40行Python代码利用DOI下载英文论文(2022.3.7)
Posted jing_zhong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了40行Python代码利用DOI下载英文论文(2022.3.7)相关的知识,希望对你有一定的参考价值。
40行Python代码利用DOI下载英文论文 2022.3.7
1、需求分析
一个人拥有的资产越多,就越难跟踪它们。如果人们将通过许多不同的途径找到自己的资产,更新资产会成为问题。随着时间的推移,资产会发生变化。例如,一段视频可能以不同的电子格式、不同的语言版本、经过编辑或扩展的变体出现。个人资产将带来新的服务,跟踪所有这些本身就是一项挑战。但如果没有对所有这些信息的有效管理,与他人共享内容和信息,无论是在商业交易中还是在合作中,都会变得越来越困难。

相信很多学生、开发者、工程师和研究人员在从事科研、工程等项目和学习的过程中,都不可避免地要学习并掌握相关的理论和算法模型,为我所用,因此就会在一些知名的期刊数据库中利用关键词、主题、标题和时间范围等检索相关的研究论文,这时人们往往会面临两种选择:(1)在期刊网站上在线实时地阅读论文并学习;(2)下载到本地电脑,即使断网也可在本机随时查看和参考。通常大多数人会选择后者,因为自己不可能为了学习一篇论文而多次检索,更大程度上是为了一次有效的检索让自己终身收益。
