python绘制混淆矩阵(2s-AGCN结果分析)
Posted BIZZARRE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python绘制混淆矩阵(2s-AGCN结果分析)相关的知识,希望对你有一定的参考价值。
1.运行2s-AGCN
双流自适应图卷积网络有现成的开源代码,使用NTU-RGB D数据集进行训练,本文采用的是batch_size=32,epoch=15进行简单的复现,使用15次的权重时,bone网络的准确率是84.57%,joint网络的准确率是83.83%,融合准确率是89.9%。运行权重测试后,在work_dir/ntu/xview/agcn_test_joint(agcn_test_bone)中会分别出现一个运行结果,名为epoch1_test_score.pkl,即为分类器的打分结果。
2.分析打分结果
在ensemble.py中,可以读取pkl中的信息,代码段如下:
dataset = arg.datasets
label = open('./data/' + dataset + '/val_label.pkl', 'rb')
label = np.array(pickle.load(label))
r1 = open('./work_dir/' + dataset + '/agcn_test_joint/epoch1_test_score.pkl', 'rb')
r1 = list(pickle.load(r1).items())
r2 = open('./work_dir/' + dataset + '/agcn_test_bone/epoch1_test_score.pkl', 'rb')
r2 = list(pickle.load(r2).items()) 其中,r1和r2就是打分结果,进一步Debug可以发现epoch1_test_score.pkl中的打分结果是元组形式,具体如下图: 
测试数据一共是10552个,label是一个2*10552的数组,第一行存放样本名称,第二行是分类编号,而测试结果r1和r2是一个10552*2的元组,每一行代表一个样本,第一列是名称,第二列是存放60个得分的数组,所以不能直接用sklearn.metrics来绘制混淆矩阵,需要把对应的标签给提取出来。
3.数据处理
sklearn.metrics中有 confusion_matrix(y_label, y_predict) 函数,要求是 y_label 和 y_predict必须形如 [ '1' '2'.......'3'],首先y_label很简单,直接提取第二段label中的第二行数据;y_predict主要是两步操作,保留原代码ensembl.py的部分直到for循环,原部分为:
for i in tqdm(range(len(label[0]))):
_, l = label[:, i]
_, r11 = r1[i]
_, r22 = r2[i]
r = r11 + r22 * arg.alpha
rank_5 = r.argsort()[-5:]
right_num_5 += int(int(l) in rank_5)
r = np.argmax(r) #提取最高得分的标签
right_num += int(r == int(l))
total_num += 1只要把每一个样本的最高得分写入到自定义的y_predict数组中,就可以得到一个int类型的数组,保存每一个样本的top1标签(顺序与label的数据一样),第二步就是把int元素转化为str格式,就可以了,最终代码修改为(ensemble.py同级下新建):
import argparse
import pickle
from sklearn.metrics import confusion_matrix
import numpy as np
from tqdm import tqdm
parser = argparse.ArgumentParser()
parser.add_argument('--datasets', default='ntu/xview', choices='kinetics', 'ntu/xsub', 'ntu/xview',
help='the work folder for storing results')
parser.add_argument('--alpha', default=1, help='weighted summation')
arg = parser.parse_args()
dataset = arg.datasets
label = open('./data/' + dataset + '/val_label.pkl', 'rb')
label = np.array(pickle.load(label))
r1 = open('./work_dir/' + dataset + '/agcn_test_joint/epoch1_test_score.pkl', 'rb')
r1 = list(pickle.load(r1).items())
r2 = open('./work_dir/' + dataset + '/agcn_test_bone/epoch1_test_score.pkl', 'rb')
r2 = list(pickle.load(r2).items())
y_label = label[1]
y_predict = []
for i in tqdm(range(len(label[0]))):
_, l = label[:, i]
_, r11 = r1[i]
_, r22 = r2[i]
r = r11 + r22 * arg.alpha
r = np.argmax(r)
y_predict.append(r) #保留每一个样本的得分最高结果
y_predict_new = [str(x) for x in y_predict] #将int转为str
C = confusion_matrix(y_label, y_predict_new) #C为混淆矩阵
for i in range(0,60): #对角线元素属于正确分类,不重要,归0
for j in range (0,60):
if(i == j):
C[i][j] = 0
''''
data = pd.DataFrame(C)
writer = pd.ExcelWriter('B.xlsx') # 写入Excel文件
data.to_excel(writer, 'sheet_2', float_format='%.5f') # ‘sheet_2’是写入excel的sheet名
writer.save()
writer.close()
'''注释部分是把混淆矩阵C写入EXCEL,其实一开始尝试过plt.show,但是该混淆矩阵为60*60的数字矩阵,该方法绘制出来的图看不清楚,也没有想到很好的办法解决,所以直接用excel处理。
最终部分结果如下图:
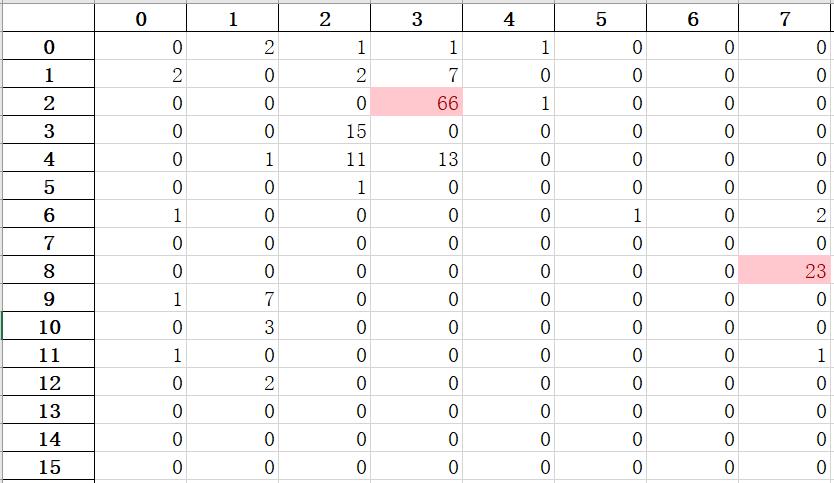
发现对于A4 brush hair这一动作,误判率非常之高,下一阶段值得继续研究成因,也欢迎大家讨论。
PS:打分结果部分,每个样本有负数和大于1的正数,明显不是softmax分类器,与论文中不符,不影响结果,但是不知道什么原因,等进一步看过代码再讨论。
PPS:算是刚入门行为识别,摸黑前进,大数据集也很难做,很多基础知识等着补,欢迎大家一起讨论,也欢迎大佬指点。
以上是关于python绘制混淆矩阵(2s-AGCN结果分析)的主要内容,如果未能解决你的问题,请参考以下文章
Python遥感图像处理应用篇(二十八):Python绘制遥感图像分类结果混淆矩阵和计算分类精度