安全隐患:神经网络可以隐藏恶意软件
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了安全隐患:神经网络可以隐藏恶意软件相关的知识,希望对你有一定的参考价值。

编译 | 禾木木
出品 | AI科技大本营(ID:rgznai100)
凭借数百万和数十亿的数值参数,深度学习模型可以做到很多的事情,例如,检测照片中的对象、识别语音、生成文本以及隐藏恶意软件。加州大学圣地亚哥分校和伊利诺伊大学的研究人员发现,神经网络可以在不触发反恶意软件的情况下嵌入恶意负载。
恶意软件隐藏技术 EvilModel 揭示了深度学习的安全问题,这已成为机器学习和网络安全会议讨论的热门话题。随着深度学习逐渐与我们的应用中变得必不可分,安全社区需要考虑新的方法来保护用户免受这类新兴的威胁。

深度学习模型中隐藏的恶意软件
每个深度学习模型都是由多层人工神经元组成,根据层的类型,每个神经元与其上一层和下一层中的所有或部分神经元有所连接。根据深度学习模型在针对任务训练时使用的参数数值不同,神经元间连接的强度也会不同,大型的神经网络甚至可以拥有数亿乃至数十亿的参数。
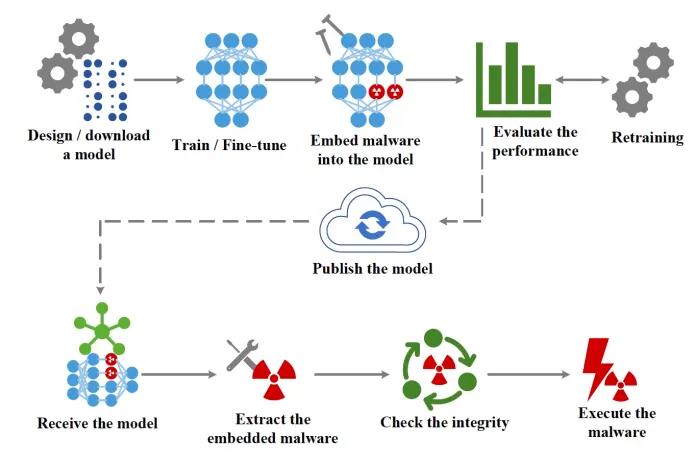
EvilModel 背后的主要思想是将恶意软件嵌入到神经网络的参数中,使其对恶意软件扫描仪不可见。这是隐写术的一种形式,将一条信息隐藏在另一条信息中的做法。
同时,携带恶意病毒的深度学习模型还必须执行其主要任务(例如,图像分类)做到和正常模型一样号,以避免引起怀疑或使其对受害者无用。
最后,攻击者必须有一种机制将受感染的模型传递给目标设备,并从模型参数中提取恶意软件。

更改参数值
多数深度学习模型都会使用 32 位(4 个字节)的浮点数来存储参数值。据研究者实验,黑客可以在不显著提升其中数值的前提下,每个参数中存储最多存储 3 字节的病毒。

大多数深度学习模型使用 32 位(4字节)浮点数来存储参数值。根据研究,在不显著提升其数值的前提下,最多有三字节可用于嵌入恶意代码。
在感染深度学习模型时,攻击者会将病毒打散至 3 字节,并将数据嵌入到模型的参数之中。为了将恶意软件传输至目标的手段,攻击者可以将感染后的模型发布至 GitHub 或 TorchHub 等任意托管神经模型的网站。或是通过更复杂的供应链攻击形式,让目标设备上软件的自动更新来传播受感染的模型。
一旦受感染后的模型交付给受害者,一个小小的软件就可提取并执行负载。

