正则表达式高阶技巧之环视的组合(使用python实现)
Posted 温柔且上进c
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式高阶技巧之环视的组合(使用python实现)相关的知识,希望对你有一定的参考价值。
环视的组合
介绍
在我们日常使用的编程语言都是支持环视的,但是语言不同,支持程度也就不同,下面具体介绍一下在python中的支持:
- 一般来说,所有语言都是支持环视的,而且是没有限制。也就是说,无论你是使用肯定顺序环视,还是否定顺序环视,都可以在结构中使用各种复杂的表达式
- 但是在python中规定:逆序环视中的表达式能匹配的文本长度必须是固定的,也就是说,
(?<=cat)是合法的,(?<=(cat|dog))也是合法的,因为环视中的子表达式能匹配的文本都是固定的; 而((?<=(cats|dog)))与(?<=dogs?)则都是不合法的,因为环视的子表达式能匹配的文本长度是不确定的 - 要解决上诉问题:可以使用多选结构来改造表达式,比如,
cats?等价于(dog|dogs),所以可以将上述的环视结构改写为((?<=cat)|(?<=cats)),同样是,((?<=(cats|dog)))也可以修改为((?<=cats)|(?<=dog));但是上述的方法的应用场景是非常有限的,如果逆序环视的表达式较为复杂,使用多选结构列出就略显不便;而且一旦表达式中出现了*和+这类的量词,就不能再使用多选结构列出了
环视的组合
- 环视匹配的并不是字符,而是位置。在正则表达式匹配时,表示环视结构匹配成功,并不会更改“当前的位置”,所以多个还是可以组合在一起,实现在同一位置的多种判断
环视中包含环视
- 如我们在匹配主机名时,限定了主机长度不能超过255个字符,使用表达式
(?=[-a-zA-Z0-9.]0,255(?![-a-zA-Z0-9.]))。其中的(?![-a-zA-Z0-9.])是包含在外层的环视中的,它要求在这个位置(也就是正确的主机名字符串之后),不能再出现属于主机名字符串的字符,也就是保证之前的表达式匹配的是整个主机名字符串,而不是“可能的主机名字符串的一部分”;综合起来,(?=[-a-zA-Z0-9.]0,255(?![-a-zA-Z0-9.]))保证的是“整个主机名字字符串的长度为255字符以内”,逻辑如下图:

并列多个环视
- 并列多个环视,他要求在当前位置,所有的环视判断都必须成功。比如:要知道一个这样的位置,它之后必须是一个数字字符串,但是不能是以999开头的数字字符串。这个时候就必须并列这两个环视
- 表示数字字符串的表达式为
\\d+,对应的环视结构为(?=\\d+);表示“不能以999开头”的表达式的环视结构为(?!999)。我们要做的是将两个环视结构并列起来,得到(?=\\d+)(?!999)。因为环视结构不会更改当前位置,所以先后顺序没有影响,无论是(?=\\d+)(?!999)还是(?!999)(?=\\d+),效果是相同的,都是必须要求两个环视条件必须同时满足 - 在当前位置,之后必须出现数字字符串;在当前位置,之后不能是出现999,最终的结果是两个环视做“与(and)”运算,就是说,两个条件必须同时满足才能进行匹配成功,否则失败,如下测试:
import re
# 查找这样的起始位置:它之后必须是数字字符串,且不能以999开头
# 数字字符串
re.search(r"^(?=\\d+)(?!999)", '123456') is not None
# 非数字字符串
re.search(r"^(?=\\d+)(?!999)", 'wywy') is not None
# 数字字符串但是以999开头
re.search(r"^(?=\\d+)(?!999)", '999123456') is not None

