HashMap的产生与原理
Posted 帅次
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap的产生与原理相关的知识,希望对你有一定的参考价值。
一、HashMap的诞生
1.1 数组
数组:一片物理上连续的大小确定的储存空间。
好处:根据下标快速的查找和修改里面的内容。
缺点:大小确定,无法修改。添加新的元素或者删除元素比较麻烦。
数组的静态初始化
//数组实现方式一:
//数据类型 数组名称[] = 值, 值,…
String str[] = "移动端","android","ios";
System.out.println(str.length);//三个元素
for (int i = 0; i <str.length ; i++)
System.out.println(str[i]);
//数组实现方式二:
//数据类型 数组名称[] = new 数据类型[] 值, 值,…
String str2[] = new String[3];
str2[0] = "移动端";
str2[1] = "Android";
str2[2] = "iOS";
System.out.println(str2.length);//三个元素
for (int i = 0; i <str2.length ; i++)
System.out.println(str2[i]);
运行结果是一样的。
"E:\\Android\\Android StudioO\\jre\\bin\\java.exe"...
3
移动端
Android
iOS
如果我想再添加两个新元素(Java、Kotlin),那么使用数组就不合适了,这时候顺序表就出现了。
1.2 顺序表
顺序表:以数组的形式保存的线性表,物理上连续、逻辑上连续、大小可以动态增加。(如:ArrayList)
顺序表用的频率远远高于数据。用肯定都会用,咱们看看源码。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
transient Object[] elementData;//存储 ArrayList 元素的数组缓冲区。
private int size;//ArrayList 的大小
public ArrayList()
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
public E get(int index)
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index];
public E set(int index, E element)
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
public boolean add(E e)
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
public void add(int index, E element)
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
public void clear()
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
然后你会发现还是用数组进行存储的,只不过把对数组的操作处理了,而不需要我们自己处理。
原来的数据:

新增数据:

而顺序表的新增和删除元素都需要大量移动元素等操作,此时链表就产生了。
1.3 链表
链表:链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针连接次序实现的。
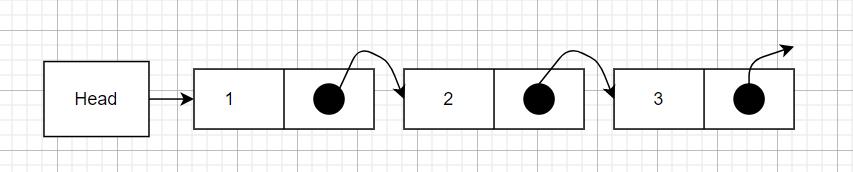
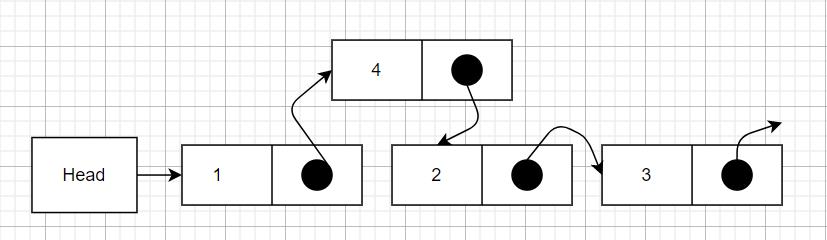
新增
这里将元素1的指针由指向元素2改为指向新增元素4,然后再将元素4的指针指向元素2即可。
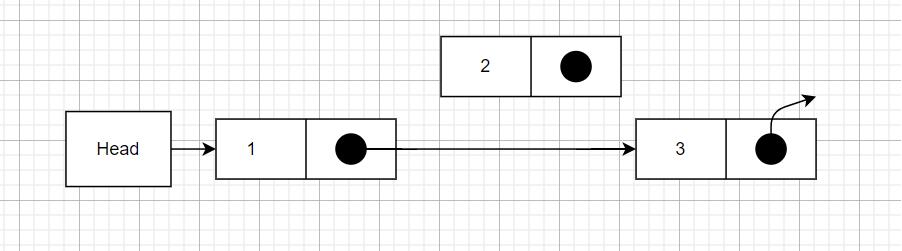
删除元素
将元素1的指针直接指向元素3即可。
1.4 ArrayList 和 LinkedList 对比
ArrayList(顺序表):
-
优点:查找快
-
缺点:增删慢
LinkedList(链表)
-
优点:增删快
-
缺点:查找慢
那么问题来了在什么情况下使用 ArrayList?在什么情况下使用 LinkedList? 为什么?