在卷积神经网络中隐藏的恶意软件
为了验证 EvilModel 的可行性,研究人员在多个卷积神经网络(CNN)中进行了测试。CNN 是个很好的测试环境,首先,CNN 的体积都很大,通常会有几十层和数百万的参数;其次,CNN 包含各类架构,有不同类型的层(全连接层、卷积层)、不同的泛化技术(批归一化、弃权、池化等等),这些多样化让评估各类病毒嵌入设定变得可能;第三,CNN 通常用于计算机视觉类的应用,这些都是恶意因素的主要攻击对象;最后,很多经过预训练的 CNN 可以在不经任何改动的情况下直接集成到新的应用程序中,而多数在应用中使用预训练 CNN 的开发人员并不一定知道深度学习的具体应用原理。
研究人员首先尝试进行病毒嵌入的神经网路是AlexNet,一款曾在 2012 年重新激起人们对深度学习兴趣的流行软件,拥有 178 兆字节、五个卷积层和三个密集层或全连接层。
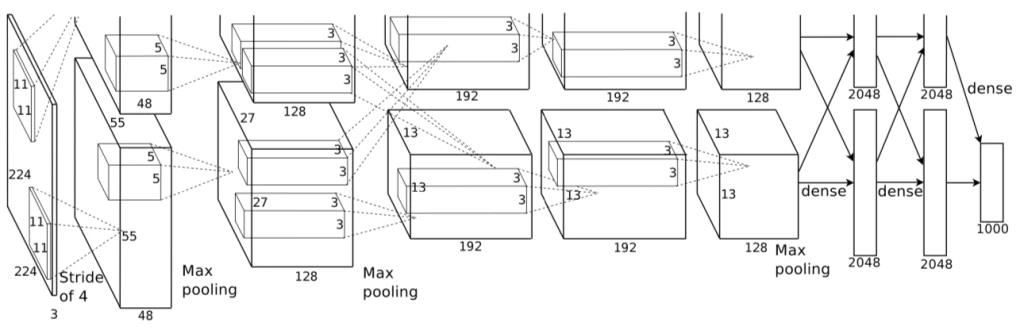
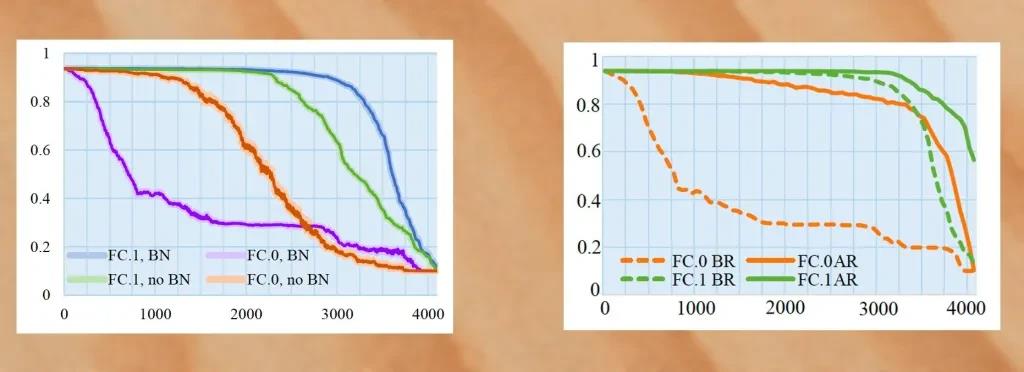
在用批量标准化(Batch Normalization,一种先分组标准化训练样本,再进入深度模型训练的技术)训练 AlexNet 时,研究者们成功将 26.8 M 的恶意软件嵌入到了模型之中,并同时确保了其与正常模型预测的准确率相差不超过 1%。但如果增加恶意软件的数据量,准确率将大幅下降。
下一步的实验是重新训练感染后模型。通过冻结受感染神经元避免其在额外训练周期中被修改,再加上批量标准化和再训练,研究人员成功将恶意病毒的数据量提升至 36.9MB,并同时保证了模型的准确率在 90% 以上。
研究中实验用的八个样本病毒都是可以被线上病毒扫描网站 VirusTotal 识别为恶意软件的,一旦样本成功嵌入神经网络,研究人员就会将模型上传至 VirusTotal 中进行扫描。而病毒扫描结果却显示这些模型“安全”,意味着恶意软件的伪装并未暴露。
研究人员又在其他几个 CNN 架构上进行了相同的测试, 包括 VGG、ResNet、Inception,以及 Mobilenet。实验结果类似,恶意软件都未被成功检测。这些隐匿的恶意软件将会是所有大型神经网络都需要面对的威胁。

