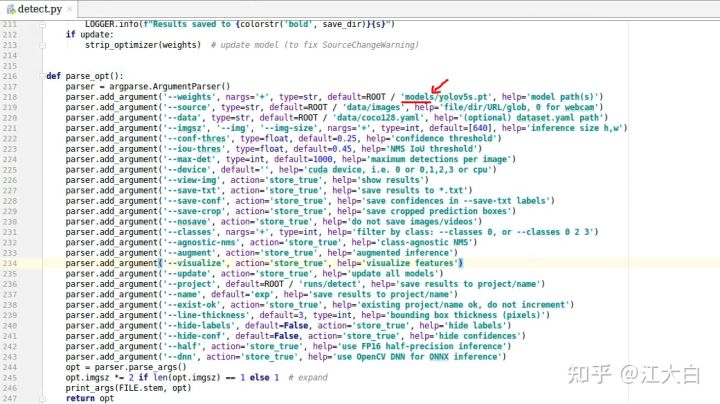
先使用预训练的模型,对于图片进行推理测试,看看效果。
修改detect.py里面的weights的路径,增加前面的models文件夹的路径。
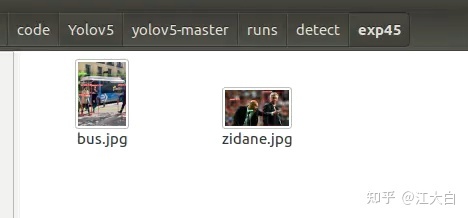
运行结束后,可以在运行结果看到信息:

打开runs/detect/exp可以看到推理得到的结果:
4 使用自有数据进行训练
4.1 数据&脚本&训练代码
大白为了让大家从0基础,就可以学会训练,准备了三个文件。
(1)data:人头数据集
为了便于大家学习,大白准备了一个教室场景下的人头数据集,放在data/head/classroom文件夹中。
数据集中,JPEGImages有4361张图片,Annotations有4361张xml文件。
(2)train_code:数据处理脚本
在train_code文件夹中,有三个python文件,主要使用的是get_labels.py和main.py两个脚本。
get_labels.py脚本,可以直接获取Annotations文件夹中,所有标注文件的标注类别。
而main.py脚本,可以将之前标注文件和图像,进行处理,转换成Yolov5可以训练的格式。
(3)yolov5-master:训练代码
这个文件夹里面就是Yolov5的训练测试代码,大家也可以直接使用大白提供的Yolov5代码。
4.2 查看自有数据集中的类别数
打开train_code/get_labels.py,修改下方的人头数据集路径。
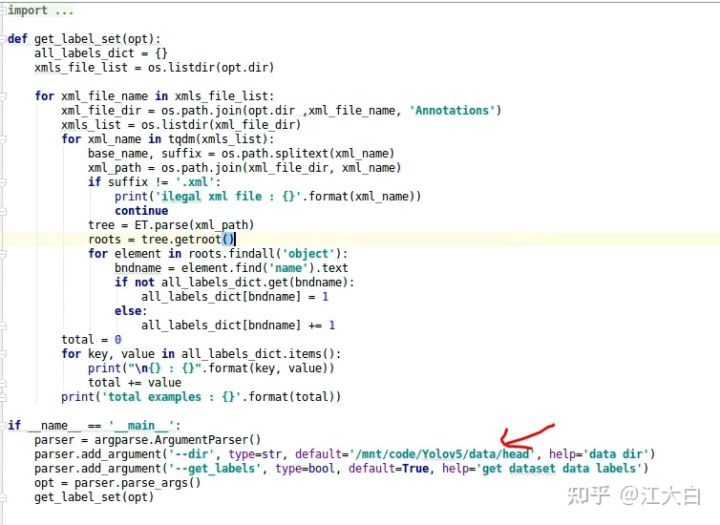
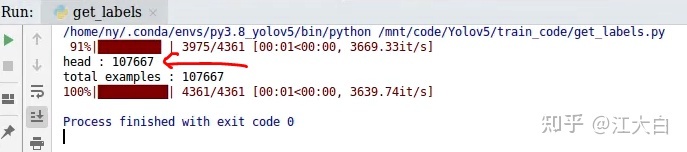
运行后,在下方就可以看到类别数,以及标注的类别框的数量。
4.3 转换训练数据格式
(1)新建数据集转换文件夹
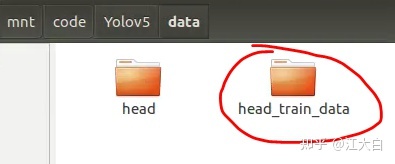
首先在data文件夹里面,新建一个head_train_data文件夹。
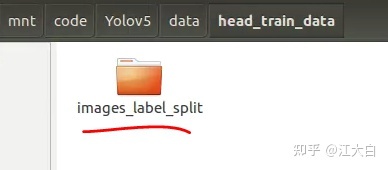
并在head_train_data文件夹中,新建一个images_label_split文件夹。
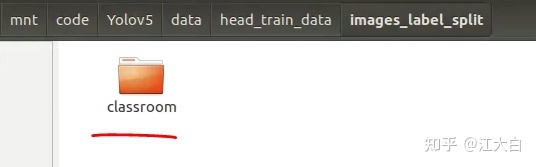
并将前面的classroom数据集,直接拷贝到images_label_split里面。
(2)main.py脚本处理:配置修改
打开train_code/main.py文件,修改训练数据的路径。

