特征提取基于matlab自相关函数最大值端点检测含Matlab源码 1769期
Posted 紫极神光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征提取基于matlab自相关函数最大值端点检测含Matlab源码 1769期相关的知识,希望对你有一定的参考价值。
一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【特征提取】基于matlab自相关函数最大值端点检测【含Matlab源码 1769期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、语音端点检测简介
1 概述
语音信号是一种短时平稳信号,即时变的,十分复杂,携带很多有用的信息,这些信息包
括语义、个人特征等,其特征参数的准确性和唯一性将直接影响语音识别率的高低,并且这也是语音识别的基础。特征参数应该能够比较准确地表达语音信号的特征,具有一定的唯一性。
20世纪40年代, Potter等人提出了“Visible speech”的概念, 指出语谱图对语音信号有很强的描述能力,并且试着用语谱信息进行语音识别,这形成了最早的语音特征,直到现
在仍有很多人用语谱特征来进行语音识别。后来,人们发现利用语音信号的时域特征可以从语音波形中提取某些反映语音特性的参数,比如短时幅度、短时帧平均能量、短时帧过零率、短时自相关系数、平均幅度差函数等。这些参数不但能减小模板数目运算量及存储量,而且还可以滤除语音信号中无用的冗余信息。语音信号特征参数是分帧提取的,每帧特征参数一般构成一个矢量,所以语音信号特征是一个矢量序列。语音信号特征提取的基础是分帧,将语音信号切成一帧一帧,每帧大小大约是20~30ms。帧太大就不能得到语音信号随时间变化的特性,帧太小就不能提取出语音信号的特征,每帧语音信号中包含数个语音信号的基本周期。有时希望相邻帧之间的变化不是太大,帧之间就要有重叠,帧叠往往是帧长的1/2或1/3帧叠大,相应的计算量也大。随着语音识别技术的不断发展,时域特征参数的种种不足逐渐暴露出来,如这些特征参数缺乏较好的稳定性且区分能力不好。于是,频域参数开始作为语音信号的特征,如频谱共振峰等。
相比于分帧处理,端点检测在语音信号处理中也占有十分重要的地位,直接影响着系统