那么可不可以将 顺序表和链表的优点结合起来呢?——Hash表
1.5 Hash表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表其实本质上就是一个数组。可以根据一个key值来直接访问数据,查找速度快。
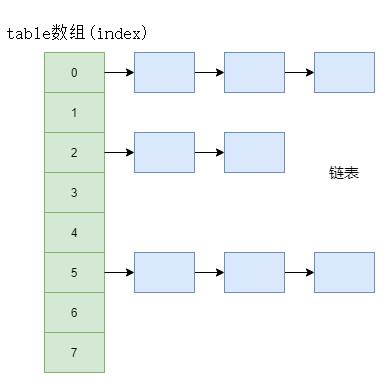
二、HashMap
HashMap采用Node(implements Map.Entry)数组来存储key-value对,每一个键值对组成了一个Node实体,Node类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Node实体。
注意:jdk1.8 HashMap中的Entry不见了,取而代之的是Node,但是Node也实现了Map.Entry接口,和之前的Entry类似。
Node类
static class Node<K,V> implements Map.Entry<K,V>
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next)
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
public final K getKey() return key;
public final V getValue() return value;
public final String toString() return key + "=" + value;
public final int hashCode()
return Objects.hashCode(key) ^ Objects.hashCode(value);
public final V setValue(V newValue)
V oldValue = value;
value = newValue;
return oldValue;
public final boolean equals(Object o)
...
从上面看出 hash、key、value 代表本节点数据,next表示指向下一个节点的数据。
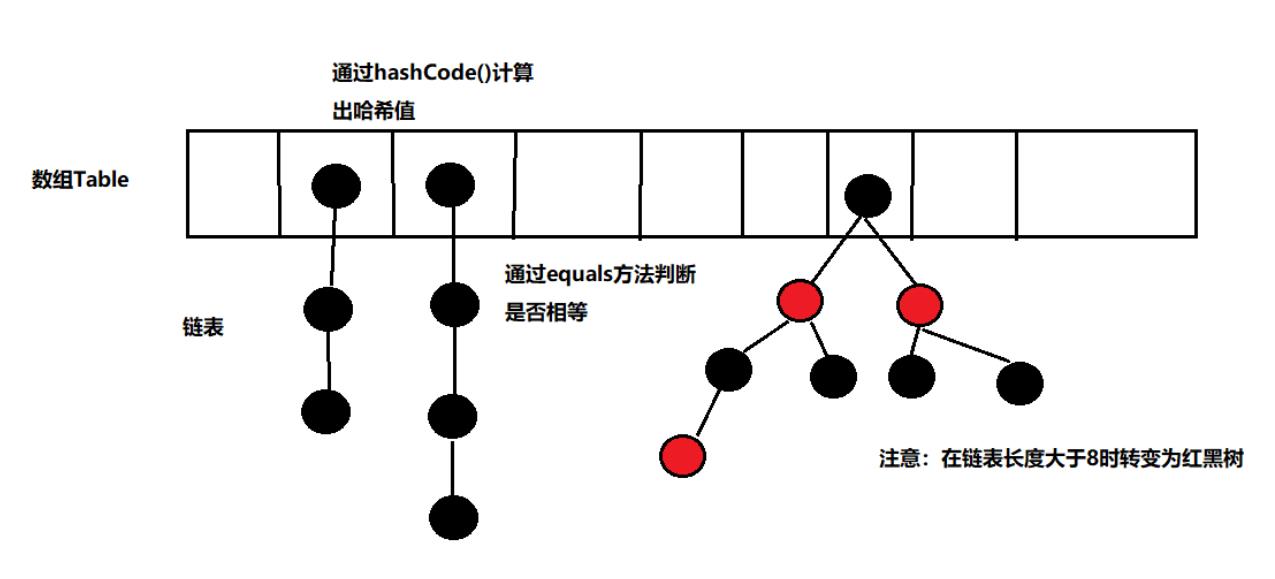
-
JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
-
JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8) 时,将链表转换为红黑树,这样大大减少了查找时间。
2.0 小试牛刀
class HashMapTest
public static void main(String[] args)
//创建HashMap
HashMap<String,String> hashMap = new HashMap<>();
//添加数据(key-value)
hashMap.put("name","帅次");
hashMap.put("age","20");
hashMap.put("subject","Android");
hashMap.put(null,"空Key");
System.out.println("HashMap1:"+hashMap.toString());//null=空Key, subject=Android, name=帅次, age=20