在前面通过get_labels.py脚本,我们也知道了当前数据集的类别数,比如主要是“head”,将该类别填入label_list中。
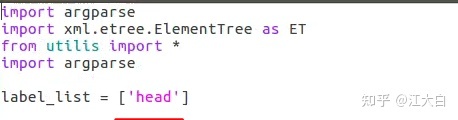
而main.py文件主要分为三个部分的功能:数据集的清洗、训练集&验证集划分、xml转换txt格式。
(3)main.py脚本处理:数据集清洗
数据集的清洗使用的主要是这些行的代码。

有的数据集有图片,没有标注文件。有的数据集有标注文件,图片有可能丢失。
同时将长宽比太小的框删除掉,并且在删除后,检查下是否存在空的标注文件,如果有,也删除。
并在最后,将标注的框显示到图片上,进一步确定脚本是否正确。
运行上面的代码,最后会跳出来一些画了人头框的图片。

(4)main.py脚本处理:训练集&验证集划分
训练集&验证集划分的代码主要是这一行代码。

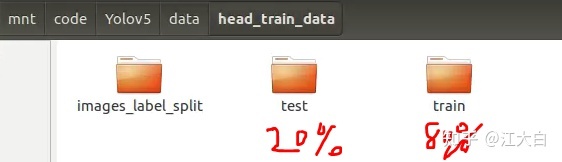
0.2表示,80%的数据进行训练,20%的数据进行验证。
运行结束后,会发现head_train_data这个文件夹下面多了两个文件夹,train和test,就是按照80%、20%进行划分。
(5)main.py脚本处理::xml转换txt格式
xml转换成txt格式的代码主要是下面三行。

