HashMap 内部原理
Posted LeBron_Six
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap 内部原理相关的知识,希望对你有一定的参考价值。
HashMap 内部实现
通过名字便可知道的是,HashMap 的原理就是散列。HashMap内部维护一个 Buckets 数组,每个 Bucket 封装为一个 Entry<K, V> 键值对形式的链表结构,这个 Buckets 数组也称为表。表的索引是 密钥K 的散列值(散列码)。如下图所示:
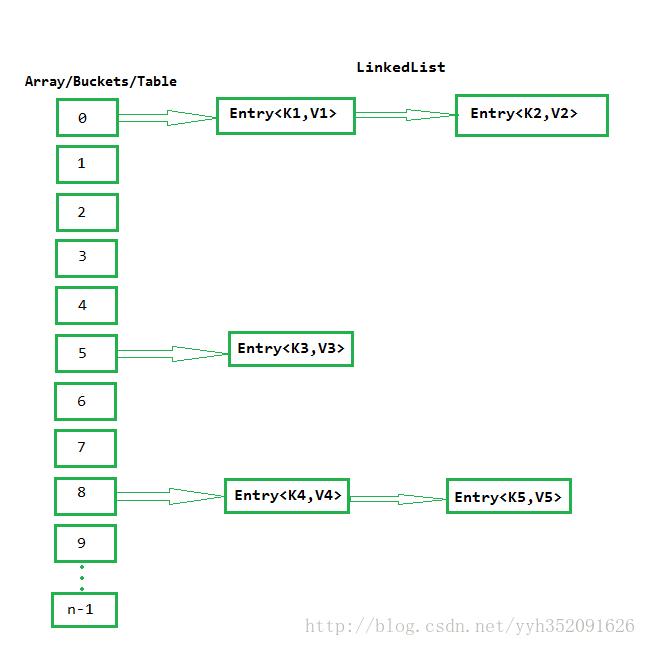
链表的每个节点是一个名为 Entry<K,V> 的类的实例。 Entry 类实现了 Map.Entry 接口,下面是Entry类的代码:
private static class Entry<K,V> implements Map.Entry<K,V>
final K key;
final int hash;
V value;
Entry<K,V> next;
注: 每个 Entry 对象仅与一个特定 key 相关联,但其 value 是可以改变的(如果相同的 key 之后被重新插入不同的 value) - 因此键是最终的,而值不是。 每个Entry对象都有一个名为 next 的字段,它指向下一个Entry,所以实际上为单链表结构。hash 字段存储了 Entry 对象在 Buckets 数组索引,也就是 key 的散列值。
如果发生Hash碰撞,也就是两个key的hash值相同,或者如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最早加入的放在链尾。
影响 HashMap 性能的两个因素是初始容量和负载因子。容量是表数组的长度,初始容量只是创建哈希表时的容量。负载因子是衡量哈希表在容量自动增加之前是否允许获取的量度(比例)。
当散列表中的 Entry 数量超过负载因子和当前容量的乘积时,将会重新散列该表(也就是重建内部数据结构),使得散列表具有大约两倍的容量(这个其实和ArrayList类似)。
理解 put() 方法
public V put(K key, V value)
if (table == EMPTY_TABLE)
inflateTable(threshold);
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key); // 计算hash值
int i = indexFor(hash, table.length); // 计算在数组中的索引
// 遍历链表
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next)
Object k;
// hash值相同并且key相等,就直接替换
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
modCount++;
addEntry(hash, key, value, i); // 否则就添加到链表
return null;
注:这个计算出来的hash值被传递给内部哈希函数,哈希函数将返回密钥的散列值。这个值就是 bucket/数组 的索i引。
static int indexFor(int h, int length)
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
这里就有个疑问了,我们如何计算对应存储数组索引,首先想到的就是把hashcode对数组长度取模运算,也就是h%length,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,能不能找一种更快速,消耗更小的方式那中?
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。
如下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
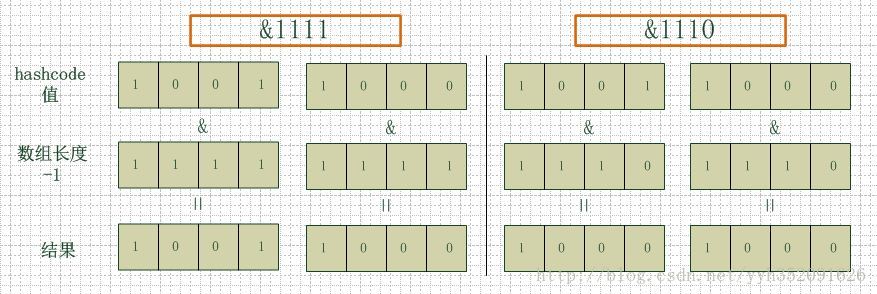
上图参考自:http://blog.csdn.net/oqqYeYi/article/details/39831029
理解 get() 方法
public V get(Object key)
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
final Entry<K,V> getEntry(Object key)
if (size == 0)
return null;
int hash = (key == null) ? 0 : sun.misc.Hashing.singleWordWangJenkinsHash(key); // 计算hash值
// 根据索引遍历链表,找出相等的key
for (HashMapEntry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next)
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
return null;
get 与 put 总结
下面总结了 put() 和 get() 发生的三个重要步骤:
- 通过调用 计算 Hash Code 方法计算密钥的哈希码。
- 将计算的散列码传递到内部散列函数
indexFor()以获取表的索引。 - 迭代通过在索引处出现的链表,并调用
equals()方法来查找匹配键。
所以在这之前要先理解 equals() 和 hashCode() 这两个方法。
在 Java8 中的改善
在Java 8中,对HashMap有一个性能上的改进。当密钥中存在许多哈希冲突(不同的密钥最终具有相同的哈希值或索引)时,平衡树将用于存储 Entry 对象,而不是链表。做法是,一旦 bucket 中的 Entry 数量增长超过某一阈值,则 bucket 将从 Entry 链表切换到平衡树。
以上是关于HashMap 内部原理的主要内容,如果未能解决你的问题,请参考以下文章