逻辑如下图:
注意:
- 仔细观察上述
(!?999)这个环视结构会发现,字符串99999的开始位置也是不能匹配的,这是因为(!?999)不允许出现的其实是字符串999,而不是数值999,如果要更加准确的表示数值999,应该使用(!?999)(?!\\d)这个环视
环视作为多选分支排列在多选结构中
- 最后常见的环视结构就是将若干环视作为多选分支排列在多选结构中(或(or))。如要找到这样的一个位置:它之后要么不是数字字符,要么是一个数字字符和一个非数字字符(比如3w)。“不是数字字符”对应的环视为
(?!\\d);而“一个数字字符和一个非数字字符”对应的环视为(?=\\d\\D),所以最终组合后的环视为(?!\\d)|(?=\\d\\D)。虽然我们在上面我们也探讨过并列多个环视组合,但是在多选结构中列出多个环视结构的意义与上面不太一样。使用多选环视结构,列出的多个环视只要有一个成立,整个判断都是成功的;不使用多选结构时,所有列出的环视都必须成立,整个判断才能成功,如下测试:
import re
# 查找这样的起始位置:它之后要么不是数字字符,要么是一个数字字符和一个非数字字符
# 不是数字字符
re.search(r"^((?!\\d)|(?=\\d\\D))","ab") is not None
# 一个数字字符与一个非数字字符
re.search(r"^((?!\\d)|(?=\\d\\D))","3w") is not None
# 单个数字字符
re.search(r"^((?!\\d)|(?=\\d\\D))","6") is not None
# 连续的数字字符
re.search(r"^((?!\\d)|(?=\\d\\D))","6666") is not None

逻辑如下图:

断言与反向引用之间的关系
- 断言不匹配任何字符,只匹配位置;而反向引用只引用之前的捕获分组匹配的文本,之前捕获分组中锚点表示的文职信息,在反向引用时并不会保留下来
- 举例来说,如果正则表达式为
(\\bcat\\b)\\s\\1,\\1所匹配的,就不只有单独出现的cat,还有包括在单词内部的cat,比如(category中的cat),如果要验证单词cat是否在字符串中出现了两次,正确的做法是在反向引用的两端也加上单词边界\\b,变成(\\bcat\\b.*?\\b\\1\\b),如下举例:
import re
# 未加单词边界\\b
re.search(r"(\\bcat\\b)\\s+\\1", 'cat category') is not None
# 加单词边界\\b
re.search(r"(\\bcat\\b)\\s+\\b\\1\\b", 'cat category') is not None
# 加单词边界\\b
re.search(r"(\\bcat\\b)\\s+\\b\\1\\b", 'cat cat') is not None
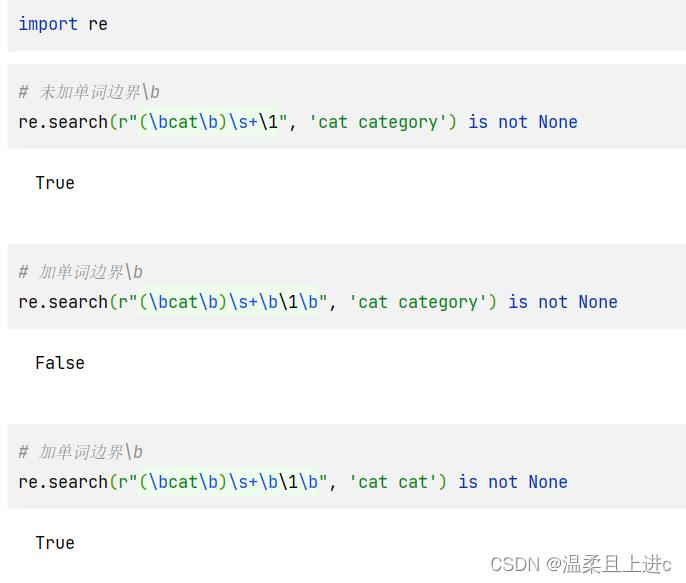
- 在后续使用正则中一定要注意:使用
(\\bcat\\b)\\s+\\1来匹配“重复的单词”是不对的,应该使用(\\bcat\\b)\\s+\\b\\1\\b
以上是关于正则表达式高阶技巧之环视的组合(使用python实现)的主要内容,如果未能解决你的问题,请参考以下文章