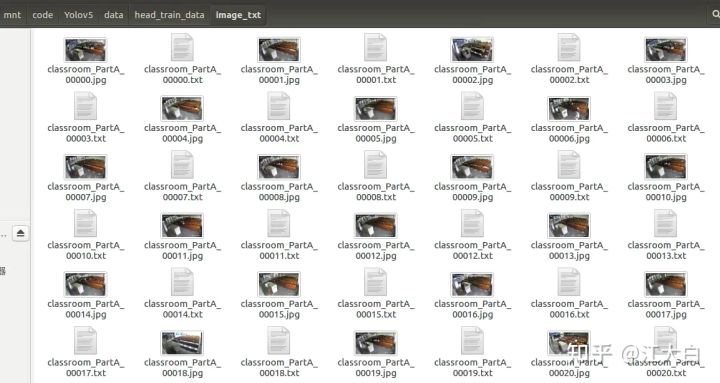
运行结束后,可以看到多了两个文件夹。

image_txt文件夹中是所有的image和转换完的txt文件、
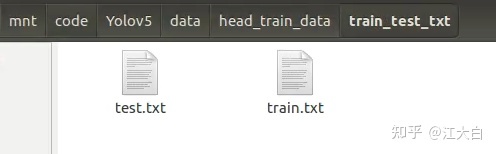
而train_test_txt文件夹中,则是对于训练和测试数据路径汇总的两个txt,后面训练中会用到。
4.4 Yolov5代码训练
4.4.1 修改训练配置
(1)新建一个yaml文件
因为是训练人头数据集,所以在data文件夹下先新建一个head.yaml文件,并修改其中的参数。
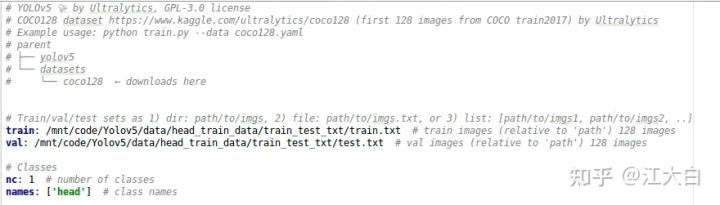
可以复制一个coco.yaml文件进行修改,其中主要涉及到训练集的txt文件、验证集的txt文件、类别数量nc、类别标签名。
(2)修改train.py参数
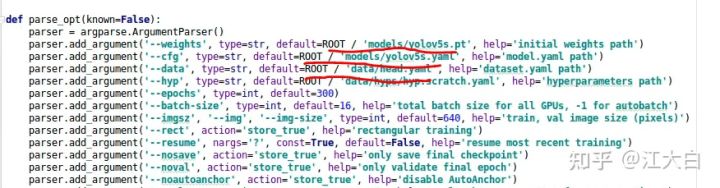
① 修改models里面的weights路径,大白下载了一些pt文件放在models中,可以选择使用。
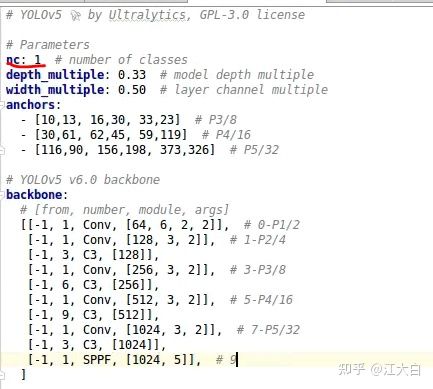
② 修改cfg路径,即网络结构的参数配置文件,需要注意的是,需要修改其中的类别数。
③ 修改data的路径,即前面修改的head.yaml文件。
4.4.2 开始训练
运行train.py文件,既可以开始训练。

可以看到网络收敛的很快。
4.4.3 训练结果测试
网络训练到一段时间后,可以使用detect.py脚本对于训练的模型,进行测试了,不过需要修改是三个参数:
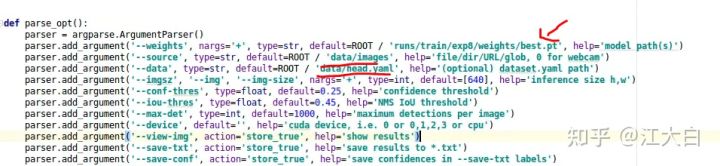
① weights:即前面训练好得到的权重文件
② source:即需要检测的图片数据集
③ data:修改成head.yaml
运行detect.py文件后,可以在runs/detect/exp最后一个文件夹中得到检测的效果图片:

以上就是Yolov5的详细训练过程,其中每一步大白都是经过详细的测试的,可以下载对应的代码、权重,进行尝试。
以上是关于深入浅出Yolov5之自有数据集训练超详细教程的主要内容,如果未能解决你的问题,请参考以下文章