的性能。语音端点检测是指从一段语音信号中准确地找出语音信号的起始点和结束点,它的目的是为了使有效的语音信号和无用的噪声信号得以分离,因此在语音识别、语音增强、语音编码、回声抵消等系统中得到广泛应用。目前端点检测方法大体上可以分成两类,一类是基于阈值的方法,该方法根据语音信号和噪声信号的不同特征,提取每一段语音信号的特征,然后把这些特征值与设定的阈值进行比较,从而达到语音端点检测的目的该方法原理简单,运算方便,所以被人们广泛使用。另一类方法是基于模式识别的方法,需要估计语音信号和噪声信号的模型参数来进行检测。由于基于模式识别的方法自身复杂度高,运算量大,因此很难被人们应用到实时语音信号系统中去。
2 端点检测
2.1双门限法
语音端点检测本质上是根据语音和噪声的相同参数所表现出的不同特征来进行区分。传
统的短时能量和过零率相结合的语音端点检测算法利用短时过零率来检测清音,用短时能量来检测浊音,两者相配合便实现了信号信噪比较大情况下的端点检测。算法以短时能量检测为主,短时过零率检测为辅。根据语音的统计特性,可以把语音段分为清音、浊音以及静音(包括背景噪声)三种。
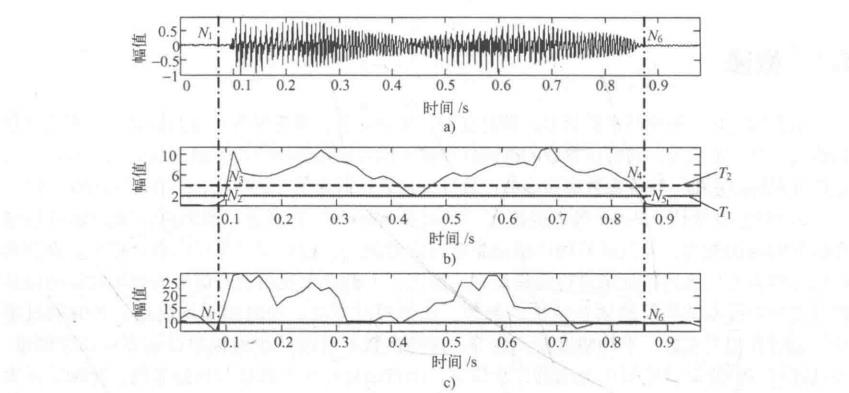
图5-1双门限法端点检测的二级判决示意图
(1)短时能量
设第n帧语音信号x,(m)的短时能量用E,表示,则其计算公式如下:
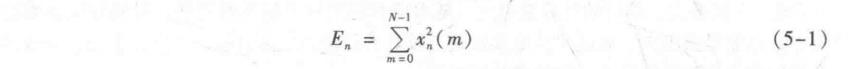
E,是一个度量语音信号幅度值变化的函数,但它有一个缺陷,即它对高电平非常敏感
(因为它计算时用的是信号的平方)。
(2)短时过零率
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。对于连续语音信号,过零即意味着时域波形通过时间轴;而对于离散信号,如果相邻的取样值改变符号则称为过零。因此,过零率就是样本改变符号的次数。
定义语音信号x,(m)的短时过零率Z,为
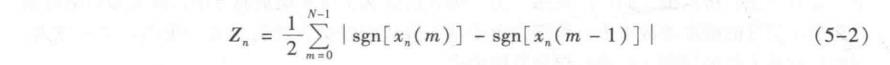
式中, sgn[·] 是符号函数, 即
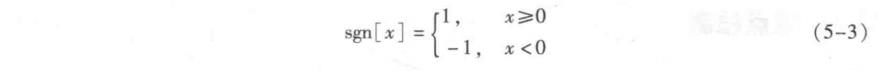
(3)双门限法
在双门限算法中,短时能量检测可以较好地区分出浊音和静音。对于清音,由于其能量
较小,在短时能量检测中会因为低于能量门限而被误判为静音;短时过零率则可以从语音中区分出静音和清音。将两种检测结合起来,就可以检测出语音段(清音和浊音)及静音段。在基于短时能量和过零率的双门限端点检测算法中首先为短时能量和过零率分别确定两个门限,一个为较低的门限,对信号的变化比较敏感,另一个是较高的门限。当低门限被超过时,很有可能是由于很小的噪声所引起的,未必是语音的开始,当高门限被超过并且在接下来的时间段内一直超过低门限时,则意味着语音信号的开始。
双门限法进行端点检测步骤如下:
1)计算信号的短时能量和短时平均过零率。
