LazyProphet:使用 LightGBM 进行时间序列预测
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LazyProphet:使用 LightGBM 进行时间序列预测相关的知识,希望对你有一定的参考价值。
当我们考虑时间序列的增强树时,通常会想到 M5 比赛,其中前十名中有很大一部分使用了 LightGBM。但是当在单变量情况下使用增强树时,由于没有大量的外生特征可以利用,它的性能非常的糟糕。
首先需要明确的是M4 比赛的亚军 DID 使用了增强树。但是它作为一个元模型来集成其他更传统的时间序列方法。在 M4 上公开的代码中,所有标准增强树的基准测试都相当糟糕,有时甚至还达不到传统的预测方法。下面是Sktime 包和他们的论文所做的出色工作[1]:
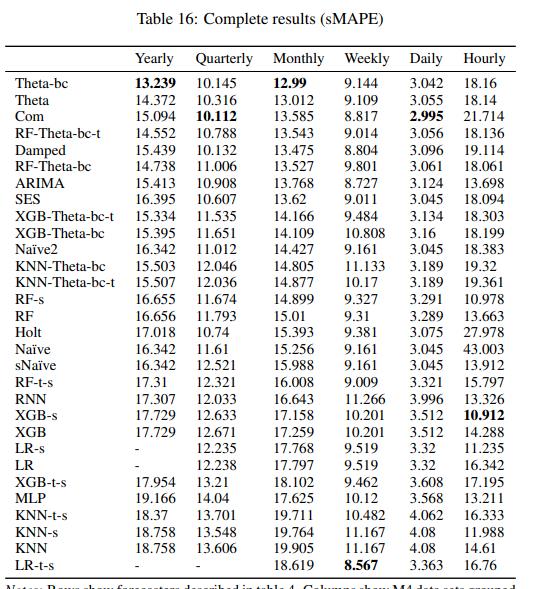
任何带有“XGB”或“RF”的模型都使用基于树的集成。在上面的列表中 Xgboost 在每小时数据集中提供了 10.9 的最佳结果!然后,但是这些模型只是Sktime 在他们框架中做过的简单尝试,而 M4 的获胜者在同一数据集上的得分是 9.3 分……。在该图表中我们需要记住一些数字,例如来自 XGB-s 的每小时数据集的 10.9 和每周数据集中的树性模型的“最佳”结果:来自 RF-t-s 的 9.0。
从上图中就引出了我们的目标:创建一个基于LightGBM并且适合个人使用的时间序列的快速建模程序,并且能够绝对超越这些数字,而且在速度方面可与传统的统计方法相媲美。
听起来很困难,并且我们的第一个想法可能是必须优化我们的树。但是提升树非常复杂,改动非常费时,并且结果并不一定有效。但是有一点好处是我们正在拟合是单个数据集,是不是可从特征下手呢?
推荐文章
特征
在查看单变量空间中树的其他实现时都会看到一些特征工程,例如分箱、使用目标的滞后值、简单的计数器、季节性虚拟变量,也许还有傅里叶函数。这对于使用传统的指数平滑等方法是非常棒的。但是我们今天目的是必须对时间元素进行特征化并将其表示为表格数据以提供给树型模型,LazyProphet这时候就出现了。除此以外,LazyProphet还包含一个额外的特征工程元素:将点”连接”起来。
很简单,将时间序列的第一个点连接起来,并将一条线连接到中途的另一个点,然后将中途的点连接到最后一个点。重复几次,同时更改将哪个点用作“kink”(中间节点),这就是我们所说的“连接”。
下面张图能很好地说明这一点。蓝线是时间序列,其他线只是“连接点”:
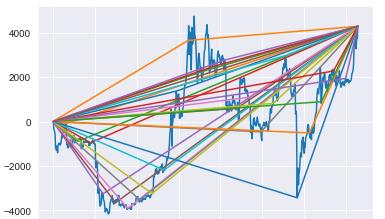
事实证明,这些只是加权分段线性基函数。这样做的一个缺点是这些线的外推可能会出现偏差。为了解决这个问题,引入一个惩罚从中点到最后点的每条线的斜率的“衰减”因子。
在这个基础上加滞后的目标值和傅里叶基函数,在某些问题上就能够接近最先进的性能。因为要求很少,因因此我们把它称作“LazyProphet”。
下面我们看看实际的应用结果。
代码
这里使用的数据集都是开源的,并在M-competitions github上发布。数据已经被分割为训练和测试集,我们直接使用训练csv进行拟合,而测试csv用于使用SMAPE进行评估。现在导入LazyProphet:
pip install LazyProphet
安装后,开始编码:
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
import pandas as pd
from LazyProphet import LazyProphet as lp
train_df = pd.read_csv(r'm4-weekly-train.csv')
test_df = pd.read_csv(r'm4-weekly-test.csv')
train_df.index = train_df['V1']
train_df = train_df.drop('V1', axis = 1)
test_df.index = test_df['V1']
test_df = test_df.drop('V1', axis = 1)
导入所有必要的包后将读入每周数据。创建 SMAPE 函数,它将返回给定预测和实际值的 SMAPE:
def smape(A, F):
return 100/len(A) * np.sum(2 * np.abs(F - A) / (np.abs(A) + np.abs(F)))
对于这个实验将取所有时间序列的平均值与其他模型进行比较。为了进行健全性检查,我们还将获得的平均 SMAPE,这样可以确保所做的与比赛中所做的一致。
smapes = []
naive_smape = []
j = tqdm(range(len(train_df)))
for row in j:
y = train_df.iloc[row, :].dropna()
y_test = test_df.iloc[row, :].dropna()
j.set_description(f'np.mean(smapes), np.mean(naive_smape)')
lp_model = LazyProphet(scale=True,
seasonal_period=52,
n_basis=10,
fourier_order=10,
ar=list(range(1, 53)),
decay=.99,
linear_trend=None,
decay_average=False)
fitted = lp_model.fit(y)
predictions = lp_model.predict(len(y_test)).reshape(-1)
smapes.append(smape(y_test.values, pd.Series(predictions).clip(lower=0)))
naive_smape.append(smape(y_test.values, np.tile(y.iloc[-1], len(y_test))))