 |  |
 |  |
 |  |
 |  |
但是,在查找论文时我们或许会发现一篇论文可能会出现在多个数据库中,而像高校和科研机构(教育网)、互联网企业(企业网)都会选择性地购买大量数据库(中文数据库和外文数据库),这些数据库中的论文资料可供大学生、企业工程师和研发人员下载学习进行科学研究使用,但有时也无法下载全文。
2、DOI简介
DOI(Digital Object Identifier,数字对象标识符)是针对一个对象而设计的数字唯一标识符。我们可以用DOI来表示 等类型的对象。一个 DOI 号是一个实体在数字网络上的标识符,并不代表实体位置。DOI 号也可以通过 URL (URI) 进行表示。DOI 号由两部分组成:前缀和后缀。两者共同组成 DOI 号,其间使用“/”分隔。后缀是“/”分隔符后面的部分,可以是一个已有的标识符,也可以是注册者选用的任意唯一字符串。前缀是“/”分隔符前面的部分,表示唯一的命名机构。DOI 号无长度限制,且一经分配,永久不变。
DOI系统可以高效管理、准确追踪、简单自动化、创新性协作、符合ISO标准来标识抽象作品或特定版本的内容、协议、内容交换合同的参与者、各方、文件、设备、DVD。DOI得到了其社区的支持,以提供持久性维护,通过按照一致的标准创建元数据,共享和互操作成为可能,使用户可以利用这一价值实现商业和运营优势。