2)根据语音能量的轮廓选取一个较高的门限T,,语音信号的能量包络大部分都在此门限之上,这样可以进行一次初判。语音起止点位于该门限与短时能量包络交点N,和N,所对应的时间间隔之外。
3)根据背景噪声的能量确定一个较低的门限T,并从初判起点往左,从初判终点往右搜索,分别找到能零比曲线第一次与门限T,相交的两个点N和Ny,于是N,N,段就是用双门限方法所判定的语音段。
4)以短时平均过零率为准,从N,点往左和N,往右搜索,找到短时平均过零率低于某
阀值T,的两点N,和N,这便是语音段的起止点。
注意:门限值要通过多次实验来确定,门限都是由背景噪声特性确定的。语音起始段的
复杂度特征与结束时的有差异,起始时幅度变化比较大,结束时,幅度变化比较缓慢。在进行起止点判决前,通常都要采集若干帧背景噪声并计算其短时能量和短时平均过零率,作为选择M和M,的依据。
2.2 自相关法
(1)短时自相关
自相关函数具有一些性质,如它是偶函数;假设序列具有周期性,则其自相关函数也是
同周期的周期函数等。对于浊音语音可以用自相关函数求出语音波形序列的基音周期。此
外,在进行语音信号的线性预测分析时,也要用到自相关函数。
语音信号x,(m)的短时自相关函数R.(k)的计算式如下:
R.(k)=*.(m)x.(m+k)(0≤k≤K)(5-4)
式中,K是最大的延迟点数。
为了避免语音端点检测过程中受到绝对能量带来的影响,把自相关函数进行归一化处
理,即用R.(0)进行归一化,得到
R.(k)=R,(k)/R.(0)(0≤k≤K)(5-5)
(2)自相关函数最大值法
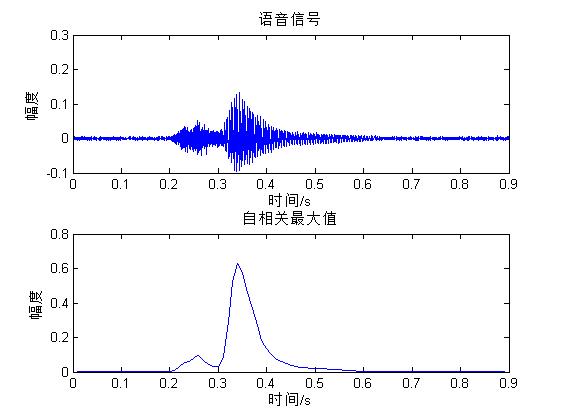
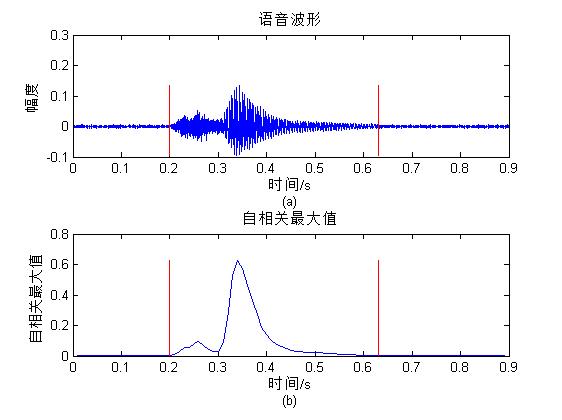
图5-2和图5-3分别是噪声信号和含噪语音的自相关函数。从图可知,两种信号的自相关函数存在极大的差异,因此可利用这种差别来提取语音端点。根据噪声的情况,设置两个阀值T,当相关函数最大值大于T时,便判定是语音;当相关函数最大值大于或小于T时,则判定为语音信号的端点。
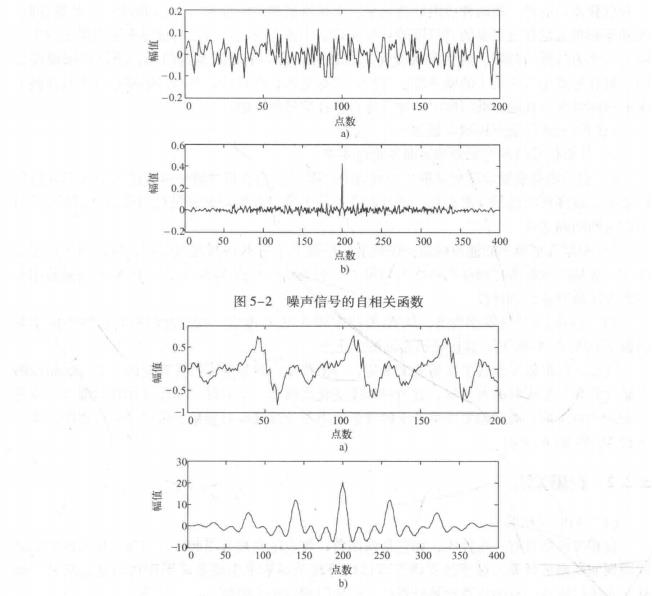
图5-3含噪语音的自相关函数
2.3 谱熵法
(1)谱熵特征
所谓熵就是表示信息的有序程度。在信息论中,熵描述了随机事件结局的不确定性,即
一个信息源发出的信号以信息熵来作为信息选择和不确定性的度量, 是由Shannon引用到信息理论中来的。1998年, Sh ne JL首次提出基于熵的语音端点检测方法, Sh ne在实验中发现语音的熵和噪声的熵存在较大的差异,谱熵这一特征具有一定的可选性,它体现了语音和噪声在整个信号段中的分布概率。
谱熵语音端点检测方法是通过检测谱的平坦程度,从而达到语音端点检测的目的,经实