//添加数据(覆盖已有key)
hashMap.put("age","26");
System.out.println("HashMap2:"+hashMap.toString());//null=空Key, subject=Android, name=帅次, age=26
//根据key,获取value
System.out.println("Key-null:"+hashMap.get(null));//空Key
System.out.println("Key-subject:"+hashMap.get("subject"));//Android
//根据key删除元素
System.out.println("删除subject对应:"+hashMap.remove("subject"));//删除subject对应:Android
//根据key-value删除元素
System.out.println("删除age:"+hashMap.remove("age","20"));//删除age对应20:false
System.out.println(hashMap.toString());//null=空Key, name=帅次, age=26
System.out.println("删除age:"+hashMap.remove("age","26"));//删除age对应20:true
System.out.println("HashMap3:"+hashMap.toString());//null=空Key, name=帅次
//方法一:1、获得key-value的Set集合,2、循环(推荐)
Set<Map.Entry<String,String>> entrySet= hashMap.entrySet();
for (Map.Entry<String, String> strEntry : entrySet)
System.out.println("遍历Set集合:"+strEntry.getKey()+"-"+strEntry.getValue());
//方法二:1、获取key的Set集合,2、循环
Set<String> strKeySet= hashMap.keySet();
for (String s : strKeySet)
//先获取key,通过key获取value
System.out.println("遍历KeySet集合:"+s+"-"+hashMap.get(s));
//方法三:1、获得key-value的Set集合,2、获取iterator 3、循环
Set<Map.Entry<String,String>> itEntrySet= hashMap.entrySet();
Iterator iterator = itEntrySet.iterator();
while (iterator.hasNext())
Map.Entry map= (Map.Entry)iterator.next();
System.out.println("遍历Iterator:"+map.getKey()+"-"+map.getValue());
//其他还有不少方法可以遍历数据
运行结果
"E:\\Android...."