DOI的特点有:
- 一致性:DOI继续指向它标识的对象,即使该对象被移动、更新或修改
- 互操作性:元数据的通用标准和约定的语法和语义方法使共享来自不同来源的数据变得更容易、更高效
- 可扩展性:用户可以基于该标准开发适合其行业或部门的应用程序
- 平台独立性:允许轻松共享来自不同来源的数据,并方便多种输出格式
- 动态更新:由于DOI是持久性的,元数据可以随时间添加或更新,以进一步描述所识别的对象
- 多分辨率:DOI可以解析一个对象的多个数据项
- 类管理:具有类似属性的DOI可以作为一个类分组在一起。
DOI系统的优势:了解已有资源;查找所需资源;了解资源位置;快速获取资源。

如果想要对DOI有更加详细的了解,可查阅中文版的DOI手册。
3、根据DOI下载英文论文(来自Sci-hub)
一篇文章的DOI号就好比一个人的身份证号或者DNA一样,唯一而不改变,不存在一个论文有两个doi号的情况,同样也不存在一个doi号对应两篇论文的情况,因此可放心大胆地通过DOI号来准确下载相对应的论文(多尝试)。
3.1 利用Sci-hub网站手动下载
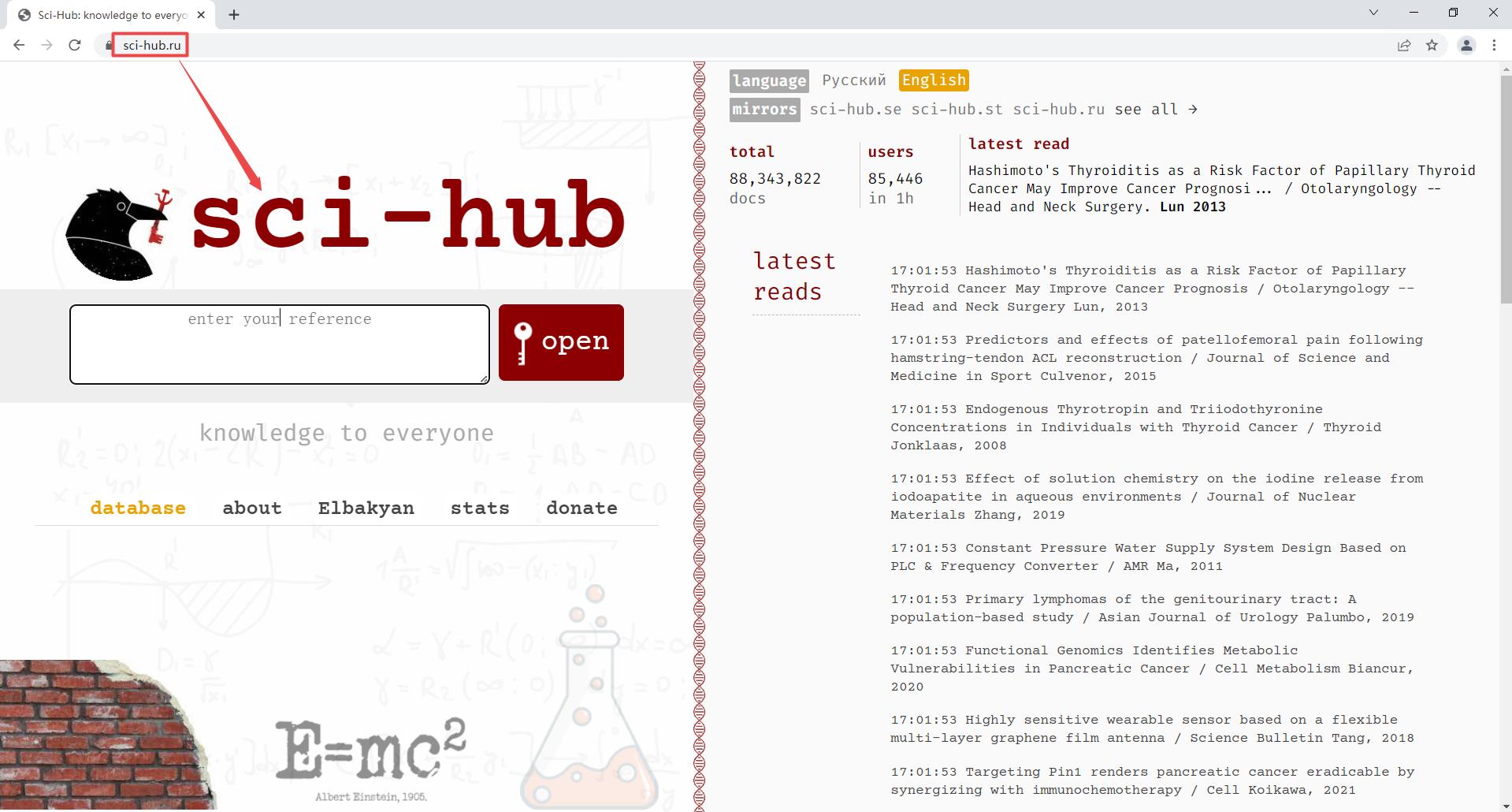


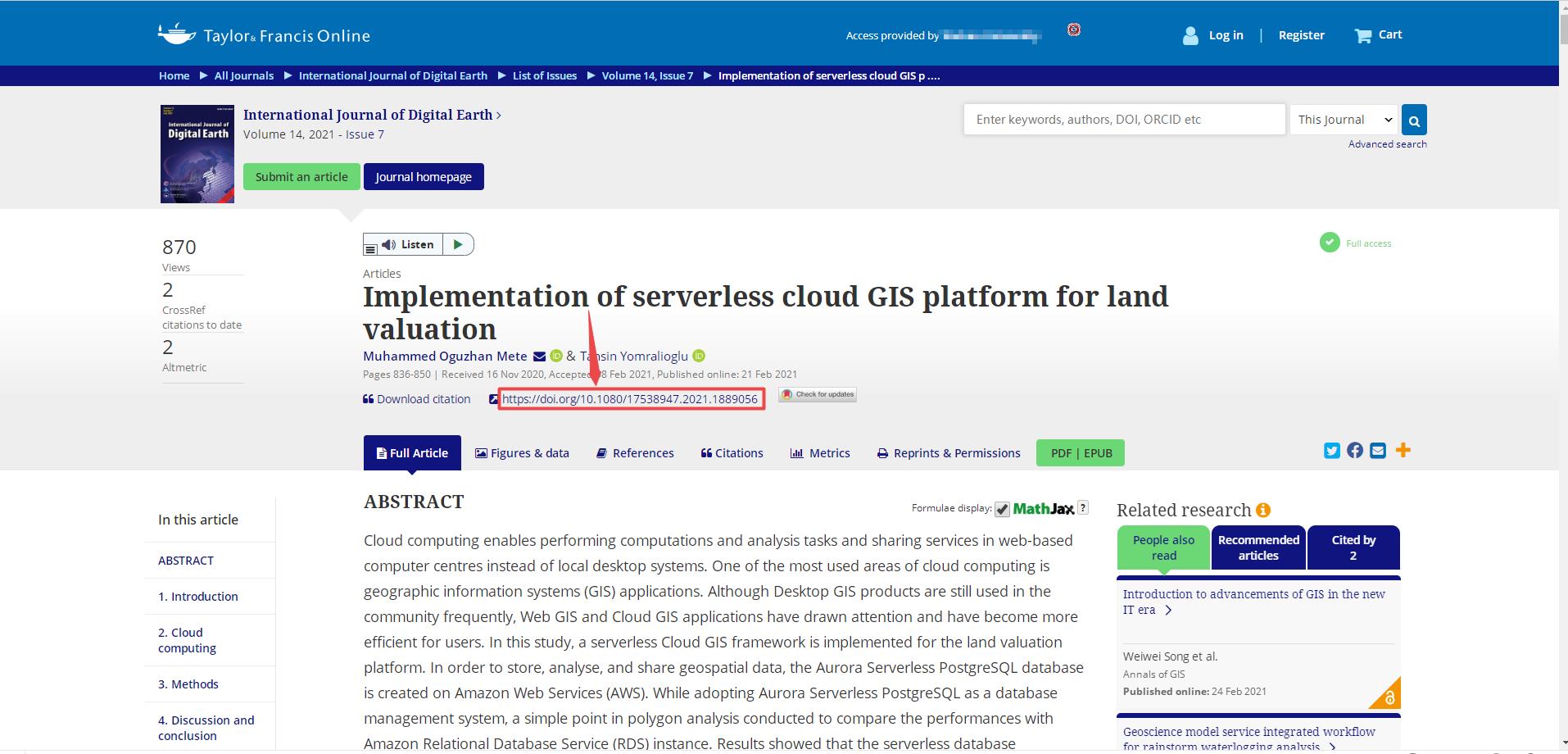