保护机器学习管道
考虑到潜藏在深度学习模型中的恶意负载可以避过病毒扫描的检测,对抗 EvilModel 的唯一手段恐怕就只有直接销毁病毒本身了。
这类病毒只有在所有字节都完好无损才能保证感染成功。因此,如果收到 EvilModel 的受害者可以在不冻结受感染层的情况下重新训练模型,改变参数数值,便可让病毒数据直接被销毁。这样,即使只有一轮的训练也足以摧毁任何隐藏在深度学习模型中的恶意病毒。
但是,大多数开发人员都按原样使用预训练模型,除非他们想要针对其他应用做更细致的调整。而很多的细调都会冻结网络中绝大多数的层,这些层里很大可能包含了受感染的那些。
这就意味着,除了对抗攻击,数据中毒、成员推理等其他已知的安全问题之外,受恶意软件感染的神经网络也将成为深度学习的未来中真正的威胁之一。
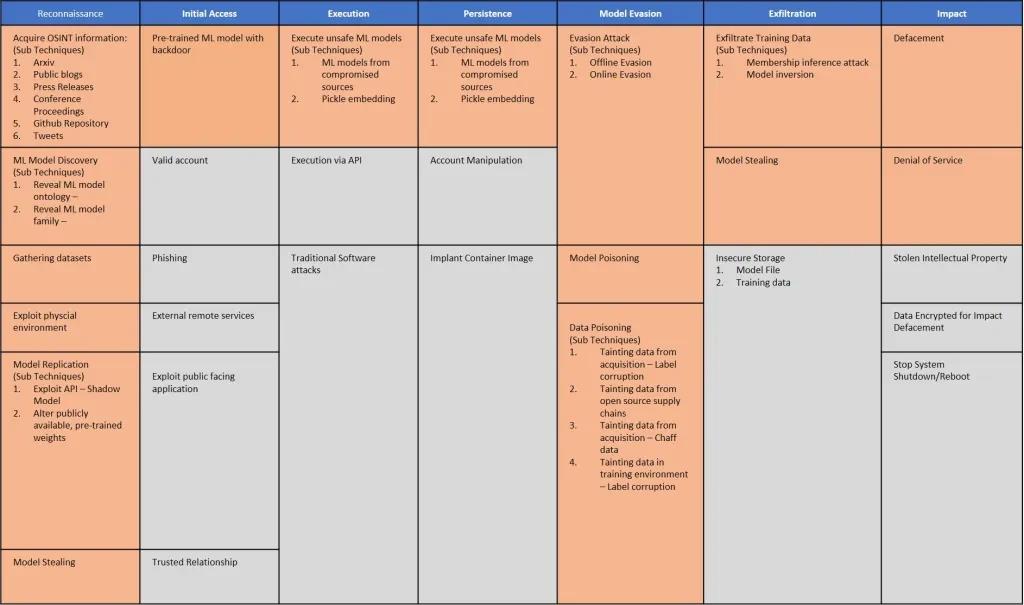
机器学习模型与经典的、基于规则的软件之间的差别意味着我们需要新的方法来应对安全威胁。2021 年上半年的时候,不少组织都提出了对抗性机器学习威胁矩阵,一个可协助开发者们发现机器学习管道弱点并修补安全漏洞的框架。
虽然威胁矩阵更侧重于对抗性攻击,但其所提出的方法也适用于 EvilModels 等威胁。在研究人员找到更可靠的手段来检测并阻止深度学习网络中的恶意软件之前,我们必须确立机器学习管道中的信任链。既然病毒扫描和其他静态分析工具无法检测到受感染模型,开发者们必须确保他们所使用的模型是来自可信任的渠道,并且训练数据和学习参数未受到损害。
随着我们在深度学习安全问题方面更深一步的研究,我们也必须对那些用于分析图片或识别语音的、数量庞杂的数据背后所隐藏的东西保持警惕。
参考链接:
https://bdtechtalks.com/2021/12/09/evilmodel-neural-networks-malware


往
期
回
顾
资讯
技术
技术
资讯

分享

点收藏

点点赞

点在看
以上是关于安全隐患:神经网络可以隐藏恶意软件的主要内容,如果未能解决你的问题,请参考以下文章