print(np.mean(smapes))
print(np.mean(naive_smape))
在查看结果之前,快速介绍一下 LazyProphet 参数。
-
scale:这个很简单,只是是否对数据进行缩放。默认值为 True 。
-
seasonal_period:此参数控制季节性的傅立叶基函数,因为这是我们使用 52 的每周频率。
-
n_basis:此参数控制加权分段线性基函数。这只是要使用的函数数量的整数。
-
Fourier_order:用于季节性的正弦和余弦对的数量。
-
ar:要使用的滞后目标变量值。可以获取多个列表 1-52 。
-
decay:衰减因子用于惩罚我们的基函数的“右侧”。设置为 0.99 表示斜率乘以 (1- 0.99) 或 0.01。
-
linear_trend:树的一个主要缺点是它们无法推断出后续数据的范围。为了克服这个问题,有一些针对多项式趋势的现成测试将拟合线性回归以消除趋势。None 表示有测试,通过 True 表示总是去趋势,通过 False 表示不测试并且不使用线性趋势。
-
decay_average:在使用衰减率时不是一个有用的参数。这是一个trick但不要使用它。传递 True 只是平均基函数的所有未来值。这在与 elasticnet 程序拟合时很有用,但在测试中对 LightGBM 的用处不大。
下面继续处理数据:
train_df = pd.read_csv(r'm4-hourly-train.csv')
test_df = pd.read_csv(r'm4-hourly-test.csv')
train_df.index = train_df['V1']
train_df = train_df.drop('V1', axis = 1)
test_df.index = test_df['V1']
test_df = test_df.drop('V1', axis = 1)
smapes = []
naive_smape = []
j = tqdm(range(len(train_df)))
for row in j:
y = train_df.iloc[row, :].dropna()
y_test = test_df.iloc[row, :].dropna()
j.set_description(f'np.mean(smapes), np.mean(naive_smape)')
lp_model = LazyProphet(seasonal_period=[24,168],
n_basis=10,
fourier_order=10,
ar=list(range(1, 25)),
decay=.99)
fitted = lp_model.fit(y)
predictions = lp_model.predict(len(y_test)).reshape(-1)
smapes.append(smape(y_test.values, pd.Series(predictions).clip(lower=0)))
naive_smape.append(smape(y_test.values, np.tile(y.iloc[-1], len(y_test))))
print(np.mean(smapes))
print(np.mean(naive_smape))
所以真正需要修改是seasonal_period 和ar 参数。将list传递给seasonal_period 时,它将为列表中的所有内容构建季节性基函数。ar 进行了调整以适应新的主要季节 24。
结果
对于上面的 Sktime 结果,表格如下:
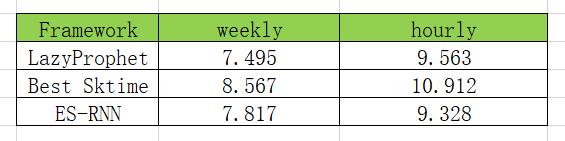
LazyProphet 击败了 Sktime 最好的模型,其中包括几种不同的基于树的方法。在每小时数据集上输给给了 M4 的获胜者,但平均而言总体上优于 ES-RNN。这里要意识到的重要一点是,只使用默认参数进行了此操作……
boosting_params =
"objective": "regression",
"metric": "rmse",
"verbosity": -1,
"boosting_type": "gbdt",
"seed": 42,
'linear_tree': False,
'learning_rate': .15,
'min_child_samples': 5,
'num_leaves': 31,
'num_iterations': 50
可以在创建 LazyProphet 类时传递你参数的字典,可以针对每个时间序列进行优化,以获得更多收益。
对比一下我们的结果和上面提到的目标:
-
进行了零参数优化(针对不同的季节性稍作修改)
-
分别拟合每个时间序列
-
在我的本地机器上在一分钟内“懒惰地”生成了预测。
-
在基准测试中击败了所有其他树方法
目前看是非常成功的,但是成功可能无法完全的复制,因为他数据集的数据量要少得多,因此我们的方法往往会显着降低性能。根据测试LazyProphet 在高频率和大量数据量上表现的更好,但是LazyProphet还是一个时间序列建模的很好选择,我们不需要花多长时间进行编码就能够测试,这点时间还是很值得。
引用:
[1] Markus Löning, Franz Király: “Forecasting with sktime: Designing sktime’s New Forecasting API and Applying It to Replicate and Extend the M4 Study”, 2020; arXiv:2005.08067
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于LazyProphet:使用 LightGBM 进行时间序列预测的主要内容,如果未能解决你的问题,请参考以下文章
详解基于 LightGBM 与傅里叶基函数的 LazyProphet 原理和实践 | 快速做单变量时间序列预测