验研究可知谱熵具有如下特征:
1)语音信号的谱熵不同于噪声信号的谱熵。
2)理论上,如果谱的分布保持不变,语音信号幅值的大小不会影响归一化。但实际上,语音谱熵随语音随机性而变化,与能量特征相比,谱熵的变化是很小的。
3)在某种程度上讲,谱熵对噪声具有一定的稳健性,相同的语音信号当信噪比降低
时,语音信号的谱熵值的形状大体保持不变,这说明谱熵是一个比较稳健性的特征参数。
4)语音谱熵只与语音信号的随机性有关,而与语音信号的幅度无关,理论上认为只要
语音信号的分布不发生变化,那么语音谱熵不会受到语音幅度的影响。另外,由于每个频率分量在求其概率密度函数的时候都经过了归一化处理,所以从这一方面也证明了语音信号的谱熵只会与语音分布有关,而不会与幅度大小有关。
(2)谱熵定义
设语音信号时域波形为x(i) , 加窗分帧处理后得到的第n帧语音信号为x, (m) , 其FFT表示为X.(k),其中下标n表示为第n帧,而k表示为第k条谱线。该语音帧在频域中的短时能量为
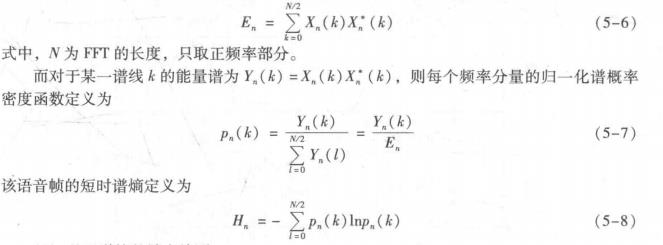
(3)基于谱熵的端点检测
由于谱熵语音端点检测方法是通过检测谱的平坦程度,来进行语音端点检测的,为了更
好地进行语音端点检测,本文采用语音信号的短时功率谱构造语音信息谱熵,从而更好地对语音段和噪声段进行区分。
其大概检测思路如下:
- 首先对语音信号进行分帧加窗、取FFT的点数。
2)计算出每一帧的谱的能量。
3)计算出每一帧中每个样本点的概率密度函数。
4)计算出每一帧的谱熵值。
5)设置判决门限。
6)根据各帧的谱熵值进行端点检测。
每一帧的谱熵值采用以下公式进行计算:
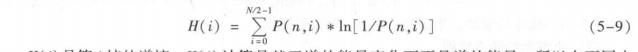
H(i)是第i帧的谱熵,H(i)计算是基于谱的能量变化而不是谱的能量,所以在不同水
平噪声环境下谱熵参数具有一定的稳健性,但每一谱点的幅值易受噪声的污染进而影响端点检测的稳健性。
2.4 比例法
(1)能零比的端点检测
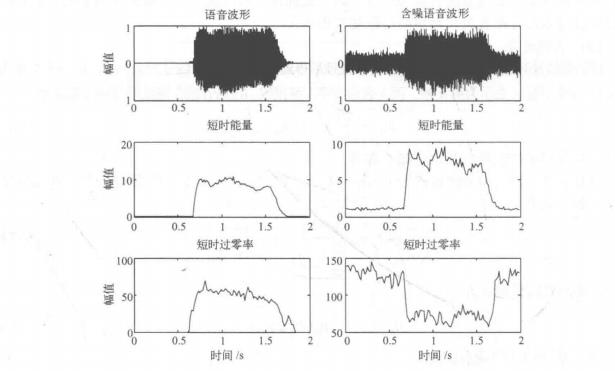
在噪声情况下,信号的短时能量和短时过零率会发生一定变化,严重时会影响端点检测
性能。图5-4是含噪情况下的短时能量和短时过零率显示图。从图中可知,在语音中的说
话区间能量是向上凸起的,而过零率相反,在说话区间向下凹陷。这表明,说话区间能量的数值大,而过零率数值小;在噪声区间能量的数值小,而过零率数值大,所以把能量值除以过零率的值,则可以更突出说话区间,从而更容易检测出语音端点。
改进式(5-1)的能量表示为LE=lg(1+E/a)(5-10)