HashMap1:null=空Key, subject=Android, name=帅次, age=20
HashMap2:null=空Key, subject=Android, name=帅次, age=26
Key-null:空Key
Key-subject:Android
删除subject对应:Android
删除age:false
null=空Key, name=帅次, age=26
删除age:true
HashMap3:null=空Key, name=帅次
遍历Set集合:null-空Key
遍历Set集合:name-帅次
遍历KeySet集合:null-空Key
遍历KeySet集合:name-帅次
遍历Iterator:null-空Key
遍历Iterator:name-帅次
Process finished with exit code 0
2.1 构造方法
/**
* 默认加载因子值
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 哈希表的加载因子。
*/
final float loadFactor;
public HashMap(int initialCapacity, float loadFactor)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
public HashMap(int initialCapacity)
this(initialCapacity, DEFAULT_LOAD_FACTOR);
public HashMap(Map<? extends K, ? extends V> m)
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
/**
* 构造一个具有默认加载因子 (0.75) 的空 HashMap。
*/
public HashMap()
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
HashMap有4个构造方法,主要初始化了三个参数:
-
initialCapacity:初始容量(默认16)。
-
loadFactor 加载因子(默认0.75)。
-
threshold 阈值:hashMap所能容纳的最大价值对数量,如果超过则需要扩容,计算方式:
threshold=initialCapacity*loadFactor。
加载因子:在默认情况下,数组大小为16,那么当HashMap中元素个数超过
16*0.75=12的时候,就把数组的大小扩展为16*2=32,即扩大一倍,然后重新计算每个元素在数组中的位置。当然这个值是可以自己设定的,但是不推荐修改这个值。
咱们比较常用的还是无参构造方法。HashMap 创建好了,那么咱们开始存储数据吧。
2.2 put()
添加数据:
-
key可以为null
-
key唯一,如果key存在则覆盖value内容
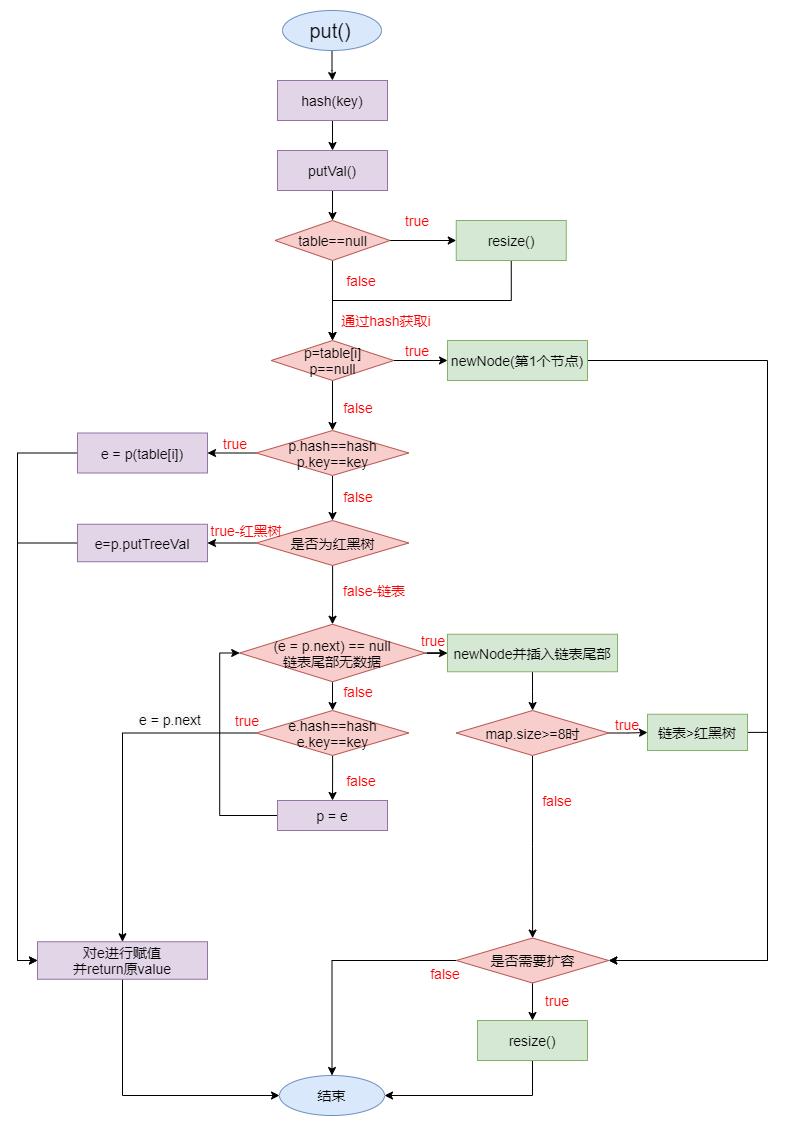
public V put(K key, V value)
return putVal(hash(key), key, value, false, true);
这里在调用 putVal() 方法前根据key进行了hash计算。
2.2.1 hash(key)
/**
* 计算 key.hashCode() 并将散列的高位散列(XOR)到低位。由于该表使用二次幂掩码,因此仅在当前掩码之上位变化的散列集将始终发生冲突。
* 使用树来处理 bin 中的大量冲突,我们只是以最便宜的方式对一些移位的位进行异或,以减少系统损失,以及合并最高位的影响,否则由于表边界,这些最高位将永远不会用于索引计算(摘自源码)。
*/
static final int hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
public int hashCode()
return identityHashCode(this);
static int identityHashCode(Object obj)
int lockWord = obj.shadow$_monitor_;
final int lockWordStateMask = 0xC0000000; // Top 2 bits.