首先介绍Scihub网站——the first website in the world to provide mass & public access to research papers,这个网站的宗旨是making uncommon knowledge common,目标是to remove all barriers in the way of science。

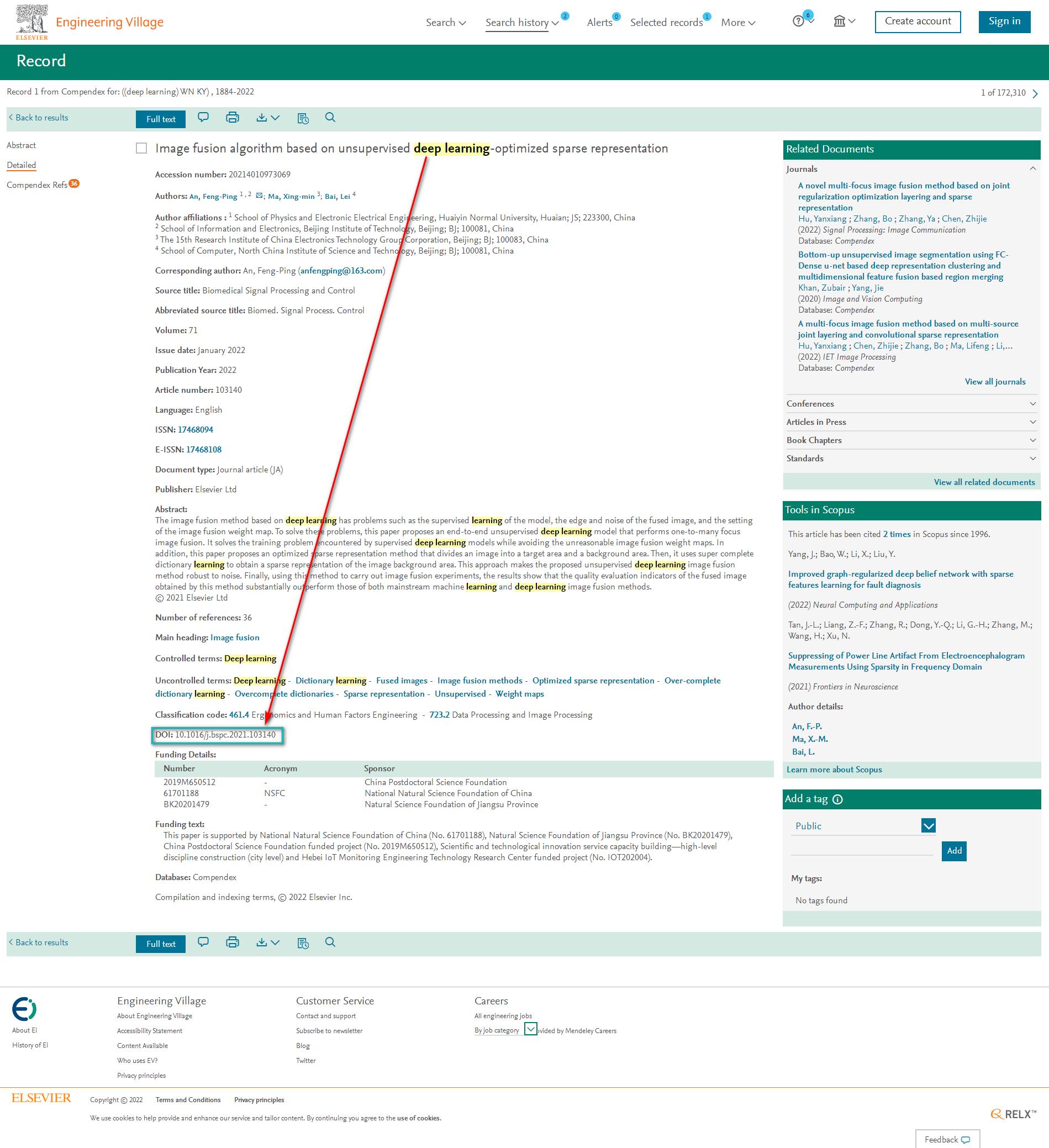
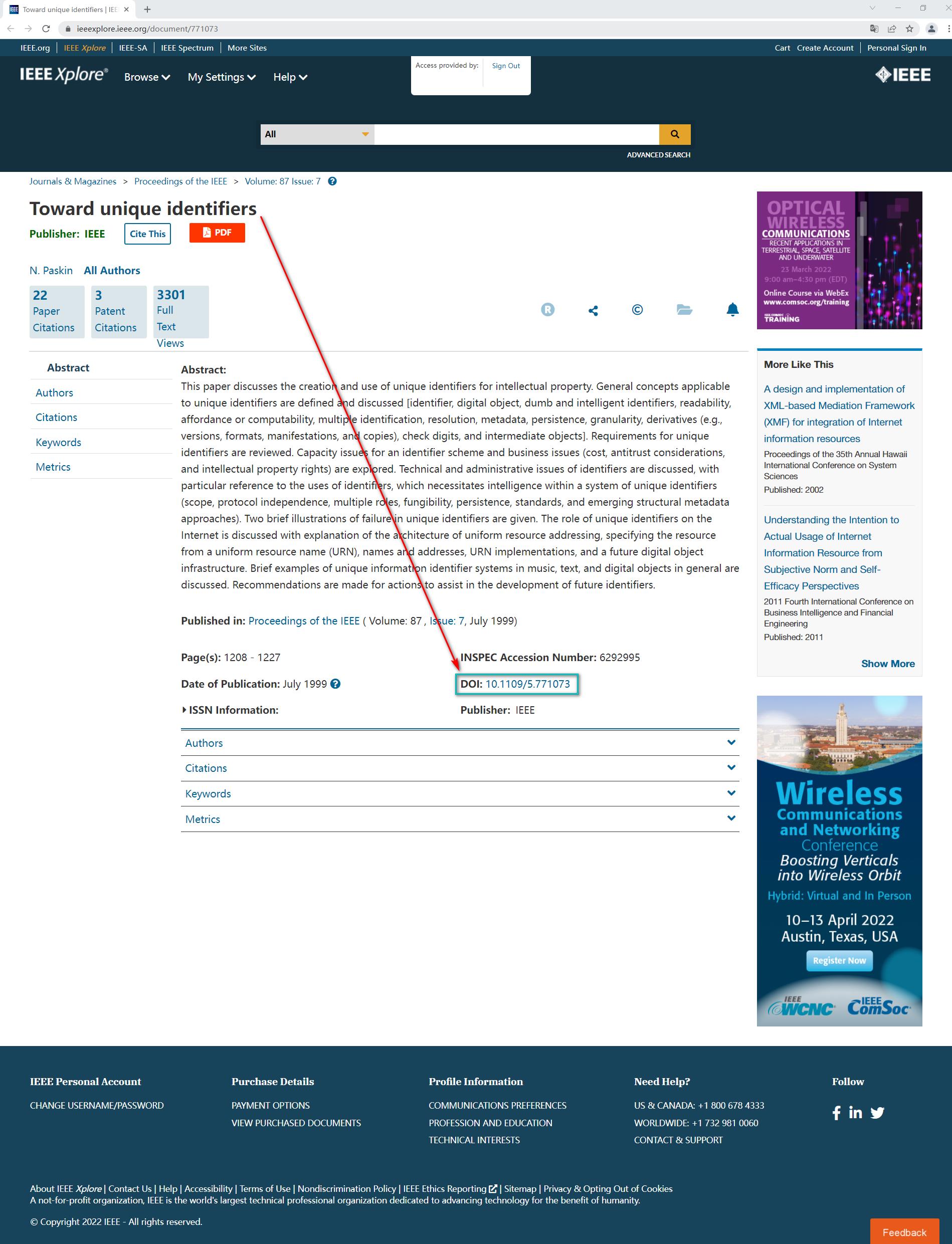
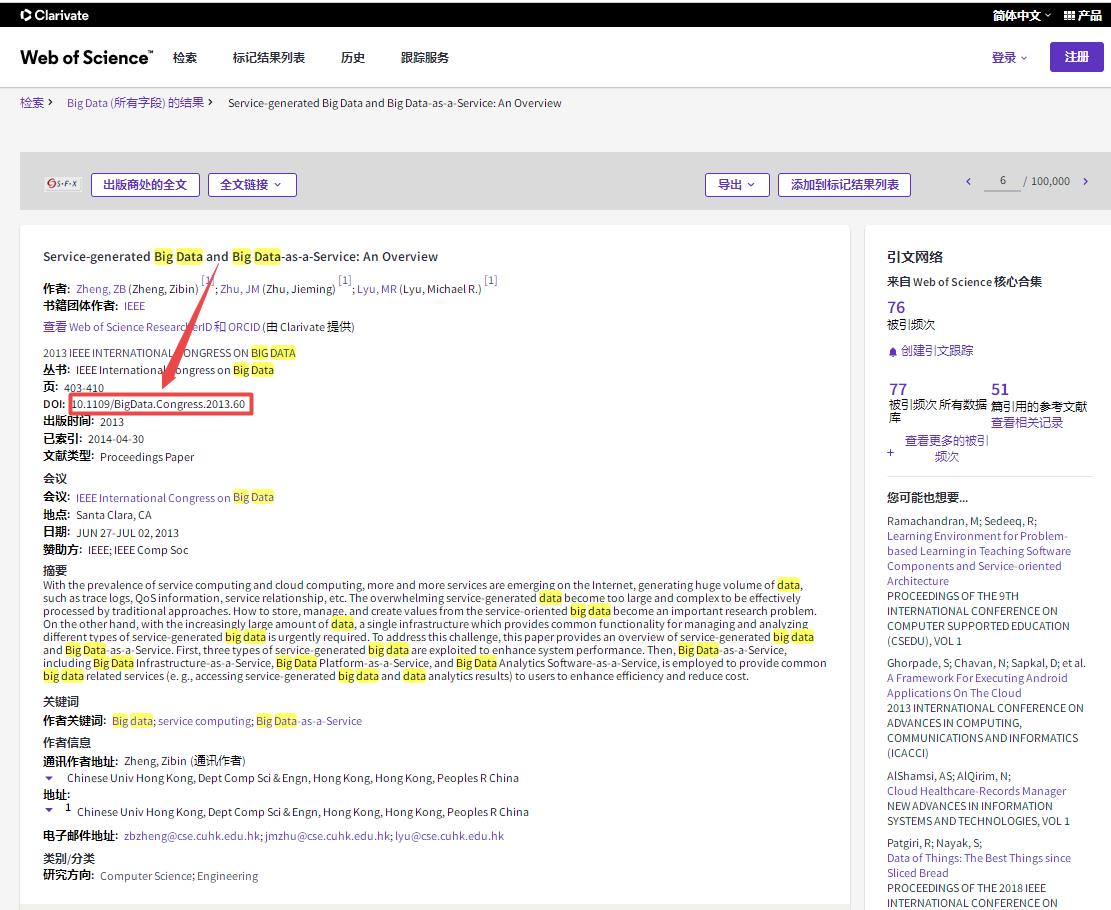
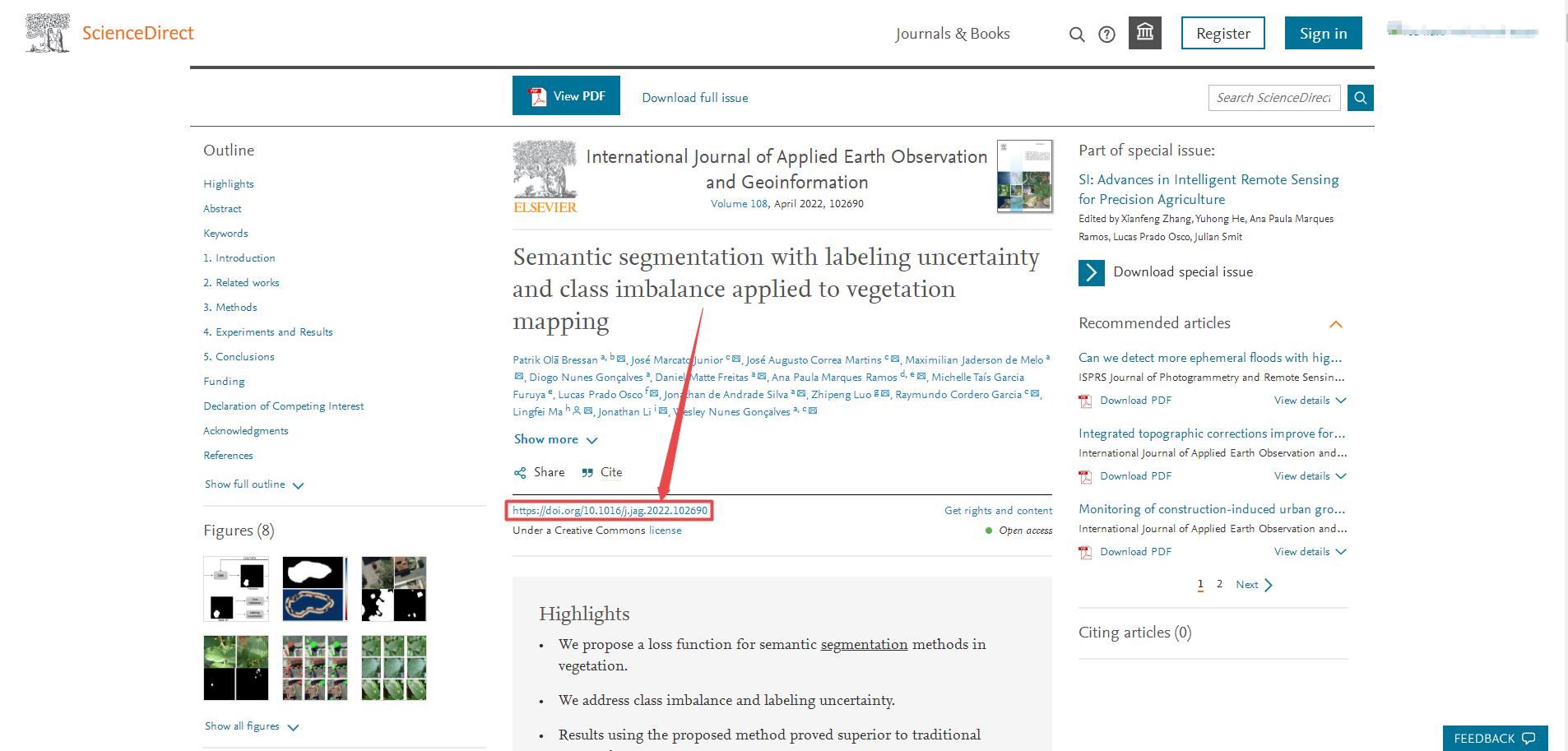
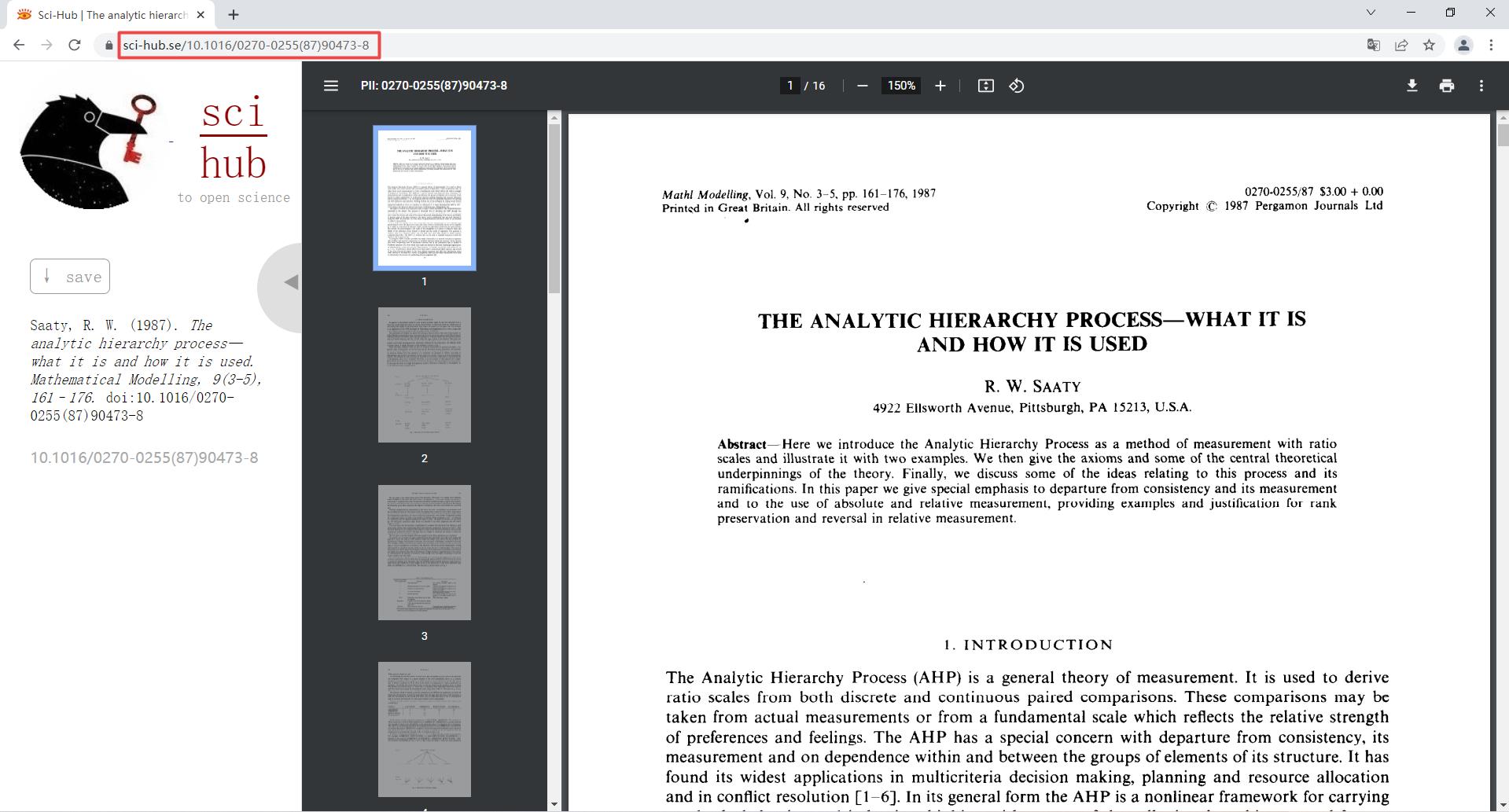
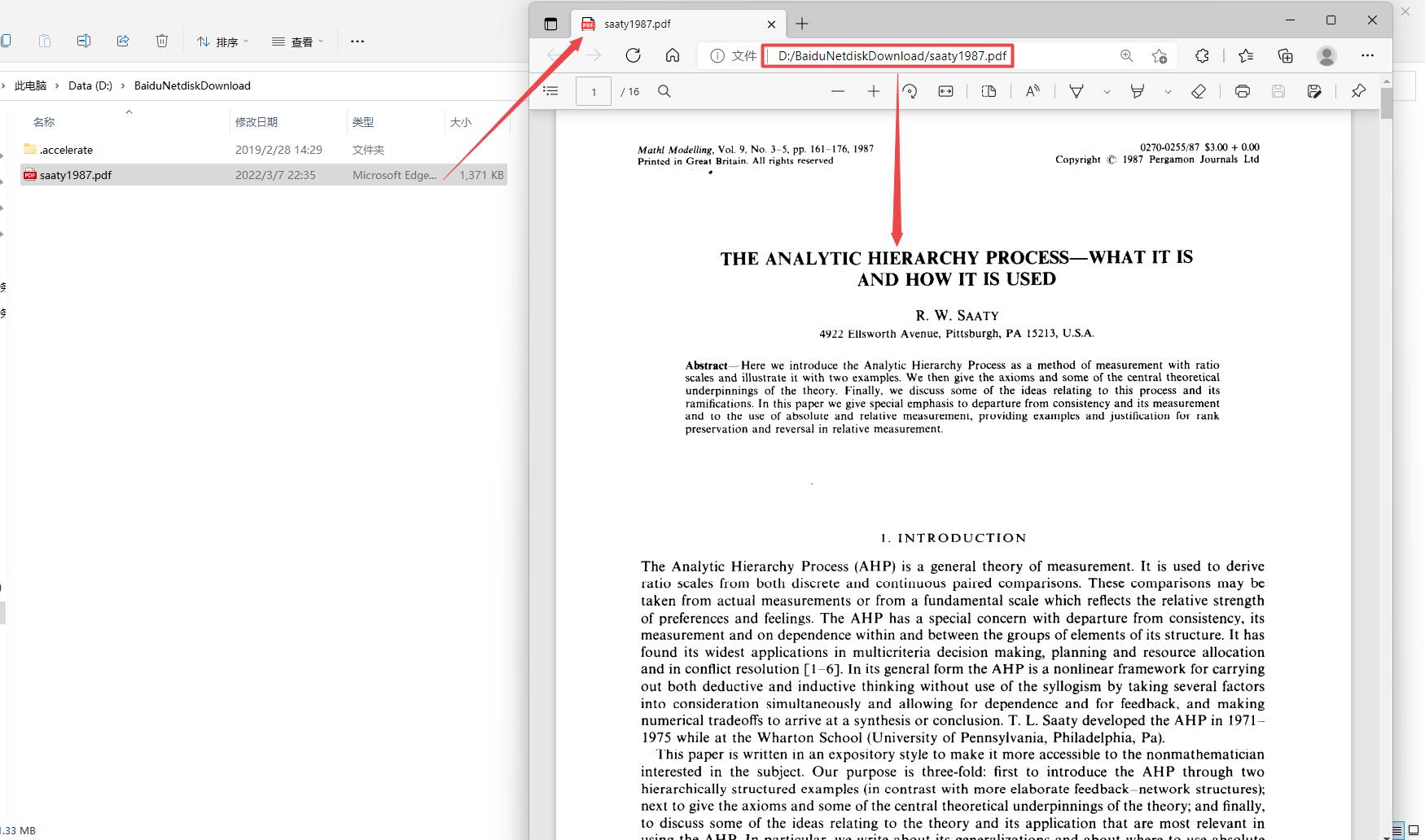
下面以THE ANALYTIC HIERARCHY PROCESS-WHAT IT IS AND HOW IT IS USED 为例来介绍Sci-hub网站如何直接下载英文论文,首先打开Sci-hub网站,在文本框中输入文章的DOI号:10.1016/0270-0255(87)90473-8后点击右侧的Open按钮或者回车,可以发现浏览器进入地址为https://sci-hub.se/10.1016/0270-0255(87)90473-8的页面,同时搜索到了正确的论文结果,点击右上角的下载图标即可下载到本地。