式中,a为常数,适当的数值有助于区分噪声和清音。过零率的计算基本同式(5-2)和式(5-3)。不过,这里x,(m)需要先进行限幅处理,即
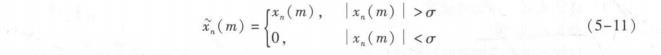
此时,能零比可表示为
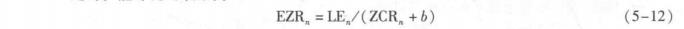
此处, b为一较小的常数, 用于防止ZCR, 为零时溢出。
(2)能熵比的端点检测
谱熵值很类似于过零率值,在说话区间内的谱熵值小于噪声段的谱熵值,所以同能零
比,能熵比的表示为
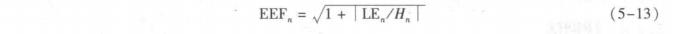
2.5对数频谱距离法
设含噪语音信号为x(n),加窗分帧处理后得到第i帧语音信号为x,(m),帧长为N。任
何一帧语音信号x(m) 做FFT后为
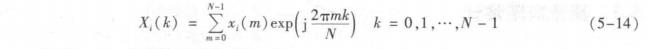
对频谱X,(k)取模值后再取对数,得
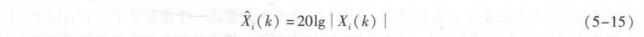
两个信号x(n)和xz(n)的对数频谱距离定义为
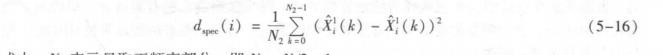
式中,N,表示只取正频率部分,即N=N/2+1。
当采用对数谱距离进行端点检测时,对数谱距离的两个信号分别是语音信号和噪声信
号。其中,噪声信号的平均频谱由下式获得:
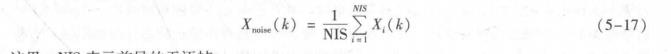
这里, N IS表示前导的无语帧。
基于对数谱距离的语音帧和噪声帧判别流程图如图5-5所示。通过判断一段语音信号
中的语音帧和噪声帧,即可实现基于对数谱距离的端点检测。
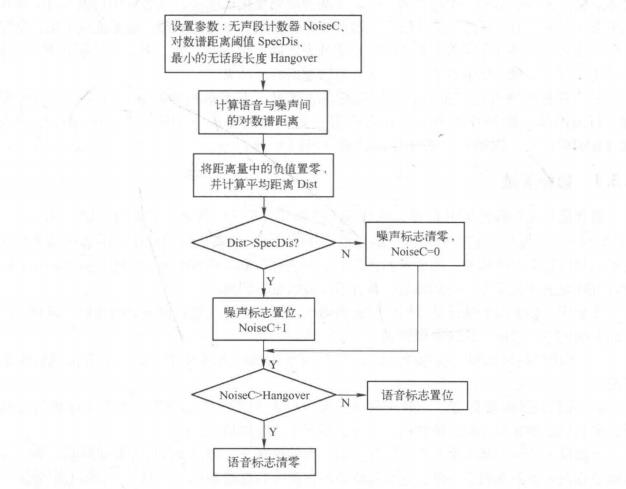
图5-5 基于对数频谱距离的语音帧和噪声帧判别流程图
三、部分源代码
四、运行结果
五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
以上是关于特征提取基于matlab自相关函数最大值端点检测含Matlab源码 1769期的主要内容,如果未能解决你的问题,请参考以下文章
语音识别基于matlab GUI MFCC+VAD端点检测智能语音门禁系统含Matlab源码 451期
语音识别基于matlab GUI MFCC+VAD端点检测智能语音门禁系统含Matlab源码 451期
语音识别基于matlab语音分帧+端点检测+pitch提取+DTW算法歌曲识别含Matlab源码 1057期
路面分类基于matlab灰度共生矩阵图形纹理检测+SVM路面状况分类含Matlab源码 1519期