final int lockWordStateHash = 0x80000000; // Top 2 bits are value 2 (kStateHash).
final int lockWordHashMask = 0x0FFFFFFF; // Low 28 bits.
if ((lockWord & lockWordStateMask) == lockWordStateHash)
return lockWord & lockWordHashMask;
return identityHashCodeNative(obj);
-
当 key == null 时返回0,也就是说 key 可以设置为 null。
-
从identityHashCode()方法看出key可以是任意类型,都可以变成int类型的hashCode。
h >>> 16 是什么?
h是hashCode。h >>> 16是用来取出h的高16,(>>>是无符号右移)
0000 0100 1011 0011 1101 1111 1110 0001
>>> 4
0000 0000 0100 1011 0011 1101 1111 1110
>>> 16
0000 0000 0000 0000 0000 0100 1011 0011
上面两个例子 一个>>>4 一个>>>16,可用于对比。
这里根据Key返回了一个Hash值。拿到哈希值咱们继续看 putVal() 方法。
2.2.2 putVal()
/**
* table 在首次使用时初始化,存储数据的Node类型 数组,并根据需要调整大小。
* 长度 = 2 的幂。(特殊情况下可为0),数组的每个元素 = 1个单链表
*/
transient Node<K,V>[] table;
/**
* @param hash 键的哈希值
* @param key 键
* @param value 要放置的值
* @param onlyIfAbsent 如果为真,则不要更改现有值
* @param evict 如果为 false,则表处于创建模式。
* @return 前一个值,如果没有则返回 null
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断table是否初始化
if ((tab = table) == null || (n = tab.length) == 0)
//调用 resize() 方法,进行初始化并赋值
n = (tab = resize()).length;
//通过hash获取下标,如果数据为null
if ((p = tab[i = (n - 1) & hash]) == null)
//tab[i]下标没有值,创建新的Node并赋值。
tab[i] = newNode(hash, key, value, null);
else
//tab[i] 下标的有数据,发生碰撞
Node<K,V> e; K k;
//判断tab[i]的hash值传入的hash值相当,tab[i]的的key值和传入的key值相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果是原有数据直接替换即可
e = p;
else if (p instanceof TreeNode)//判断数据结构为红黑树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else //数据结构是链表
for (int binCount = 0; ; ++binCount)
//p的下一个节点为null,表示p就是最后一个节点
if ((e = p.next) == null)
//创建Node并插入链表的尾部
p.next = newNode(hash, key, value, null);
//当元素>=8-1,链表转为树(红黑树)结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
//如果key在链表中已经存在,则退出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//更新p指向下一个节点,继续遍历
p = e;
//如果key在链表中已经存在,则修改其原先key的value值,并且返回老的value值
if (e != null)
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);//替换旧值时会调用的方法(默认实现为空)
return oldValue;
++modCount;//修改次数
//根据map值判断是否要对map的大小扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);//插入成功时会调用的方法(默认实现为空)
return null;
2.2.3 resize() 扩容
/**
* 默认初始容量 - 必须是 2 的幂。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 初始化或加倍 table 大小。 如果为空,则按照字段阈值中保存的初始容量目标进行分配。
* 否则,因为我们使用二次幂扩展
*/
final Node<K,V>[] resize()
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//table已经初始化,且容量 > 0
if (oldCap > 0)
//MAXIMUM_CAPACITY=1<<30=2的30次幂=1073741824
if (oldCap >= MAXIMUM_CAPACITY)
//如果旧的容量已近达到最大值,则不再扩容,阈值直接设置为最大值
//Integer.MAX_VALUE=(1 << 31)-1=2的31次幂-1=2147483648-1
threshold = Integer.MAX_VALUE;
return oldTab;
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 扩大两倍
else if (oldThr > 0) // 初始化容器=threshold
newCap = oldThr;
else
//threshold 和 table 皆未初始化情况,此处即为首次进行初始化
//第一次进入什么都没有所以要初始化容器(16)
newCap = DEFAULT_INITIAL_CAPACITY;
//12 = 0.75*16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
//newThr 为 0 时,计算阈值
if (newThr == 0)
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