| 
|

| 
|
3.2 Python爬取论文下载的url进行下载
3.2.1 分析Sci-hub页面请求机制获取论文Url
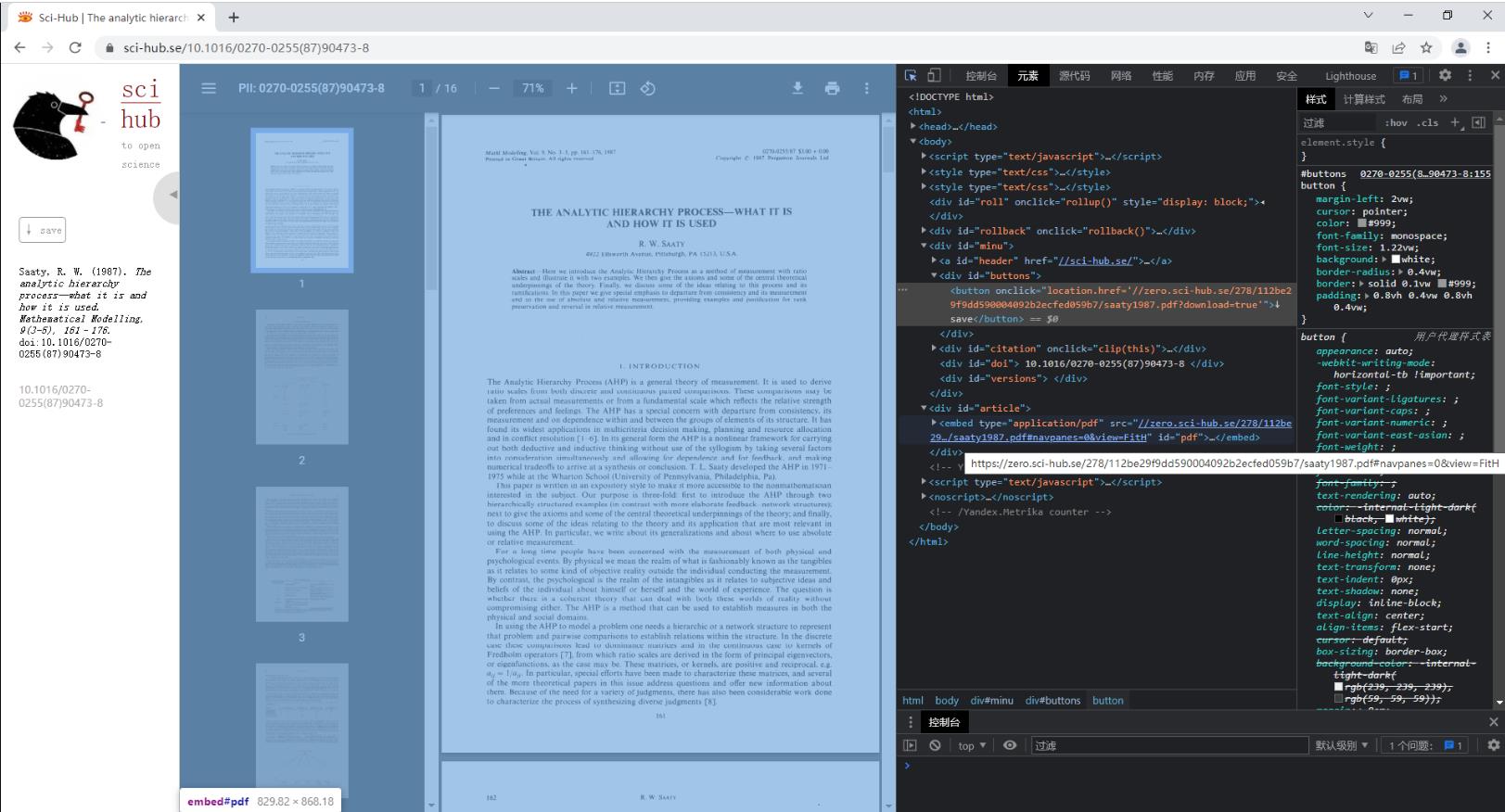
在利用Python爬取论文url下载地址前,需要对浏览器请求界面元素和机制进行分析,在2.1中的实例中可以发现通过DOI号检索后,浏览器地址栏中的url由https://sci-hub.se/变成了https://sci-hub.se/10.1016/0270-0255(87)90473-8,由此可见检索结果对应在浏览器里的HTML页面就是对拼接doi后的url发起http请求的结果,在请求结果html页面可以查看元素,发现左侧的save按钮对应元素代码有对应论文pdf版的url下载地址(链接),当然在article块里也有,即这两个地方都可以找到论文的Url下载地址:https://zero.sci-hub.se/278/112be29f9dd590004092b2ecfed059b7/saaty1987.pdf。
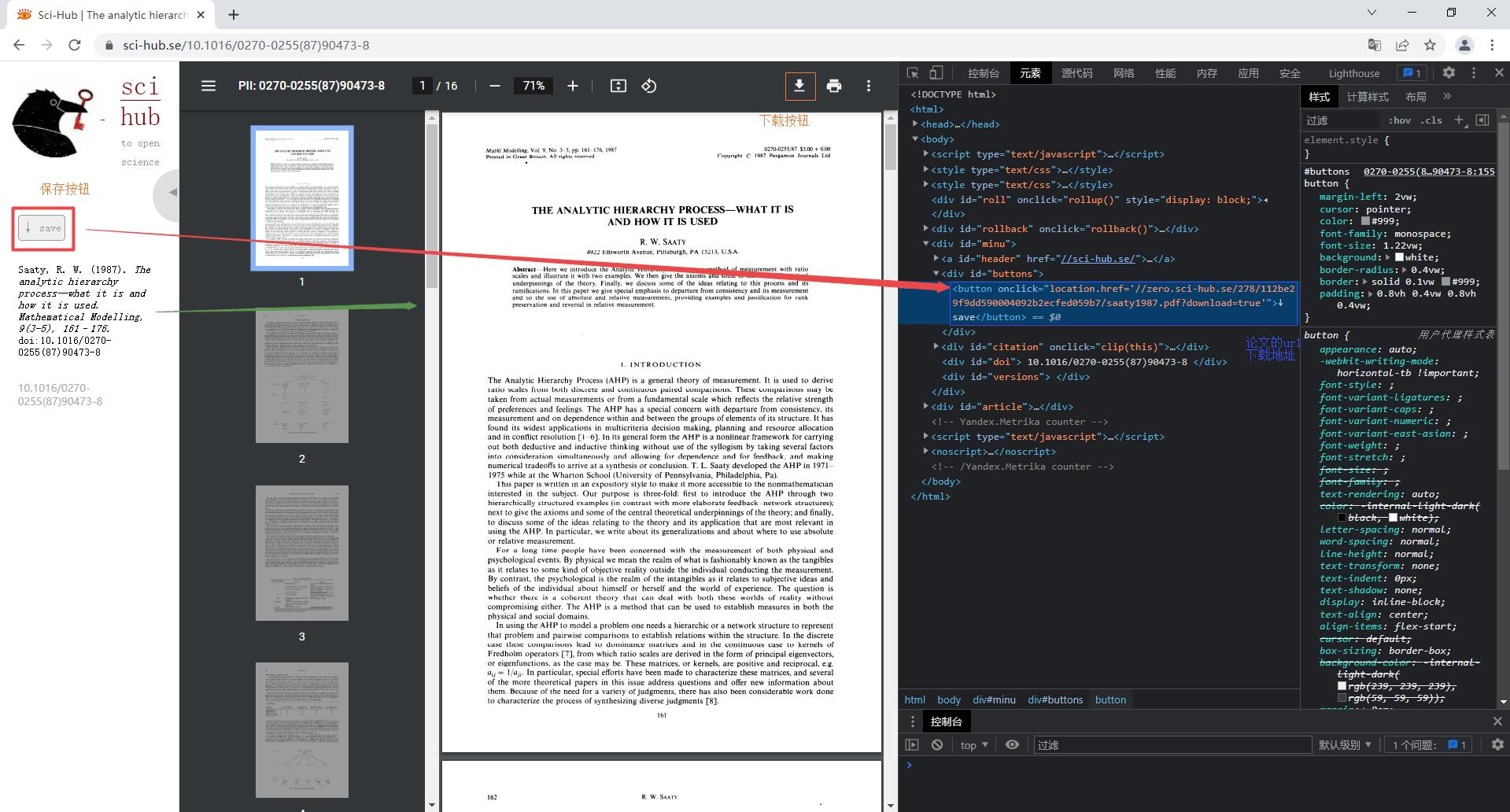
| 
|

3.2.2 Python获取论文Url实现论文自动下载
3.2.2.1 配置Python环境(PyCharm+Python 3.8.3 + requests)


3.2.2.2 Python代码
DownloadEnglishPaperByDOI.py
import requests
# Date Time: 2022.3.7
# Author: jing_zhong
# function: Download English-paper by DOI
def GetDownloadUrl(DOI_EnglishPaper):
BaseWebStation = 'https://sci-hub.se/'
url = BaseWebStation + DOI_EnglishPaper
print(url)
r = requests.get(url)
result_txt = r.text
result_list = result_txt.strip('').split('\\n')
#print(result_list)
myres = ''
for line in result_list:
line = line.strip('\\n')
if line.find('<button onclick =') >= 0:
myres += line
if myres == '':
myres = 'No Result!'
