python DataFrame常用描述性统计分析方法
Posted 侯小啾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python DataFrame常用描述性统计分析方法相关的知识,希望对你有一定的参考价值。
python DataFrame常用描述性统计分析方法
文章目录

ʚʕ̯•͡˔•̯᷅ʔɞ 个人简介
🍹欢迎各路大佬来到小啾主页指点☀️
✨博客主页:云雀编程小窝 🌹꧔ꦿ
🌹꧔ꦿ点赞 + 关注 + 收藏✨
☀️ 感谢大家的支持:一起加油!共同进步! 🍹

sum() 求和
使用sum()方法对DataFrame对象求和。
其中**set_option(‘display.unicode.east_asian_width’, True)**可以使显示的DataFrame值与列名对齐。
sum有axis参数,默认为0,表示对列求和
- 设置为1表示对行求和。
- 也可以设置 skipna参数,改参数默认为True,表示不考虑缺失值,如果是False则表示考虑缺失值,当存在缺失值时,则对应的结果表示为Nan。
- (布尔类型的参数值,当传入为其它类型的值时,也解读为该值的布尔值)
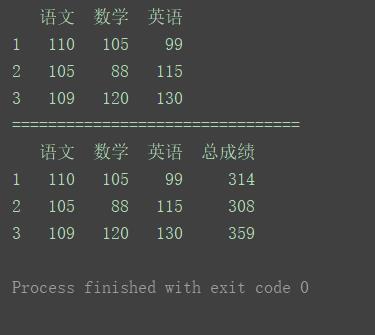
这里对示例数据的行求和,然后生成一个新的列添加在数据中。
import pandas as pd
data = [[110, 105, 99], [105, 88, 115], [109, 120, 130]]
index = [1, 2, 3]
columns = ['语文', '数学', '英语']
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("================================")
# 增加一列
df['总成绩'] = df.sum(axis=1, skipna=1)
print(df)
程序运行结果如下:
mean() 求平均值
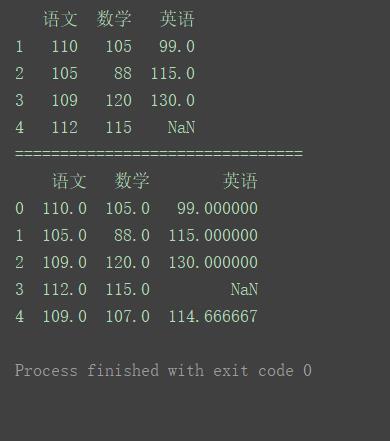
这里对生成数据的每一列求平均值,然后作为一个新的行增加给原数据。
通过示例可以看到,当原数据中存在空值时,计算均值时分子和分母都不计入该数据。即mean()求的是非空数据的平均值。
import pandas as pd
data = [[110, 105, 99], [105, 88, 115], [109, 120, 130], [112, 115]]
index = [1, 2, 3, 4]
columns = ['语文', '数学', '英语']
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("================================")
new = df.mean()
# 增加一行数据(语文、数学和英语的平均值,忽略索引)
df = df.append(new, ignore_index=True)
print(df)
关于DataFrame的append()方法
DataFrame增添一行可以使用append()方法。设置参数,ignore_index=True可以忽略掉索引。
当在DataFrame后边追加的对象为Series时,必须把ignore_index设为True,或者除非Serise有name属性。
当追加多列时,设置ignore_index为True可以避免出现索引值重复的异常事件。
此外DataFrame的append()方法在未来的版本即将被取消。将由concat替代。
max() 最大值 & min() 最小值
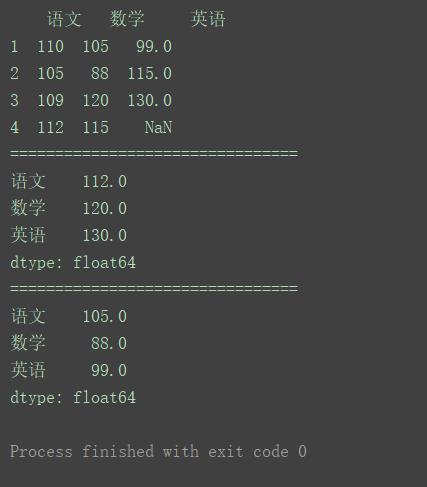
import pandas as pd
data = [[110, 105, 99], [105, 88, 115], [109, 120, 130]]
index = [1, 2, 3]
columns = ['语文', '数学', '英语']
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("================================")
df_max = df.max()
print(df_max)
print("================================")
df_min = df.min()
print(df_min)
median() 中位数
import pandas as pd
data = [[110, 120, 110], [130, 130, 131], [115, 120, 130]]
columns = ['语文', '数学', '英语']
df = pd.DataFrame(data=data, columns=columns)
print(df)
print("================================")
print(df.median())