//更新阈值
threshold = newThr;
@SuppressWarnings("rawtypes","unchecked")
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//更新table数据
table = newTab;
//如果之前的数组桶里面已经存在数据,由于table容量发生变化,hash值也会发生变化,需要重新计算下标
if (oldTab != null)
for (int j = 0; j < oldCap; ++j)
Node<K,V> e;
//将指定下标数据不为null
if ((e = oldTab[j]) != null)
//将指定下标数据置空
oldTab[j] = null;
//指定下标数据只有一个
if (e.next == null)
//直接将数据存放到新计算的hash值下标
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)//红黑树
//将树箱中的节点拆分为下树箱和上树箱,如果现在太小(<=6),则数据结构取消红黑树改为链表。
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else //链表
//重新计算hash值,根据新的下标重新分组
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do
next = e.next;
if ((e.hash & oldCap) == 0)
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
else
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
while ((e = next) != null);
if (loTail != null)
loTail.next = null;
newTab[j] = loHead;
if (hiTail != null)
hiTail.next = null;
newTab[j + oldCap] = hiHead;
return newTab;
因此,resize()方法 初始化了容器,并给 table 赋值,返回Node<K,V>[]。
2.2.4 putTreeVal()
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v)
Class<?> kc = null;
boolean searched = false;
//获取根节点
TreeNode<K,V> root = (parent != null) ? root() : this;
//循环所有的节点,如果key冲突,返回原key对应的对象,如果不存在key冲突,则直接存放对象,并返回null对象
for (TreeNode<K,V> p = root;;)
int dir, ph; K pk;
//dir:决定节点的位置
if ((ph = p.hash) > h)//当前节点的哈希值大于存放对象的哈希值
dir = -1;
else if (ph < h)//当前节点的哈希值小于存放对象的哈希值
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))//当前节点等于存放对象的哈希值,且key相同,则返回当前节点
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
//如果不按哈希值排序,而是按照比较器排序,则通过比较器返回值决定进入左右结点
if (!searched)
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
//如果p的左节点或右节点为空,证明已经找到存放位置
if ((p = (dir <= 0) ? p.left : p.right) == null)
Node<K,V> xpn = xp.next;
//创建新节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
//根据dir设置存放位置
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
//balanceInsertion树化结构,设置红黑节点,是否需要旋转
//moveRootToFront重置根节点
moveRootToFront(tab, balanceInsertion(root, x));
return null;
2.3 get()
获取数据
这方法返回结果:
-
节点(Node);
- null
-
该 key 对应的数据就是 null;
-
HashMap 中不存在该 key
-
public V get(Object key)
Node<K,V> e;
//hash(key):根据key的hashCode计算hash值,这个跟put中的的一样。
return (e = getNode(hash(key), key)) == null ? null : e.value;
这个方法就是通过 getNode() 方法来获取节点,如果节点为null则返回null,如果节点存在则返回key对应的value。
2.3.1 getNode()
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return 节点(node),如果没有则返回 null
*/
final Node<K,V> getNode(int hash, Object key)
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//根据hash值获取table中节点存放位置,并获取第一个元素。
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null)
//如果第一个节点是我们要找的Key,则直接返回
if (first.hash == hash && //
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//获取下一个节点的信息
if ((e = first.next) != null)
//判断数据结构是红黑树,则通过getTreeNode()获取节点并返回
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//否则循环整个链表找到节点并返回
do
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