elif myres.find('//') >= 0:
myres = 'https:' + myres[myres.find('//'):myres.find('?download=true')]
# First way: button onclick <button οnclick="location.href='//twin.sci-hub.se/6748/d3cada06ce457b96477116e17c8273e5/nguyen2018.pdf?download=true'">↓ save</button>
elif myres.find('/downloads') >= 0:
myres = 'https://sci-hub.se' + myres[myres.find('/downloads'):myres.find('?download=true')]
# Second way: <button οnclick="location.href='/downloads/2021-05-18/9c/ananias2021.pdf?download=true'">↓ save</button>
return myres
def DownloadFileByUrl(DownloadUrl):
if DownloadUrl != '' and DownloadUrl.find('http') >= 0:
FileName = DownloadUrl.split('/')[-1]
r1 = requests.get(DownloadUrl)
if r1:
with open(FileName, "wb") as code:
code.write(r1.content)
print(DownloadUrl + ' File ' + FileName +' has been downloaded successfully!')
else:
print('Failed to download')
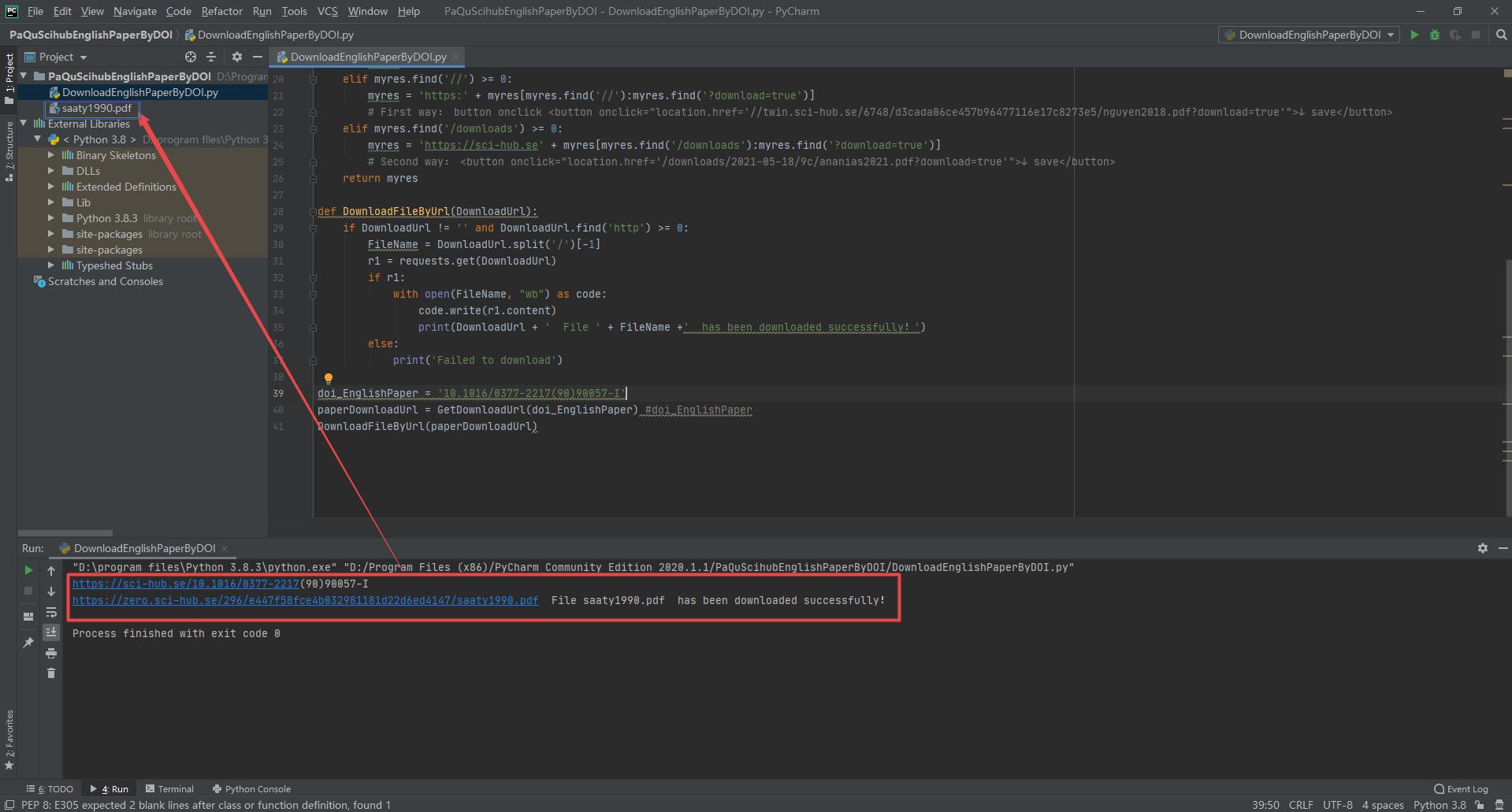
doi_EnglishPaper = '10.1002/tesq.441'
paperDownloadUrl = GetDownloadUrl(doi_EnglishPaper) #doi_EnglishPaper
DownloadFileByUrl(paperDownloadUrl)
代码测试样例(三个):
| DOI号 | 论文下载Url |
|---|---|
| 10.1016/0377-2217(90)90057-I | https://zero.sci-hub.se/296/e447f58fce4b032981181d22d6ed4147/saaty1990.pdf |
| 10.1002/tesq.441 | https://twin.sci-hub.se/6748/d3cada06ce457b96477116e17c8273e5/nguyen2018.pdf |
| 10.1080/17538947.2021.1907462 | https://sci-hub.se/downloads/2021-05-18/9c/ananias2021.pdf |
运行结果:






4、总结
希望利用DOI号在sci-hub网站上下载期刊数据库上无法下载的英文文献,满足科研人员、工程师的一小点学习需求,共同推动科学技术的发展和进步,但不是所有的论文都可以在该网站上得以下载,注意适可而止(批量请求可能会引起DDOS攻击和防护)。但切勿批量重复发起大量请求。本文旨在促进科研、学习交流探索技巧方法使用,并非万能,仍需大量样本测试改进,禁止用于商业目的盈利。

<!DOCTYPE html><html><head><title>DDOS-GUARD</title><meta charset="utf-8"><meta name="viewport" content="width=device-width,initial-scale=1"><script>var DOMReady=function(t)var e=document,d="addEventListener";e[d]?e[d]("DOMContentLoaded",t):window.attachEvent("onload",t),loadScript=function(t,e)var d=document.createElement("script");d.type="text/javascript",d.src=t,"string"==typeof e&&""!==e&&(d.id=e),(document.getElementsByTagName("head")[0]||document.body).appendChild(d);DOMReady(function()loadScript("https://check.ddos-guard.net/check.js"),loadScript("/.well-known/ddos-guard/check?context=free_splash","ddg_script_f"),setTimeout(function()document.location.reload(!0),3e3));</script><style>*margin:0;padding:0body,htmlfont-family:Open Sans,Arial,Helvetica,sans-serif;height:100%;background:linear-gradient(to top,#e5f3fb,#fff).logowidth:120px;margin-bottom:35px#titlefont-size:32px;font-weight:900;margin-bottom:40px#descriptioncolor:#8f9390;margin-bottom:30px#link-ddgwhite-space:nowrap;margin-bottom:30px;font-size:18px#link-ddg a:focus:active:hover:visitedcolor:#00adee#link-ddg a:activecolor:#00adee#link-ddg a:hovercolor:#00adee#link-ddg