mode() 众数
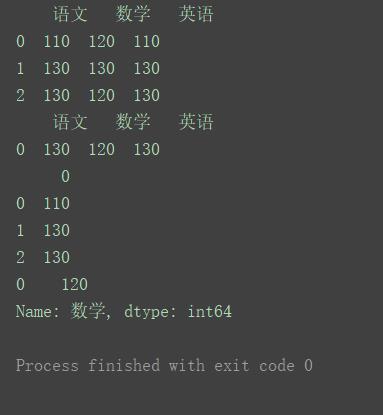
import pandas as pd
data = [[110, 120, 110], [130, 130, 130], [130, 120, 130]]
columns = ['语文', '数学', '英语']
df = pd.DataFrame(data=data, columns=columns)
print(df)
# 三科成绩的众数
print(df.mode())
# 每一行的众数
print(df.mode(axis=1))
# “数学”的众数
print(df['数学'].mode())
var() 方差
import pandas as pd
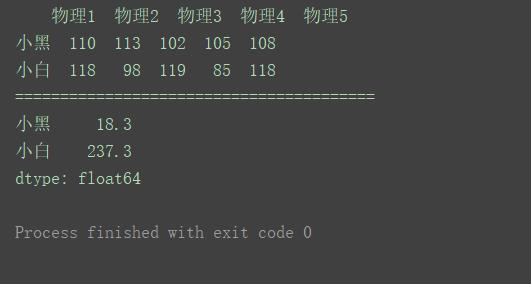
data = [[110, 113, 102, 105, 108], [118, 98, 119, 85, 118]]
index = ['小黑', '小白']
columns = ['物理1', '物理2', '物理3', '物理4', '物理5']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("========================================")
print(df.var(axis=1))
std() 标准差
import pandas as pd
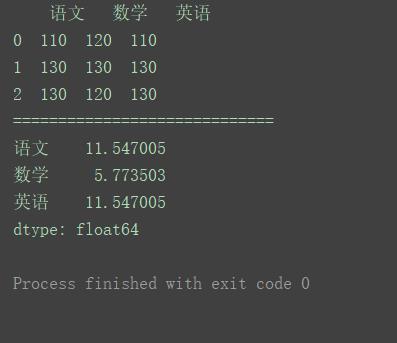
data = [[110, 120, 110], [130, 130, 130], [130, 120, 130]]
columns = ['语文', '数学', '英语']
df = pd.DataFrame(data=data, columns=columns)
print(df)
print("=============================")
print(df.std())
quantile() 分位数
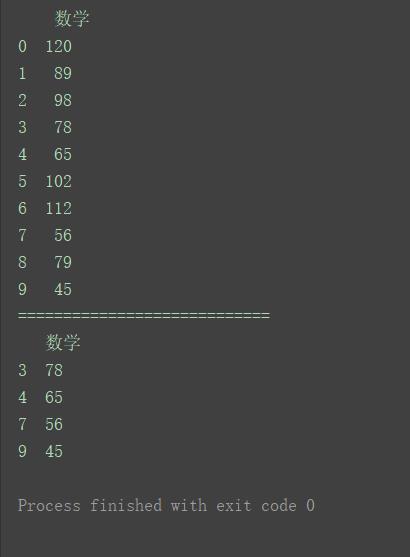
以35%分位数为例
import pandas as pd
# 创建DataFrame数据(数学成绩)
data = [120, 89, 98, 78, 65, 102, 112, 56, 79, 45]
columns = ['数学']
df = pd.DataFrame(data=data, columns=columns)
print(df)
print("============================")
# 计算35%的分位数
x = df['数学'].quantile(0.35)
# 输出淘汰学生
print(df[df['数学'] <= x])
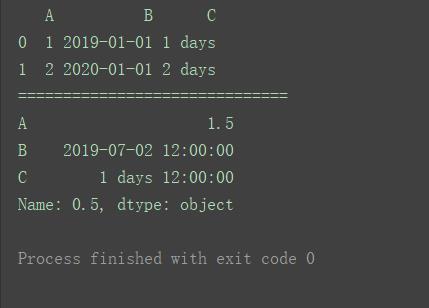
关于其他数据类型,如Timestamp,也可以使用分位数quantile()方法。
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame('A': [1, 2],
'B': [pd.Timestamp('2019'),
pd.Timestamp('2020')],
'C': [pd.Timedelta('1 days'),
pd.Timedelta('2 days')])
print(df)
print("==============================")
print(df.quantile(0.5, numeric_only=False))
以上是关于python DataFrame常用描述性统计分析方法的主要内容,如果未能解决你的问题,请参考以下文章