while ((e = e.next) != null);
return null;
2.3.2 getTreeNode()
static final class TreeNode<K,V> extends LinkedHashMap.LinkedHashMapEntry<K,V>
TreeNode<K,V> parent; // 红黑树节点
//调用树的find()函数
final TreeNode<K,V> getTreeNode(int h, Object k)
return ((parent != null) ? root() : this).find(h, k, null);
2.3.3 find()
final TreeNode<K,V> find(int h, Object k, Class<?> kc)
TreeNode<K,V> p = this;
do
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)//当前节点的哈希值大于给定哈希值,进入左节点
p = pl;
else if (ph < h)//当前节点小于给定哈希值,进入右节点
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))//当前节点等于给定哈希值,且key相同,则返回当前节点
return p;
else if (pl == null)//如果左节点为null,则进入右节点
p = pr;
else if (pr == null)//如果右节点为null,则进入左节点
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)//如果不按哈希值排序,而是按照比较器排序,则通过比较器返回值决定进入左右结点
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)//如果在右结点中找到该关键字,直接返回当前节点
return q;
else//进入左节点
p = pl;
while (p != null);
return null;
2.4 remove()
public V remove(Object key)
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable)
Node<K,V>[] tab; Node<K,V> p; int n, index;
//判断table是否存在、数据元素大于>0、index位置元素是否存在
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null)
Node<K,V> node = null, e; K k; V v;
//判断p和传入的数据一致
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//获取p的数据
node = p;
else if ((e = p.next) != null) //和p数据不一致,获取p下一个节点数据
//判断p的数据结构是否为红黑树
if (p instanceof TreeNode)
//红黑树,调用find找到node节点
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else
//链表
do
//循环找到跟e相同的数据
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k))))
node = e;
break;
p = e;
while ((e = e.next) != null);
//判断获取到的数据
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v))))
//根据红黑树删除数据
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)//node=p,然后指针指向p节点后一个节点,达到删除node的目的
tab[index] = node.next;
else//此时node=p.next,所以node就被干掉了
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
return null;
这个方法其实跟上面的 put/get 方法类似,都是先获取哈希值,然后根据哈希值和Key找到这个节点,进行删除,自己探索乐趣多多。
2.5 clear()
public void clear()
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0)
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
这个简单粗暴,直接遍历table,然后将table的值设置为null。
其实HashMap常用的方法也就这么几个,你了解了吗?
三、问答小知识
3.1 为什么Key总喜欢用String、Integer
从HashMap的语法上来讲,一切对象都可以作为Key值。如:Integer、Long、String、Object等。但是在实际工作中,最常用的使用String作为Key值。
-
它们都是final修饰的类,不可变性,保证key的不可更改性,不会存在获取hash值不同的情况。
-
它们内部已重写了equals()、hashCode()等方法,遵守了HashMap内部的规范。
-
它们具有自己独立的特性,它们都放在常量区(快速判断是否相等)。
3.2 HashMap在什么情况下扩容?
在上面的put方法中有这么一段内容
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
...
if (++size > threshold)
resize();
...
当map的元素大于threshold = capacity(当前Map的大小) * load factor(默认0.75).
调用 resize() 进行扩容
static final int MAXIMUM_CAPACITY = 1 << 30;
final Node<K,V>[] resize()
...
if (oldCap > 0)
if (oldCap >= MAXIMUM_CAPACITY)
threshold = Integer.MAX_VALUE;
return oldTab;
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
...
>>:按二进制形式把所有的数字向左移动对应的位数,高位移出(舍弃),低位的空位补零。如将oldCap向左移动1位。限制:最大不能超过2的30次幂
3.3 为什么扩容是2的n次幂?