a:visitedcolor:#00adee.containerdisplay:flex;flex-direction:column;justify-content:center;align-items:center;height:100%;text-align:center;background:url(data:image/svg+xml;base64,PHN2ZyBpZD0i0KHQu9C+0LlfMSIgZGF0YS1uYW1lPSLQodC70L7QuSAxIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAxNjYuNzUgNDcuOTciPjxkZWZzPjxzdHlsZT4uY2xzLTF7ZmlsbDojZmZmO308L3N0eWxlPjwvZGVmcz48dGl0bGU+0JzQvtC90YLQsNC20L3QsNGPINC+0LHQu9Cw0YHRgtGMIDE8L3RpdGxlPjxwYXRoIGNsYXNzPSJjbHMtMSIgZD0iTTEzNS41NSwzOS44MmMtLjM4LDAtLjc1LDAtMS4xMywwYTE4LjkxLDE4LjkxLDAsMCwwLTM1LjMzLTQuNTNBMjUuMjYsMjUuMjYsMCwwLDAsNzcuMjEsMjIuN2MtLjgyLDAtMS42MywwLTIuNDMuMTJBMjkuMjYsMjkuMjYsMCwwLDAsMTcsMjkuMjZhMjkuNTksMjkuNTksMCwwLDAsLjE2LDNBMTguNTIsMTguNTIsMCwwLDAsMCw0OEgxNTAuNDNBMTcuNjQsMTcuNjQsMCwwLDAsMTM1LjU1LDM5LjgyWiIvPjxwYXRoIGNsYXNzPSJjbHMtMSIgZD0iTTE1OS40OSw0NS40NUE5LjU4LDkuNTgsMCwwLDAsMTUzLDQ4aDEzQTkuNTgsOS41OCwwLDAsMCwxNTkuNDksNDUuNDVaIi8+PC9zdmc+) center bottom no-repeat.lds-spinwidth:80px;height:80px@media screen and (max-width:1200px).logowidth:100px#titlefont-size:29px#link-ddgfont-size:15px#link-ddgfont-size:20px@media screen and (max-width:770px).logowidth:70px;margin-bottom:10px#titlefont-size:15px;margin-bottom:10px#descriptionmargin-bottom:10px;font-size:13px#link-ddgmargin-bottom:10px;font-size:13px.lds-spinwidth:40px;height:40px#link-ddgfont-size:18px</style></head><body><div class="container"><div class="logo"><svg id="dl" xmlns="http://www.w3.org/2000/svg" viewbox="0 0 6.62 7.69"><defs><style>.cls-1isolation:isolate.cls-2fill:#00adee.cls-3fill:#fff</style></defs><title>ddos_3</title><g id="_2560" data-name="2560" class="cls-1"><g id="G2" data-name="Gr2"><path class="cls-2" d="M3.3,0A6,6,0,0,1,0,1.91C.13,4.46,1.6,7.49,3.3,7.65,5,7.49,6.47,4.46,6.6,1.91A6,6,0,0,1,3.3,0Z"/><polygon class="cls-3" points="4.55 4.73 4.55 2.74 3.29 1.79 2.03 2.71 2.03 2.91 3.25 2.2 3.25 2.59 2.03 3.16 2.03 3.4 3.25 2.95 3.25 3.26 2.03 3.66 2.03 3.91 3.25 3.66 3.25 4.01 2.03 4.18 2.03 4.43 3.25 4.36 3.25 4.73 1.89 4.73 1.89 5.09 4.71 5.09 4.71 4.73 4.55 4.73"/></g></g></svg></div><div id="title"></div><div id="description"></div><div id="link-ddg"><a href="https://ddos-guard.net" target="_blank" id="link"></a></div><div class="lds"><svg class="lds-spin" width="100px" height="100px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" viewbox="0 0 100 100" preserveaspectratio="xMidYMid" style="background: none;"><g transform="translate(80,50)"><g transform="rotate(0)"><circle cx="0" cy="0" r="10" fill="#00adee" fill-opacity="1" transform="scale(0.7525 0.7525)"><animatetransform attributename="transform" type="scale" begin="-0.875s" values="0.7 0.7;1 1" keytimes="0;1" dur="1s" repeatcount="indefinite"/><animate attributename="fill-opacity" keytimes="0;1" dur="1s" repeatcount="indefinite" values="1;0" begin="-0.875s"/></circle></g></g><g transform="translate(71.21320343559643,71.21320343559643)"><g transform="rotate(45)"><circle cx="0" cy="0" r="10" fill="#00adee" fill-opacity="0.875" transform="scale(0.715 0.715)"><animatetransform attributename="transform" type="scale" begin="-0.75s" values="0.7 0.7;1 1" keytimes="0;1" dur="1s" repeatcount="indefinite"/><animate attributename="fill-opacity" keytimes="0;1" dur="1s" repeatcount="indefinite" values="1;0" begin="-0.75s"/><以上是关于40行Python代码利用DOI下载英文论文(2022.3.7)的主要内容,如果未能解决你的问题,请参考以下文章