HashMap为了存取高效,要尽量较少碰撞。就是要尽量把数据分配均匀,每个链表长度大致相同。
例如:hashMap.get("name").hashCode()=773564。
773564 转为二进制:10111100110110111100
取模运算

取模运算:明显当hashmap大小不为2的n次幂的时候,哈希值的碰撞就多了起来。
tab[(n - 1) & hash])
hash算法中,为了使元素分布的更加均匀,很多都会使用取模运算,在hashMap中并没有使用hash%n这样进行取模运算,而是使用(n - 1) & hash进行代替。原因是在计算机中,&的效率要远高于%;需要注意的是,只有容量为2的n次幂的时候,(n - 1) & hash 才能等效hash%n,这也是hashMap 初始化初始容量时必须是2的n次幂的原因。
3.4 为什么要先高16位异或低16位再取模运算?
由于hashcode 和(length-1)运算,length 绝大多数情况小于2的16次方。所以始终是hashcode 的低16位(甚至更低)参与运算。要是高16位也参与运算,会让得到的下标更加散列。
3.5 HashMap 中的 key 为 定义的实体类类型, 则需实现哪些方法?
//未重写equals()、hashCode()方法
System.out.println("未重写equals()、hashCode()等方法");
HashMap<User,String> userMap = new HashMap<>();
User userQin = new User("嬴政",20);
userMap.put(userQin,"秦始皇");
//当你定义的MapUser和put时的数据未发生改变,通过Map.get可以获取到数据
System.out.println(userMap.get(userQin));//秦始皇
System.out.println("Age20:"+userQin.hashCode());//Age20:1531333864
//当MapUser.age发生改变后,通过Map.get无法获取数据
userQin.age=25;
System.out.println("Age25:"+userQin.hashCode());//Age25:1531333864
System.out.println(userMap.get(userQin));//秦始皇
userMap.put(new User("刘邦",20),"汉高祖");
System.out.println(userMap.get(new User("刘邦",20)));//null
//重写了equals()、hashCode()方法
System.out.println("重写了equals()、hashCode()方法");
HashMap<HMUser,String> hmUserMap = new HashMap<>();
HMUser hmUserLi = new HMUser("李世民",20);
hmUserMap.put(hmUserLi,"唐太宗");
//当你定义的MapUser和put时的数据未发生改变,通过Map.get可以获取到数据
System.out.println(hmUserMap.get(hmUserLi));//唐太宗
System.out.println("Age20:"+hmUserLi.hashCode());//Age20:807921772
//当MapUser.age发生改变后,通过Map.get无法获取数据
hmUserLi.age=25;
System.out.println("Age25:"+hmUserLi.hashCode());//Age25:807921777
System.out.println(hmUserMap.get(hmUserLi));//null
hmUserMap.put(new HMUser("朱元璋",20),"明太祖");
System.out.println(hmUserMap.get(new HMUser("朱元璋",20)));//明太祖
-
未重写equals()、hashCode()方法时:
-
同一个对象属性发生改变后hashCode值还相同,可以从Map.get中获取到值。
-
不同对象属性相同,无法从Map.get中获取到值。
-
-
重写equals()、hashCode()方法时:
-
同一个对象属性发生改变后hashCode也发生变化相同,无法从Map.get中获取到值。
-
不同对象属性相同,可以从Map.get中获取到值。
-
3.6 为什么 HashMap 是非线程安全
-
HashMap 写入时:假如 A 线程和 B 线程同时进行插入操作,计算出了相同的哈希值对应了相同的数组位置,A 先写入一个节点,B 也写入同一节点,那B的写入操作就会覆盖 A 的写入操作>造成 A 的写入数据丢失。
-
HashMap 扩容时:会新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。当多个线程同时进来,检测到总数量超过门限值的时候就会同时调用 resize 操作,各自生成新的数组,最终只有最后一个线程生成的新数组被赋给该 map 底层,其他线程的均会丢失。
反正挺多可能会出现线程安全问题,总之 HashMap 是非线程安全的,有并发问题时,建议使用 ConcrrentHashMap。
ConcrrentHashMap:
-
底层采用分段的数组+链表实现,线程安全。
-
通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍(读操作不加锁,由于Node的value变量是 volatile 的,也能保证读取到最新的值)。
-
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。
-
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
-
扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
以上是关于HashMap的产生与原理的主要内容,如果未能解决你的问题,请参考以下文章